C++ 文件和流
- 到目前为止,目前使用最为广泛的是 iostream 标准库,它提供了 cin 和 cout 方法分别用于从标准输入读取流和向标准输出写入流。
- 以下将介绍从文件读取流和向文件写入流。这就需要用到 C++ 中另一个标准库 fstream,它定义了三个新的数据类型:
| 数据类型 | 描述 |
|---|---|
| ofstream | 该数据类型表示输出文件流,用于创建文件并向文件写入信息。 |
| ifstream | 该数据类型表示输入文件流,用于从文件读取信息。 |
| fstream | 该数据类型通常表示文件流,且同时具有 ofstream 和 ifstream 两种功能,这意味着它可以创建文件,向文件写入信息,从文件读取信息。 |
- 源代码文件中包含头文件 <iostream> 和 <fstream>
打开文件
- 在从文件读取信息或者向文件写入信息之前,必须先打开文件。ofstream 和 fstream 对象都可以用来打开文件进行写操作,如果只需要打开文件进行读操作,则使用 ifstream 对象。
- 下面是 open() 函数的标准语法,open() 函数是 fstream、ifstream 和 ofstream 对象的一个成员。
void open(const char *filename, ios::openmode mode);
-
在这里,open() 成员函数的第一参数指定要打开的文件的名称和位置,第二个参数定义文件被打开的模式。
| 模式标志 | 描述 |
|---|---|
| ios::app | 追加模式。所有写入都追加到文件末尾。 |
| ios::ate | 文件打开后定位到文件末尾。 |
| ios::in | 打开文件用于读取。 |
| ios::out | 打开文件用于写入。 |
| ios::trunc | 如果该文件已经存在,其内容将在打开文件之前被截断,即把文件长度设为 0。 |
- 可以把以上两种或两种以上的模式结合使用。例如,如果想要以写入模式打开文件,并希望截断文件,以防文件已存在,那么可以使用下面的语法:
ofstream outfile;
outfile.open("file.dat", ios::out | ios::trunc );- 类似地,如果想要打开一个文件用于读写,可以使用下面的语法:
ifstream afile;
afile.open("file.dat", ios::out | ios::in );
关闭文件
- 当 C++ 程序终止时,它会自动关闭刷新所有流,释放所有分配的内存,并关闭所有打开的文件。但程序员应该养成一个好习惯,在程序终止前关闭所有打开的文件。
- 下面是 close() 函数的标准语法,close() 函数是 fstream、ifstream 和 ofstream 对象的一个成员。
void close();
写入文件
- 在 C++ 编程中,使用流插入运算符( << )向文件写入信息,就像使用该运算符输出信息到屏幕上一样。唯一不同的是,在这里使用的是 ofstream 或 fstream 对象,而不是 cout 对象。
读取文件
- 在 C++ 编程中,使用流提取运算符( >> )从文件读取信息,就像使用该运算符从键盘输入信息一样。唯一不同的是,在这里使用的是 ifstream 或 fstream 对象,而不是 cin 对象。
读取 & 写入实例
- 下面的 C++ 程序以读写模式打开一个文件。在向文件 afile.dat 写入用户输入的信息之后,程序从文件读取信息,并将其输出到屏幕上
#include <fstream>
#include <iostream>
using namespace std;int main ()
{char data[100];// 以写模式打开文件ofstream outfile;outfile.open("afile.dat");cout << "Writing to the file" << endl;cout << "Enter your name: "; cin.getline(data, 100);// 向文件写入用户输入的数据outfile << data << endl;cout << "Enter your age: "; cin >> data;cin.ignore();// 再次向文件写入用户输入的数据outfile << data << endl;// 关闭打开的文件outfile.close();// 以读模式打开文件ifstream infile; infile.open("afile.dat"); cout << "Reading from the file" << endl; infile >> data; // 在屏幕上写入数据cout << data << endl;// 再次从文件读取数据,并显示它infile >> data; cout << data << endl; // 关闭打开的文件infile.close();return 0;
}- cin 对象的附加函数,比如 getline()函数从外部读取一行,ignore() 函数会忽略掉之前读语句留下的多余字符
文件位置指针
- istream 和 ostream 都提供了用于重新定位文件位置指针的成员函数。这些成员函数包括关于 istream 的 seekg("seek get")和关于 ostream 的 seekp("seek put")。
- seekg 和 seekp 的参数通常是一个长整型。第二个参数可以用于指定查找方向。查找方向可以是 ios::beg(默认的,从流的开头开始定位),也可以是 ios::cur(从流的当前位置开始定位),也可以是 ios::end(从流的末尾开始定位)。
