熊猫分发
For those just starting out in data science, the Python programming language is a pre-requisite to learning data science so if you aren’t familiar with Python go make yourself familiar and then come back here to start on Pandas.
对于刚接触数据科学的人来说,Python编程语言是学习数据科学的先决条件,因此,如果您不熟悉Python,请先熟悉一下,然后再回到这里开始学习Pandas。
You can start learning Python with a series of articles I just started called Minimal Python Required for Data Science.
您可以从我刚刚开始的一系列文章开始学习Python,这些文章称为“数据科学所需的最小Python” 。
One of the most important tools in the toolbox when it comes to data science is pandas which is a data analytics library for Python developed by Wes McKinney during his tenure at a hedge fund.
关于数据科学,工具箱中最重要的工具之一是pandas,这是Wes McKinney在对冲基金任职期间开发的Python数据分析库。
For this entire series of articles, we’re going to be using Anaconda which is a fancy Python package manager geared for data science and machine learning. If you aren’t familiar with what I just talked about go ahead and check out this video which will teach you about Anaconda and Jupyter Notebook which is central to data science work.
在整个系列文章中,我们将使用Anaconda ,这是一款专为数据科学和机器学习而设计的Python软件包管理器。 如果您不熟悉我刚才所说的内容,请观看此视频,该视频将教您有关Anaconda和Jupyter Notebook的知识,这对数据科学工作至关重要。
You can activate your conda environment (virtual environment) with:
您可以使用以下方法激活conda环境( 虚拟环境 ):
$ conda activate [name of environment]# my environment is named `datascience` so$ conda activate datascienceOnce you activate your conda virtual environment you should see this on your Terminal:
激活conda虚拟环境后,您应该在终端上看到以下内容:
(datascience)$Assuming you have miniconda or anaconda installed on your system you can easily install pandas with:
假设您的系统上安装了miniconda或anaconda,则可以使用以下方法轻松安装熊猫:
$ conda install pandasWe’re also going to be using Jupyter Notebook to do our coding so go ahead and
我们还将使用Jupyter Notebook进行编码,因此继续
$ And startup your Jupyter Notebook with:
然后使用以下命令启动Jupyter Notebook:
$ jupyter notebook熊猫是将所有元素粘合在一起的粘合剂 (Pandas is the glue that holds it all together)

Pandas gets more important as we venture higher up the hierarchy of data science into the fields of machine learning as it allows data to be “cleaned” and “wrangled” before getting fed to algorithms like Random Forest and Neural Networks. If ML algorithms are Doc, then pandas is Marty.
随着我们冒险将数据科学的层次结构带入机器学习领域,Pandas变得越来越重要,因为它允许在将数据馈入随机森林和神经网络等算法之前先对其进行“清理”和“整理”。 如果ML算法是Doc,则熊猫是Marty。
导游巴士之旅 (A Guided Bus Tour)

One of my favorite places to visit even since childhood is the San Diego Zoo. And one thing I always do is to take the guided bus tour while drinking a Blue Moon.
即使从小我最喜欢去的地方之一是圣地亚哥动物园。 我一直要做的一件事就是在喝着“蓝月亮”的同时进行有导游的游览。
We’re going to do something similar in that I’m going to give a brief tour of just some of the things you can do with Pandas. You’re on your own with the Blue Moon.
我们将做类似的事情,简要介绍一下您可以使用Pandas进行的一些操作。 蓝月亮让你自己。
Both the data and the inspiration for this medium series come from Ted Petrou’s excellent courses on Dunder Data.
该媒体系列的数据和灵感均来自Ted Petrou的Dunder Data精品课程。
Pandas essentially deals with tabular data: rows and columns. In this respect it’s very much like an Excel spreadsheet.
熊猫本质上处理表格数据:行和列。 在这方面,它非常类似于Excel电子表格。
The two primary objects you’ll interface with in pandas is the Series and the DataFrame. A DataFrame is two-dimensional data complete with rows and columns.
您将在熊猫中使用的两个主要对象是Series和DataFrame 。 DataFrame是具有行和列的二维数据。
It’s okay if you don’t know what the below code does we will go over it later in detail. The data that we use here concerns bicycle riders in the city of Chicago, Illnoise.
没关系,如果您不知道下面的代码是什么,我们稍后将详细介绍它。 我们在此使用的数据与伊利诺伊斯州芝加哥市的自行车骑手有关。

