一、在SQLServer中连接另一个SQLServer库数据
在SQL中,要想在本地库中查询另一个数据库中的数据表时,可以创建一个链接服务器:
EXEC master.dbo.sp_addlinkedserver @server = N'别名', @srvproduct=N'库名',@provider=N'SQLOLEDB', @datasrc=N'服务器地址'
EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname = N'别名', @locallogin = NULL , @useself= N'False', @rmtuser = N'用户名', @rmtpassword = N'密码'
创建完后,就可以通过“Select * from别名.库名.dbo.表名”来查询了。
或者也可以手工创建:
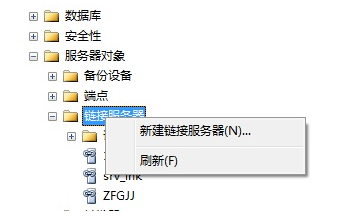
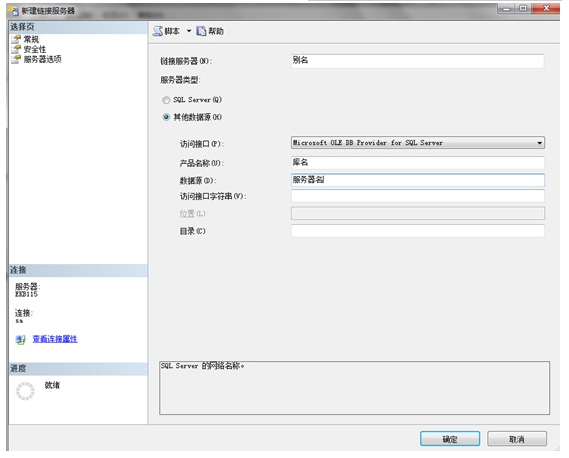
二、在Oracle中连接另一个Oracle库数据
在Oracle中,其实也类似,要连接到其他库时,也需要创建一个类似这样的连接:
create database link别名 connect to 模式名(用户名) identified by "密码" using 'TNS名';
注意:这里面的TNS名就是你需要连接的另一个库的TNS名,而且是必需是在你当前连接的库的服务器端所配置的TNS名。
例如:
create public database link DBLINK
connect to username identified by mypassword
using '(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.1.28)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = ftnemr)
)
)';
创建完后,我们也就可以访问了:“Select * from表名@别名”
如果使用的是PL/SQL开发工具,那么我们也可以直接在工具里创建:
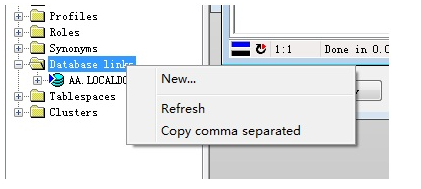
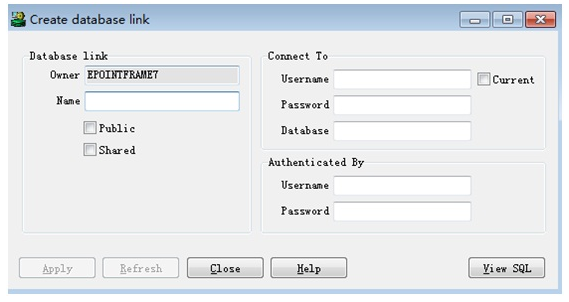
三、在SQL Server中连接Oracle数据
同样,也创建一个数据库连接即可,这时我们采用Ole DB方式连接数据库:
EXEC master.dbo.sp_addlinkedserver @server = N'别名', @srvproduct=N'库名',@provider=N'MSDAORA', @datasrc=N'TNS名'
EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname = N'别名', @locallogin = NULL , @useself= N'False', @rmtuser = N'模式名', @rmtpassword = N'密码'
注意:这里面的TNS名,是在该SQL Server器端所配置的TNS名,不是在客户端本地哦。
创建好了后,使用“select * from openquery(别名,'select * from 模式名.表名”来执行查询。
要连接到其他类型的数据库时,其实方式也类同,只要用相应的provider来连接即可。
四、在Oracle中连接SQL Server数据
在oracle中连接SQLServer也很类似,创建一个DBLink,但问题是,创建DBLink里,里面用的TNS名称都是连接到Oracle的,没有配置连接到SQL Server中的。
于是想到采用Oracle中的透明网关来实现,首先在Oracle的安装名中装上,Oracle Net Services和Oracle Transparent Gateways, 并在此项下选择Oracle Transparent Gateway for Microsoft SQL Server。
配置透明网关,编辑%ORACLE_HOME%/tg4msql/admin/init%ORACLE_SID%.ora, 该文件包含了TG for SQL Server的配置信息, 其中%ORACLE_SID%是给TG的"SID", 默认为tg4msql. 修改文件中的行HS_FDS_CONNECT_INFO="SERVER=SQL服务器地址;DATABASE=库名"。
然后创建监听器:编辑%ORACLE_HOME%/network/admin/listener.ora, 编辑对应listener的SID_LIST:
SID_LIST_LISTENER=
(SID_LIST=
(SID_DESC=
(SID_NAME=%ORACLE_SID%)
(ORACLE_HOME=oracle_home_directory)
(PROGRAM=tg4msql)
)
)
其中%ORACLE_SID%为第二布中设置的SID, 默认值为tg4msql. 修改listener.ora文件后需重启listener使修改生效.
最后就可以配置TNS名了,如果直接修改Tnsname.ora文件的话,添加的格式是:
TNS名=
(DESCRIPTION=
(ADDRESS=(PROTOCOL=TCP)(HOST=sqlserver)(PORT=1521))
(CONNECT_DATA=(SID=网关ID))
(HS=OK))
这样,TNS名后就可以创建DB Links,然后查询的方式与前面一至。









)

)




)


