优化 回归
应用数据科学 (Applied data science)
Price and quantity are two fundamental measures that determine the bottom line of every business, and setting the right price is one of the most important decisions a company can make. Under-pricing hurts the company’s revenue if consumers are willing to pay more and, on the other hand, over-pricing can hurt in a similar fashion if consumers are less inclined to buy the product at a higher price.
价格和数量是确定每项业务底线的两个基本指标,而设定正确的价格是公司可以做出的最重要决定之一。 如果消费者愿意支付更高的价格,定价过低会损害公司的收入;另一方面,如果消费者不太愿意以更高的价格购买产品,那么定价过高也会以类似的方式受到损害。
So given the tricky relationship between price and sales, where is the sweet spot — the optimum price — that maximizes product sales and earns most profit?
因此,考虑到价格与销售之间的棘手关系,最佳产品的最佳销售点在哪里?这可以最大化产品的销售并获得最大的利润?
The purpose of this article is to answer this question by implementing a combination of the economic theory and a regression algorithm in Python environment.
本文的目的是通过在Python环境中实现经济理论和回归算法的结合来回答这个问题。
1.资料 (1. Data)
We are optimizing a future price based on the relationship between historical price and sales, so the first thing we need is the past data on these two indicators. For this exercise, I’m using a time series data on historical beef sales and corresponding unit prices.
我们正在根据历史价格和销售量之间的关系来优化未来价格,因此我们需要的第一件事是这两个指标的过去数据。 在本练习中,我使用有关历史牛肉销售量和相应单价的时间序列数据。
# load data
import pandas as pd
beef = pd# view first few rows
beef.tail(5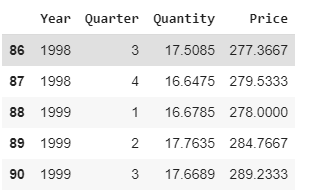
The dataset contains a total of 91 observations of quantity-price pairs reported on a quarterly basis.
该数据集包含每季度报告的91个数量-价格对的观察值。
It is customary in data science to do exploratory data analysis (EDA), but I’m skipping that part to focus on modeling. Nevertheless, I strongly encourage taking this extra step to make sure you understand the data before building models.
数据科学中通常进行探索性数据分析(EDA),但我跳过了这一部分,而只关注建模。 不过,我强烈建议您采取额外的步骤,以确保您在构建模型之前了解数据。
2.图书馆 (2. Libraries)
We need to import libraries for three reasons: manipulating data, building the model, and visualizing the functions.
我们需要导入库的原因有三个:处理数据,构建模型和可视化功能。
We are importing numpy and pandas for creating and manipulating table, mtplotlib and seaborn for visualization and statsmodels API to build and run the regression model.
我们将导入numpy和pandas用于创建和操作表格, mtplotlib和seaborn用于可视化和statsmodels API以构建和运行回归模型。
import numpy as np
from pandas import DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.formula.api import ols
%matplotlib inline2.定义利润函数 (2. Defining the profit function)
We know that revenue depends on the quantity sold and the unit price of products.
我们知道,收入取决于出售的数量和产品的单价。
We also know that profit is calculated by netting out costs from revenue.
我们也知道,利润是通过从收入中扣除成本来计算的。
Putting these two together we get the following equations:
将这两个放在一起,我们得到以下方程式:
# revenue
revenue = quantity * price # eq (1)# profit
profit = revenue - cost # eq (2)We can rewrite the profit function by combining eq. #1 and 2 as follows:
我们可以结合等式来重写利润函数。 #1和2如下:
# revised profit function
profit = quantity * price - cost # eq (3)Eq #3 tells us that we need three pieces of information to calculate profit: quantity, price and cost.
方程3告诉我们,我们需要三项信息来计算利润:数量,价格和成本。
3.定义需求函数 (3. Defining the demand function)
We first need to establish the relationship between quantity and price — the demand function. This demand function is estimated from a “demand curve” based on the linear relationship between price and quantity.
我们首先需要建立数量和价格之间的关系-需求函数。 根据价格和数量之间的线性关系,根据“需求曲线”估算此需求函数。
# demand curve
sns.lmplot(x = "Price", y = "Quantity",