Series is one-dimensional data or a single column of data with respect to a DataFrame:
系列是相对于DataFrame的一维数据或单列数据:
As shown above one of the highlights of pandas is that it allows data to be loaded into a Jupyter Notebook session from whatever the source file is whether it’s a CSV (comma delimited), XLSX(Excel), SQL, or JSON.
如上所示,pandas的亮点之一是它允许将数据从任何源文件加载到Jupyter Notebook会话中,无论源文件是CSV(逗号分隔),XLSX(Excel),SQL还是JSON。
One of the first things we always do is take a peek at the dataset we’re studying by using the head method. By default head will present the first five rows of the data. We can pass an integer to control how many rows we want to see:
我们经常要做的第一件事就是使用head方法窥视我们正在研究的数据集。 默认情况下, head将显示数据的前五行。 我们可以传递一个整数来控制我们要查看的行数:
df.head(7)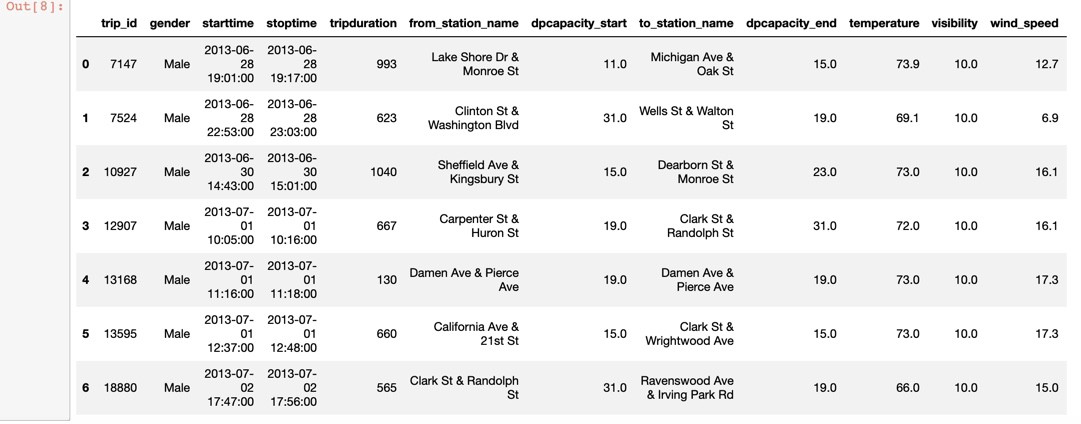
If we want to see the last five rows:
如果要查看最后五行:
df.tail()读入数据 (Read In Data)
We use the read_csv function to load CSV formatted data.
我们使用read_csv函数加载CSV格式的数据。
