这一篇分享的是CIKM2020微信的learning to build user-tag profile,主要介绍了微信看一看("Top Stories")中,如何进行用户-标签的兴趣建模,提升推荐效果。
1、背景
看一下微信看一看场景下的推荐流程:

它整个推荐系统主要有四部分:新闻画像层(news profile layer),用户画像层(user profile layer),召回层(recall layer)和排序层(rank layer)。
在新闻画像层,对新闻相关的特征如文章标签,类别等进行提取。在用户画像层,对用户的基本信息和行为信息进行建模。这里很重要的一个特征是用户标签。随后是召回层,有多种召回方式;最后是排序层,可以使用更复杂的模型对召回层得到的结果进行精确的排序,最后展示给用户。
因为用户画像和召回层、排序层的模型非常相关,所以有必要建立一个准确的用户画像。论文主要讲了对用户对文章标签的偏好的建模,提出了User Tag Profiling Model。
构建user-tag profile的时候,对每个user,会收集他阅读历史中点击过的新闻的标签,并在模型训练步骤中计算出用户对这些标签的偏好。在新闻推荐系统中,通常将点击过的新闻作为正样本,浏览过但是没有点击的新闻作为负样本。但是直接将这个方法用于标签,会使点击过的新闻的标签都是正样本,这是有问题的。因为用户点击新闻也许只是对其中一个标签感兴趣。
基于这些考虑,文章提出了两个问题:
RQ1: 如何自动选择有用的特征?并且学习到同一个field和不同field之间的特征的相互作用?
RQ2:怎么从用户点击过的新闻中学习到用户对不同标签的偏好?
2、论文主要贡献
(1)提出了user-tag profiling model,这个模型可以利用用户信息的多个field,并且适用于其他用户画像任务;
(2)在模型中引入了 multi-head attention 机制,共享 query vector;
(3)提出了一个改进的基于FM的交叉特征层;
(4)设计了联合损失来学习用户标签的偏好。
3、UTPM模型整体结构

它分为5层:feature input layer,attention fusion layer,cross feature layer,fully connect layer,predicting layer
3.1 Feature input layer

在特征输入层,输入特征,主要包含两部分:人口统计信息:如年龄、性别等和用户历史阅读信息,用户阅读过的新闻对应的标签集合、类别集合等。
所有的特征都是离散特征,每个特征对应一个field。同时部分是多值离散特征,如点击过的标签集合和类别集合。离散特征通过embedding层转换成相同长度的embedding向量。
3.2 Attention-fusion layer

接来下是Attention-fusion层,在这一层解决提出的问题一:如何自动选择有用的特征?
在这一层有几个field,包括性别,年龄,tag,category等。其中如tag,categogy有不止一个离散特征。首先对多值离散特征进行处理:通过multi-head attention(论文里使用two-head attention),为每个特征计算权重,然后加权求和,得到两个向量输出。
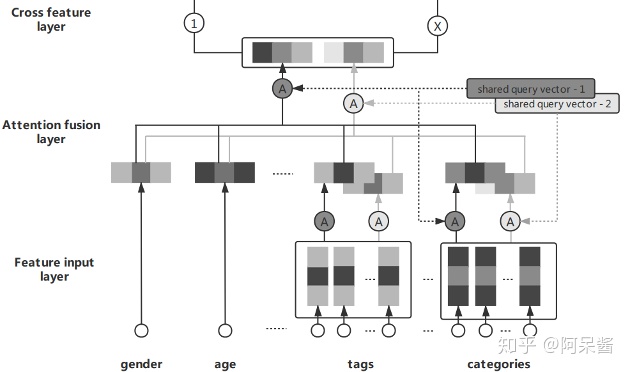
以tag为例:假设第k个field有H个tag feature,

文中使用的是two-head attention,以第一个attention为例:这H个tag向量,会通过加权相加,得到一个embedding向量f,更有用的tag有更高的权重。
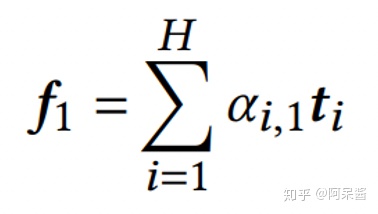
权重通过softmax计算, 其中q是query向量:

这里所有的field共用query向量q1,但参数矩阵 W 是不同的field有不同的参数。这样每个field 的输出都得到了:对于单值离散特征,直接通过embedding层得到对应的embedding。对于多值离散特征,则通过这个计算得到embedding向量。
接下来,对这M个field,用同样的方法进行加权相加得到最终的embedding向量(这里query vector还是共享的)。
论文认为这种共享query向量的方式鲁棒性更好,效果也更好。然后类似的,再进行第二个attention的计算。这样就得到了两个embedding向量,把他们拼接(concatenate)起来给下一层。
3.3 cross feature layer
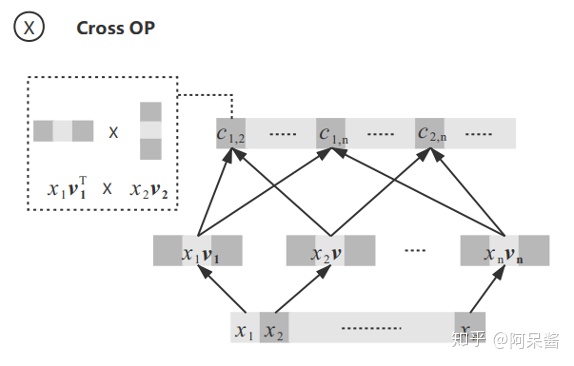
接下来是cross feature layer,进行特征交叉。在这一层进一步解决提出的问题一:怎么学习到不同field之间的特征相互作用?

上一层输出的embedding向量记为x,做两种处理:一是把输入x作为线性部分直接传到下一层;二是对x的不同维度进行特征交叉:x里面的每一维xi,都对应一个隐向量vi,对x的不同维度xi,xj两两组合,计算得到

这里,交叉得到的值直接都保留了,不像FM是相加起来的。

假设x的长度为E,这部分特征交叉得到的长度就为
3.4 Fully connect layer

将attention fusion layer的输出x和cross feature layer的输出c进行拼接,经过两个全连接层得到最终的user embedding。
3.5 Predicting layer

在这一层解决提出的问题2:怎么从用户点击过的新闻中学习到用户对不同标签的偏好?一种做法是把所有用户点击过的新闻中的标签集合作为正样本,把曝光未点击的标签集合作为负样本。但用户点击某个新闻,并不一定是对这篇新闻所有对应的标签都感兴趣,有可能仅仅对其中部分的标签感兴趣。
因此这篇论文将新闻是否点击作为label,预测值的计算过程如下:
首先,对于某篇新闻,其对应的所有标签,(假设N个)转换成与用户向量u相同长度的向量;
然后,用户向量u与所有的标签向量ti进行内积计算并求和,再通过sigmoid得到预测值。
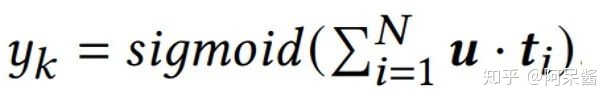
最后,损失函数采用logloss

这样,用户对不同标签i的偏好分别计算,可以使用户更感兴趣的tag有更高的内积值。
【模型部分就这么多啦】
接下来是论文的实验部分。

好了,本文就到这啦。
感兴趣的同学可以下载论文看看噢,欢迎跟我一起讨论~