- 文件位置指针是一个整数值,指定了从文件的起始位置到指针所在位置的字节数。下面是关于定位 "get" 文件位置指针的实例:
// 定位到 fileObject 的第 n 个字节(假设是 ios::beg)
fileObject.seekg( n );// 把文件的读指针从 fileObject 当前位置向后移 n 个字节
fileObject.seekg( n, ios::cur );// 把文件的读指针从 fileObject 末尾往回移 n 个字节
fileObject.seekg( n, ios::end );// 定位到 fileObject 的末尾
fileObject.seekg( 0, ios::end );C++ 异常处理
异常是程序在执行期间产生的问题。C++ 异常是指在程序运行时发生的特殊情况,比如尝试除以零的操作。异常提供了一种转移程序控制权的方式。C++ 异常处理涉及到三个关键字:try、catch、throw。
- throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
- catch: 在您想要处理问题的地方,通过异常处理程序捕获异常。catch 关键字用于捕获异常。
- try: try 块中的代码标识将被激活的特定异常。它后面通常跟着一个或多个 catch 块。
如果有一个块抛出一个异常,捕获异常的方法会使用 try 和 catch 关键字。try 块中放置可能抛出异常的代码,try 块中的代码被称为保护代码。使用 try/catch 语句的语法如下所示:
try
{// 保护代码
}catch( ExceptionName e1 )
{// catch 块
}catch( ExceptionName e2 )
{// catch 块
}catch( ExceptionName eN )
{// catch 块
}
- 如果 try 块在不同的情境下会抛出不同的异常,这个时候可以尝试罗列多个 catch 语句,用于捕获不同类型的异常。
抛出异常
- 可以使用 throw 语句在代码块中的任何地方抛出异常。throw 语句的操作数可以是任意的表达式,表达式的结果的类型决定了抛出的异常的类型。
double division(int a, int b)
{if( b == 0 ){throw "Division by zero condition!";}return (a/b);
}
捕获异常
catch 块跟在 try 块后面,用于捕获异常。您可以指定想要捕捉的异常类型,这是由 catch 关键字后的括号内的异常声明决定的。
try
{// 保护代码
}catch( ExceptionName e )
{// 处理 ExceptionName 异常的代码
}- 上面的代码会捕获一个类型为 ExceptionName 的异常。如果您想让 catch 块能够处理 try 块抛出的任何类型的异常,则必须在异常声明的括号内使用省略号 ...,如下所示:
try
{// 保护代码
}catch(...)
{// 能处理任何异常的代码
}- 由于抛出了一个类型为 const char* 的异常,因此,当捕获该异常时,必须在 catch 块中使用 const char*。当上面的代码被编译和执行时,它会产生下列结果:
Division by zero condition!C++ 标准的异常
- C++ 提供了一系列标准的异常,定义在 <exception> 中,可以在程序中使用这些标准的异常。它们是以父子类层次结构组织起来的,如下所示:
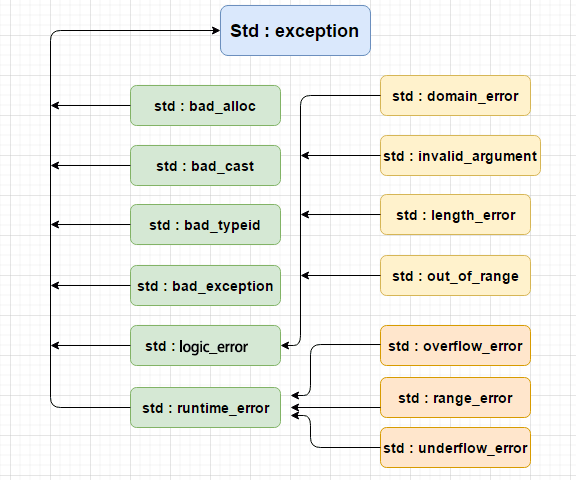
| 异常 | 描述 |
|---|---|
| std::exception | 该异常是所有标准 C++ 异常的父类。 |
| std::bad_alloc | 该异常可以通过 new 抛出。 |
| std::bad_cast | 该异常可以通过 dynamic_cast 抛出。 |
| std::bad_exception | 这在处理 C++ 程序中无法预期的异常时非常有用。 |
| std::bad_typeid | 该异常可以通过 typeid 抛出。 |
| std::logic_error | 理论上可以通过读取代码来检测到的异常。 |
| std::domain_error | 当使用了一个无效的数学域时,会抛出该异常。 |
| std::invalid_argument | 当使用了无效的参数时,会抛出该异常。 |
| std::length_error | 当创建了太长的 std::string 时,会抛出该异常。 |
| std::out_of_range | 该异常可以通过方法抛出,例如 std::vector 和 std::bitset<>::operator[]()。 |
| std::runtime_error | 理论上不可以通过读取代码来检测到的异常。 |
| std::overflow_error | 当发生数学上溢时,会抛出该异常。 |
| std::range_error | 当尝试存储超出范围的值时,会抛出该异常。 |
| std::underflow_error | 当发生数学下溢时,会抛出该异常。 |
定义新的异常
- 可以通过继承和重载 exception 类来定义新的异常。下面的实例演示了如何使用 std::exception 类来实现自己的异常:
#include <iostream>
#include <exception>
using namespace std;struct MyException : public exception
{const char * what () const throw (){return "C++ Exception";}
};int main()