We pass the path to the file containing our data as a string to the read_csv method of pandas. In my case, I’m using the url of my GitHub Repo which holds all the data that I will be using. I highly recommend reading the documentation regarding pandas read_csv function as it’s one of the most important and dynamic functions within the whole library.
我们将包含数据的文件的路径作为字符串传递给read_csv方法。 就我而言,我使用的是GitHub Repo的网址,该网址包含我将要使用的所有数据。 我强烈建议阅读有关pandas read_csv函数的文档 ,因为它是整个库中最重要且最动态的函数之一。
筛选资料 (Filter Data)
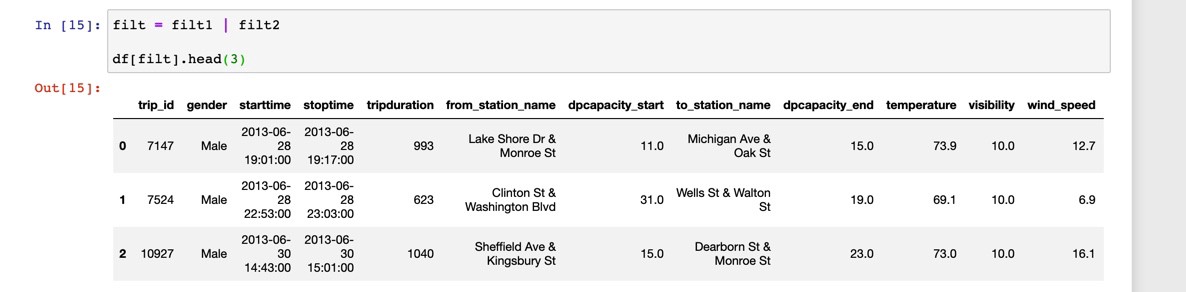
We can filter rows of a pandas DataFrame with conditional logic. For programmers familiar with SQL this would be like using the WHERE clause.
我们可以使用条件逻辑过滤熊猫DataFrame的行。 对于熟悉SQL的程序员,这就像使用WHERE子句。
To retrieve only the rows where wind_speed is greater than 42.0 we can do this:
要仅检索wind_speed大于42.0的行,我们可以这样做:
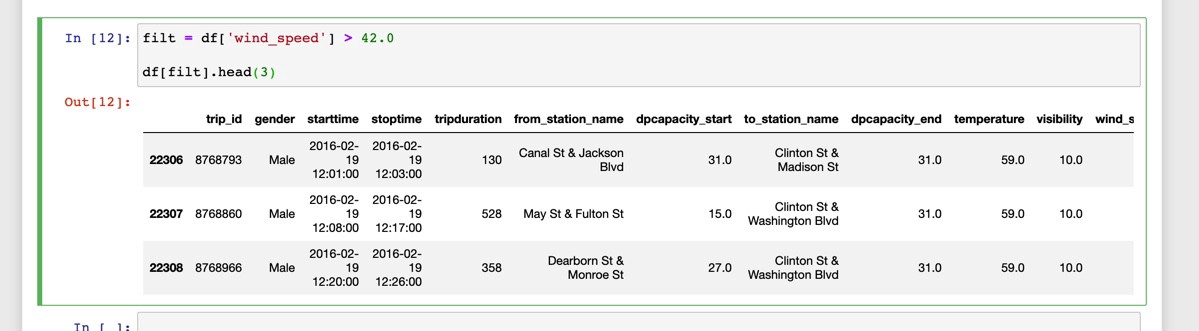
We can filter for more than one condition like this:
我们可以过滤多个条件,例如:

Here we filter for the condition where the wind speed is greater than 42.0 (I’m assuming miles per hour) and where the gender of the bicyclist is female. As we can see it returns an empty dataset.
在这里,我们筛选出风速大于42.0(我假设每小时英里)并且骑自行车的性别是女性的情况。 如我们所见,它返回一个空的数据集。
We can verify that we’re not committing some kind of error that results in an empty query by trying out the same multiple filters but for male riders.
我们可以通过尝试相同的多个过滤器(但针对男性骑手)来验证是否未犯导致空查询的错误。
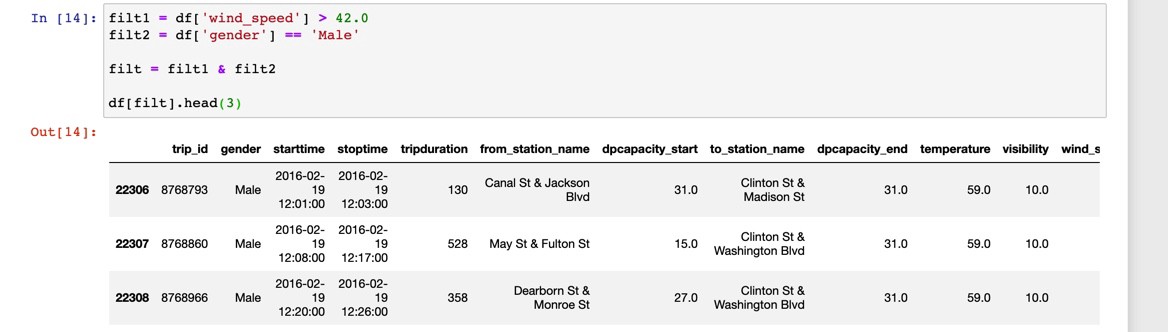
We can also do something like this:
我们还可以这样做:
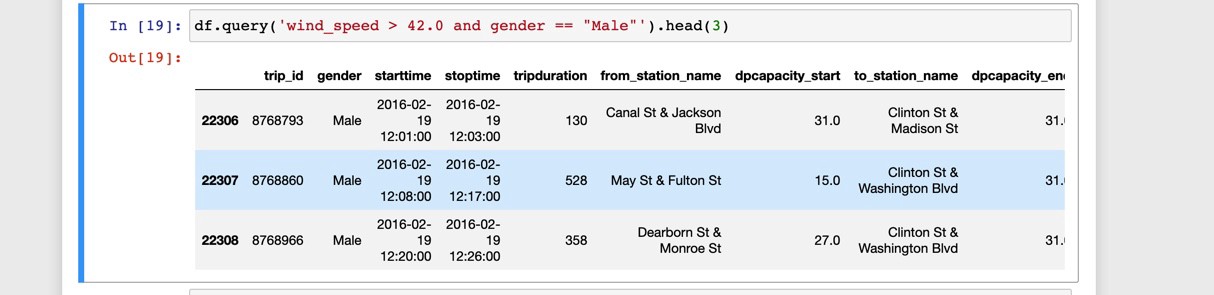
查询:过滤的一种更简单的选择 (Query: A Simpler Alternative to Filtering)
Pandas also has a query method which is somewhat limited in its abilities, but allows for simpler and more readable code. Just as before, programmers familiar with SQL should feel comfortable with this method.
熊猫还具有一种query方法,该query方法的功能受到一定程度的限制,但允许使用更简单和更具可读性的代码。 和以前一样,熟悉SQL的程序员应该对此方法感到满意。
未完待续 (To Be Continued)
Pandas for Newbies is meant to be a Medium series so watch for the next upcoming tutorial Pandas for Newbies: An Introduction Part II which will be posted soon.
《 Pandas for Newbies》是一个中级系列,因此请关注下一个即将发布的教程《 Pandas for Newbies:Introduction Part II》 。
我做的事 (What I do)
I help people find Mentors, Code in Python, and Write about Life. If you’re thinking about switching careers into the tech industry or just want to talk you can sign up for my Slack Channel via VegasBlu.
我帮助人们找到导师,Python代码并撰写关于生活的文章。 如果您正在考虑将职业转向科技行业,或者只是想谈谈,可以通过VegasBlu注册我的Slack频道。
翻译自: https://towardsdatascience.com/pandas-for-newbies-an-introduction-part-i-8246f14efcca
熊猫分发
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/389198.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

多线程 进度条 C# .net

window 10 多版本激活工具

android 动画总结笔记 一

《Linux内核原理与分析》第六周作业

使用C#调用外部Ping命令获取网络连接情况

Codeforces Round 493

android动画笔记二

回归分析检验_回归分析

是什么样的骚操作让应用上线节省90%的时间


Ubuntu 18.04 下如何配置mysql 及 配置远程连接

数据科学与大数据技术的案例_主数据科学案例研究,招聘经理的观点

导致View树遍历的时机

什么是Hyperledger?Linux如何围绕英特尔的区块链项目构建开放平台?

队列的链式存储结构及其实现_了解队列数据结构及其实现


cad2016珊瑚_预测有马的硬珊瑚覆盖率
)
EChart中使用地图方式总结(转载)

android mvp模式
)