data = beef, fig_reg = True, size = 4)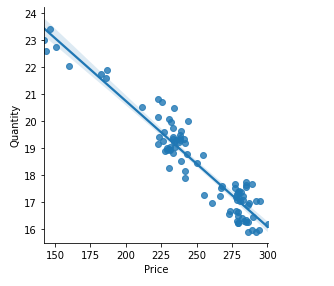
To find that demand curve we will fit an Ordinary Least Square (OLS) regression model.
为了找到需求曲线,我们将拟合普通最小二乘(OLS)回归模型。
# fit OLS model
model = ols("Quantity ~ Price", data = beef).fit()# print model summary
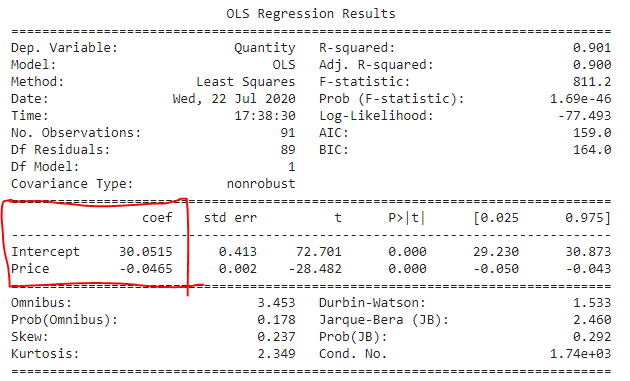
print(model.summary())The following are the regression results with the necessary coefficients needed for further analysis.
以下是回归结果以及进一步分析所需的必要系数。
5.找到利润最大化的价格 (5. Finding the profit-maximizing price)
The coefficient we are looking for is coming from the regression model above — the intercept and the price coefficient — to measure the corresponding sales quantity. We can now plug these values into equation 3.
我们正在寻找的系数来自上面的回归模型(截距和价格系数),用于测量相应的销售量。 现在,我们可以将这些值插入方程式3。
# plugging regression coefficients
quantity = 30.05 - 0.0465 * price # eq (5)# the profit function in eq (3) becomes
profit = (30.05 - 0.0465 * price) * price - cost # eq (6)The next step is to find the price we are looking for from a range of options. The codes below should be intuitive, but basically what we are doing here is calculating revenue for each price and the corresponding quantity sold.
下一步是从一系列选项中找到我们要寻找的价格。 下面的代码应该很直观,但是基本上我们在这里要做的是计算每个价格和相应销售数量的收入。
# a range of diffferent prices to find the optimum one
Price = [320, 330, 340, 350, 360, 370, 380, 390]# assuming a fixed cost
cost = 80Revenue = []for i in Price:
quantity_demanded = 30.05 - 0.0465 * i
# profit function
Revenue.append((i-cost) * quantity_demanded)# create data frame of price and revenue
profit = pd.DataFrame({"Price": Price, "Revenue": Revenue})#plot revenue against price
plt.plot(profit["Price"], profit["Revenue"])If price and revenue are plotted, we can visually identify the peak of the revenue and find the price that makes the revenue at the highest point on the curve.
如果绘制了价格和收入,我们可以直观地识别收入的峰值,并找到使收入处于曲线最高点的价格。
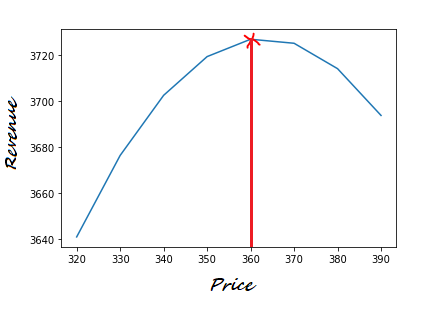
So we find that the maximum revenue at different price levels is reached at $3,726 when the price is set at $360.
因此,我们发现,当价格设为360美元时,在不同价格水平下的最高收入达到3,726美元。
# price at which revenue is maximum
profit[profit['Revenue'] == profit[['Revenue'].max()]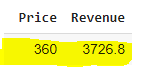
总结和结论 (Summary and conclusions)
The purpose of this article was to demonstrate how to find the price at which the revenue or profit is maximized using a combination of economic theory and statistical modeling. In the initial steps we defined the demand and profit functions, and then ran a regression to find the parameter values needed to feed into the profit/revenue function. And finally, we checked revenues under different price levels to get the price for the corresponding maximum revenue.
本文的目的是演示如何结合经济理论和统计模型找到使收益或利润最大化的价格。 在最初的步骤中,我们定义了需求和利润函数,然后进行回归以找到输入利润/收益函数所需的参数值。 最后,我们检查了不同价格水平下的收入,以获得对应的最大收入的价格。
翻译自: https://towardsdatascience.com/optimizing-product-price-using-regression-2c17688e65ea
优化 回归
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/389422.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

Node.js——异步上传文件

用 JavaScript 的方式理解递归

PyTorch官方教程中文版:Pytorch之图像篇

大数据数据科学家常用面试题_进行数据科学工作面试

scrapy模拟模拟点击_模拟大流行

公司想申请网易企业电子邮箱,怎么样?

莫烦Matplotlib可视化第二章基本使用代码学习

vue.js python_使用Python和Vue.js自动化报告过程

plsql中导入csvs_在命令行中使用sql分析csvs

第十八篇 Linux环境下常用软件安装和使用指南

莫烦Matplotlib可视化第三章画图种类代码学习

计算机科学必读书籍_5篇关于数据科学家的产品分类必读文章

es6解决回调地狱问题

交替最小二乘矩阵分解_使用交替最小二乘矩阵分解与pyspark建立推荐系统

莫烦Matplotlib可视化第四章多图合并显示代码学习

python 网页编程_通过Python编程检索网页

Python+Selenium自动化篇-5-获取页面信息

火种 ctf_分析我的火种数据

莫烦Matplotlib可视化第五章动画代码学习