{try{throw MyException();}catch(MyException& e){std::cout << "MyException caught" << std::endl;std::cout << e.what() << std::endl;}catch(std::exception& e){//其他的错误}
}- what() 是异常类提供的一个公共方法,它已被所有子异常类重载。这将返回异常产生的原因。
C++ 动态内存
了解动态内存在 C++ 中是如何工作的是成为一名合格的 C++ 程序员必不可少的。C++ 程序中的内存分为两个部分:
- 栈:在函数内部声明的所有变量都将占用栈内存。
- 堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存。
很多时候,无法提前预知需要多少内存来存储某个定义变量中的特定信息,所需内存的大小需要在运行时才能确定。在 C++ 中,可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址。这种运算符即 new 运算符。如果不再需要动态分配内存空间,可以使用 delete 运算符,删除之前由 new 运算符分配的内存。
new 和 delete 运算符
下面是使用 new 运算符来为任意的数据类型动态分配内存的通用语法:
new data-type;
- 在这里,data-type 可以是包括数组在内的任意内置的数据类型,也可以是包括类或结构在内的用户自定义的任何数据类型。如果使用内置的数据类型,例如,可以定义一个指向 double 类型的指针,然后请求内存,该内存在执行时被分配。我们可以按照下面的语句使用 new 运算符来完成这点:
double* pvalue = NULL; // 初始化为 null 的指针
pvalue = new double; // 为变量请求内存- 如果自由存储区已被用完,可能无法成功分配内存。所以建议检查 new 运算符是否返回 NULL 指针,并采取以下适当的操作:
double* pvalue = NULL;
if( !(pvalue = new double ))
{cout << "Error: out of memory." <<endl;exit(1);}
- malloc() 函数在 C 语言中就出现了,在 C++ 中仍然存在,但建议尽量不要使用 malloc() 函数。new 与 malloc() 函数相比,其主要的优点是,new 不只是分配了内存,它还创建了对象。
- 在任何时候,当某个已经动态分配内存的变量不再需要使用时,可以使用 delete 操作符释放它所占用的内存,如下所示:
delete pvalue; // 释放 pvalue 所指向的内存
#include <iostream>
using namespace std;int main ()
{double* pvalue = NULL; // 初始化为 null 的指针pvalue = new double; // 为变量请求内存*pvalue = 29494.99; // 在分配的地址存储值cout << "Value of pvalue : " << *pvalue << endl;delete pvalue; // 释放内存return 0;
}数组的动态内存分配
- 假设要为一个字符数组(一个有 20 个字符的字符串)分配内存,可以使用上面实例中的语法来为数组动态地分配内存,如下所示:
char* pvalue = NULL; // 初始化为 null 的指针
pvalue = new char[20]; // 为变量请求内存- 要删除刚才创建的数组,语句如下:
delete [] pvalue; // 删除 pvalue 所指向的数组
下面是 new 操作符的通用语法,可以为多维数组分配内存
一维数组
// 动态分配,数组长度为 m
int *array=new int [m];//释放内存
delete [] array;二维数组
int **array
// 假定数组第一维长度为 m, 第二维长度为 n
// 动态分配空间
array = new int *[m];
for( int i=0; i<m; i++ )
{array[i] = new int [n] ;
}
//释放
for( int i=0; i<m; i++ )
{delete [] array[i];
}
delete [] array;二维数组例子
#include <iostream>
using namespace std;int main()
{int **p; int i,j; //p[4][8] //开始分配4行8列的二维数据 p = new int *[4];for(i=0;i<4;i++){p[i]=new int [8];}for(i=0; i<4; i++){for(j=0; j<8; j++){p[i][j] = j*i;}} //打印数据 for(i=0; i<4; i++){for(j=0; j<8; j++) { if(j==0) cout<<endl; cout<<p[i][j]<<"\t"; }} //开始释放申请的堆 for(i=0; i<4; i++){delete [] p[i]; }delete [] p; return 0;
}三维数组
int ***array;
// 假定数组第一维为 m, 第二维为 n, 第三维为h
// 动态分配空间
array = new int **[m];
for( int i=0; i<m; i++ )
{array[i] = new int *[n];for( int j=0; j<n; j++ ){array[i][j] = new int [h];}
}
//释放
for( int i=0; i<m; i++ )
{for( int j=0; j<n; j++ ){delete[] array[i][j];}delete[] array[i];
}
delete[] array;三维数组例子
#include <iostream>
using namespace std;int main()
{ int i,j,k; // p[2][3][4]int ***p;p = new int **[2]; for(i=0; i<2; i++) { p[i]=new int *[3]; for(j=0; j<3; j++) p[i][j]=new int[4]; }//输出 p[i][j][k] 三维数据for(i=0; i<2; i++) {for(j=0; j<3; j++) { for(k=0;k<4;k++){ p[i][j][k]=i+j+k;cout<<p[i][j][k]<<" ";}cout<<endl;}cout<<endl;}// 释放内存for(i=0; i<2; i++) {for(j=0; j<3; j++) { delete [] p[i][j]; } } for(i=0; i<2; i++) { delete [] p[i]; } delete [] p; return 0;
}
对象的动态内存分配
- 对象与简单的数据类型没有什么不同
#include <iostream>
using namespace std;class Box
{public:Box() { cout << "调用构造函数!" <<endl; }~Box() { cout << "调用析构函数!" <<endl; }
};int main( )
{Box* myBoxArray = new Box[4];delete [] myBoxArray; // 删除数组return 0;
}- 如果要为一个包含四个 Box 对象的数组分配内存,构造函数将被调用 4 次,同样地,当删除这些对象时,析构函数也将被调用相同的次数(4次)。
- 当上面的代码被编译和执行时,它会产生下列结果:
调用构造函数!
调用构造函数!
调用构造函数!
调用构造函数!
调用析构函数!
调用析构函数!
调用析构函数!
调用析构函数!C++ 命名空间
- 假设这样一种情况,当一个班上有两个名叫 Zara 的学生时,为了明确区分它们,我们在使用名字之外,不得不使用一些额外的信息,比如他们的家庭住址,或者他们父母的名字等等。
- 同样的情况也出现在 C++ 应用程序中。例如,您可能会写一个名为 xyz() 的函数,在另一个可用的库中也存在一个相同的函数 xyz()。这样,编译器就无法判断您所使用的是哪一个 xyz() 函数。
- 因此,引入了命名空间这个概念,专门用于解决上面的问题,它可作为附加信息来区分不同库中相同名称的函数、类、变量等。使用了命名空间即定义了上下文。本质上,命名空间就是定义了一个范围。
- 以一个计算机系统中的例子,一个文件夹(目录)中可以包含多个文件夹,每个文件夹中不能有相同的文件名,但不同文件夹中的文件可以重名。
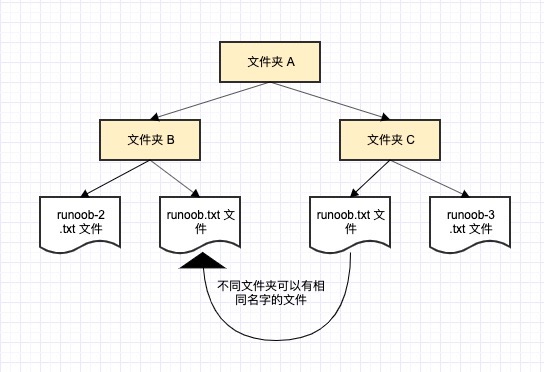
定义命名空间
- 命名空间的定义使用关键字 namespace,后跟命名空间的名称,如下所示:
namespace namespace_name {// 代码声明
}- 为了调用带有命名空间的函数或变量,需要在前面加上命名空间的名称,如下所示:
name::code; // code 可以是变量或函数
例子
#include <iostream>
using namespace std;// 第一个命名空间
namespace first_space{void func(){cout << "Inside first_space" << endl;}
}
// 第二个命名空间
namespace second_space{void func(){cout << "Inside second_space" << endl;}
}
int main ()
{// 调用第一个命名空间中的函数first_space::func();// 调用第二个命名空间中的函数second_space::func(); return 0;
}using指令
- 可以使用 using namespace 指令,这样在使用命名空间时就可以不用在前面加上命名空间的名称。这个指令会告诉编译器,后续的代码将使用指定的命名空间中的名称。
#include <iostream>
using namespace std;// 第一个命名空间
namespace first_space{void func(){cout << "Inside first_space" << endl;}
}
// 第二个命名空间
namespace second_space{void func(){cout << "Inside second_space" << endl;}
}
using namespace first_space;
int main ()
{// 调用第一个命名空间中的函数func();return 0;
}- using 指令也可以用来指定命名空间中的特定项目。例如,如果您只打算使用 std 命名空间中的 cout 部分,您可以使用如下的语句:
using std::cout;
- using 指令引入的名称遵循正常的范围规则。名称从使用 using 指令开始是可见的,直到该范围结束。此时,在范围以外定义的同名实体是隐藏的。
不连续的命名空间
- 命名空间可以定义在几个不同的部分中,因此命名空间是由几个单独定义的部分组成的。一个命名空间的各个组成部分可以分散在多个文件中。
- 所以,如果命名空间中的某个组成部分需要请求定义在另一个文件中的名称,则仍然需要声明该名称。下面的命名空间定义可以是定义一个新的命名空间,也可以是为已有的命名空间增加新的元素:
namespace namespace_name {// 代码声明
}嵌套的命名空间
- 命名空间可以嵌套,您可以在一个命名空间中定义另一个命名空间,如下所示:
namespace namespace_name1 {// 代码声明namespace namespace_name2 {// 代码声明}
}-
可以通过使用 :: 运算符来访问嵌套的命名空间中的成员:
// 访问 namespace_name2 中的成员
using namespace namespace_name1::namespace_name2;// 访问 namespace:name1 中的成员
using namespace namespace_name1;- 在上面的语句中,如果使用的是 namespace_name1,那么在该范围内 namespace_name2 中的元素也是可用的,如下所示:
C++ 模板
- 模板是泛型编程的基础,泛型编程即以一种独立于任何特定类型的方式编写代码。
- 模板是创建泛型类或函数的蓝图或公式。库容器,比如迭代器和算法,都是泛型编程的例子,它们都使用了模板的概念。每个容器都有一个单一的定义,比如 向量,可以定义许多不同类型的向量,比如 vector <int> 或 vector <string>。
函数模板
template <typename type> ret-type func-name(parameter list)
{// 函数的主体
}-
在这里,type 是函数所使用的数据类型的占位符名称。这个名称可以在函数定义中使用。下面是函数模板的实例,返回两个数中的最大值:
#include <iostream>
#include <string>using namespace std;template <typename T>
inline T const& Max (T const& a, T const& b)
{ return a < b ? b:a;
}
int main ()
{int i = 39;int j = 20;cout << "Max(i, j): " << Max(i, j) << endl; double f1 = 13.5; double f2 = 20.7; cout << "Max(f1, f2): " << Max(f1, f2) << endl; string s1 = "Hello"; string s2 = "World"; cout << "Max(s1, s2): " << Max(s1, s2) << endl; return 0;
}类模板
- 正如定义函数模板一样,也可以定义类模板。泛型类声明的一般形式如下所示:
template <class type> class class-name {
.
.
.
}- 在这里,type 是占位符类型名称,可以在类被实例化的时候进行指定。可以使用一个逗号分隔的列表来定义多个泛型数据类型。下面的实例定义了类 Stack<>,并实现了泛型方法来对元素进行入栈出栈操作:
#include <iostream>
#include <vector>
#include <cstdlib>
#include <string>
#include <stdexcept>using namespace std;template <class T>
class Stack { private: vector<T> elems; // 元素 public: void push(T const&); // 入栈void pop(); // 出栈T top() const; // 返回栈顶元素bool empty() const{ // 如果为空则返回真。return elems.empty(); }
}; template <class T>
void Stack<T>::push (T const& elem)
{ // 追加传入元素的副本elems.push_back(elem);
} template <class T>
void Stack<T>::pop ()
{ if (elems.empty()) { throw out_of_range("Stack<>::pop(): empty stack"); }// 删除最后一个元素elems.pop_back();
} template <class T>
T Stack<T>::top () const
{ if (elems.empty()) { throw out_of_range("Stack<>::top(): empty stack"); }// 返回最后一个元素的副本 return elems.back();
} int main()
{ try { Stack<int> intStack; // int 类型的栈 Stack<string> stringStack; // string 类型的栈 // 操作 int 类型的栈 intStack.push(7); cout << intStack.top() <<endl; // 操作 string 类型的栈 stringStack.push("hello"); cout << stringStack.top() << std::endl; stringStack.pop(); stringStack.pop(); } catch (exception const& ex) { cerr << "Exception: " << ex.what() <<endl; return -1;}
}



















