CNN卷积神经网络的本质就是卷积运算
维度的调整:
tf.reshape(imageInput,[-1,28,28,1])
imageInput为[None,784],N行* 784维 调整为 M28行28列*1通道 即:二维转化为四维数据
参数一:等价于运算结果M
参数二:28 28 表示图片的宽高信息 1表示channel通道个数,因为当前读取的是灰度图故为1
定义变量:
tf.Variable(tf.truncated_normal([5,5,1,32],stddev = 0.1))
参数一:最终生成的维度,这里设置为5*5的卷积内核大小,输入的维度;输入的维度或当前通道数或imageInputReshape最后一位为1,输出为32维
参数二:期望方差
layer1:激励函数+卷积运算
imageInputReshape : w0:5,5,1,32
通过激励函数,来完成当前的卷积运算
tf.nn.relu(tf.nn.conv2d(imageInputReshape,w0,strides=1,1,1,1],padding='SAME')+b0)
参数一:输入图像数据,imageInputReshape是一个M2828*1
参数二:权重矩阵 w0是一个5,5,1,32的维度
参数三:每次移动的步长,这里的步长是个四维的
参数四:SAME表示卷积核可以停留在图像的边缘
其实池化就等价于采样
创建池化层,是得数据量大大减少;
tf.nn.max_pool(layer1,ksize=[1,4,4,1],strides=[1,4,4,1],padding='SAME')
参数一:layer1
参数二:ksize=[1,4,4,1] 表明输入数据是一个M282832 这个数据与对应的ksize相除即M/1 28/4 28/4 32/1=M7732即为池化层的输出结果
参数三:池化层的步长
参数四:池化层是否可以停留在图像的边缘
而max_pool即将[1 2 3 4]结果池化层后变为一维[4],即原来数组中最大的内容
#1 import 导包
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
# 2 load data 加载数据
mnist = input_data.read_data_sets('E:\\Jupyter_workspace\\study\\DL\\MNIST_data',one_hot = True)
# 3 input
imageInput = tf.placeholder(tf.float32,[None,784]) # 输入图片为28*28=784维,图片个数为None
labeInput = tf.placeholder(tf.float32,[None,10]) # 10表示标签
# 4 data reshape 数据维度的调整
# [None,784]->M*28*28*1 2D->4D 28*28 wh 1 channel
imageInputReshape = tf.reshape(imageInput,[-1,28,28,1])
# 5 实现卷积运算 w0 : 卷积内核 5*5 out:32 in:1
w0 = tf.Variable(tf.truncated_normal([5,5,1,32],stddev = 0.1))#w0为权重矩阵,作为卷积的内核来使用,卷积核大小为5*5,输出为32维 输入为1维
b0 = tf.Variable(tf.constant(0.1,shape=[32]))#偏移矩阵一般放在卷积运算之后来进行相加,故相加的时候改变的只是最后一个维度,所以必须让偏移矩阵和权重矩阵的最后一个维度保持一致,即32维
# 6 layer1:激励函数+卷积运算
# imageInputReshape : M*28*28*1 w0:5,5,1,32
layer1 = tf.nn.relu(tf.nn.conv2d(imageInputReshape,w0,strides=[1,1,1,1],padding='SAME')+b0)#卷积运算
# M*28*28*32
# pool 采样 数据量减少很多M*28*28*32 => M*7*7*32
layer1_pool = tf.nn.max_pool(layer1,ksize=[1,4,4,1],strides=[1,4,4,1],padding='SAME')#创建池化层
# [1 2 3 4]->[4]# 7 layer2 out : 激励函数+乘加运算: softmax是一个回归计算函数(激励函数 + 乘加运算)
# [7*7*32,1024]
#实现第二层layer2输出层out:(激励函数+乘加运算)作为另外一个乘加运算的输入内容,最后的计算结果是一个softmax回归计算函数
w1 = tf.Variable(tf.truncated_normal([7*7*32,1024],stddev=0.1))#二维
b1 = tf.Variable(tf.constant(0.1,shape=[1024]))
h_reshape = tf.reshape(layer1_pool,[-1,7*7*32])# M*7*7*32 -> N*N1 维度转换 将四维数据转换维二维数据
# [N*7*7*32] [7*7*32,1024] = N*1024
h1 = tf.nn.relu(tf.matmul(h_reshape,w1)+b1)
# 7.1 softMax
w2 = tf.Variable(tf.truncated_normal([1024,10],stddev=0.1))
b2 = tf.Variable(tf.constant(0.1,shape=[10]))
pred = tf.nn.softmax(tf.matmul(h1,w2)+b2)# N*1024 1024*10 = N*10 最后的输出结果维N*10 N表示N张图片,10表示0-9这10个维度上分布的概率
# N*10( 概率 )N1【0.1 0.2 0.4 0.1 0.2 。。。】0.1表示0出现的概率 0.2表示1出现的概率 0.4表示2出现的概率依此类推
# label。 【0 0 0 0 1 0 0 0。。。】
loss0 = labeInput*tf.log(pred)
loss1 = 0
# 7.2
for m in range(0,500):#测试训练时每次500张for n in range(0,10):#label标签总共有10个维度,需要把这10个维度中的内容进行累加loss1 = loss1 - loss0[m,n]
loss = loss1/500#总共有500组数据# 8 train训练过程,让当前的误差尽可能的减小
train = tf.train.GradientDescentOptimizer(0.01).minimize(loss)#梯度下降法,每次下降0.01,目标是尽可能的缩小当前loss的步长
# 9 run
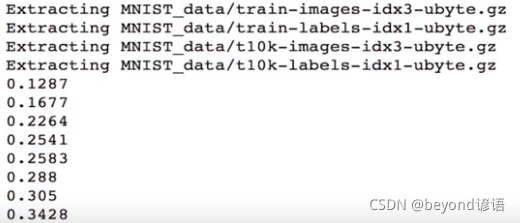
with tf.Session() as sess:sess.run(tf.global_variables_initializer())#完成所以图片的初始for i in range(100):images,labels = mnist.train.next_batch(500)#分别把图片和标签读取出来,每次读取500张图片进行训练sess.run(train,feed_dict={imageInput:images,labeInput:labels})#完成pred的获取pred_test = sess.run(pred,feed_dict={imageInput:mnist.test.images,labeInput:labels})#获得最终的预测结果,是10维的;与label标签都一样也都是10维的acc = tf.equal(tf.arg_max(pred_test,1),tf.arg_max(mnist.test.labels,1))#比较pred和label最大值是否相等acc_float = tf.reduce_mean(tf.cast(acc,tf.float32))#转换均值为float浮点类型acc_result = sess.run(acc_float,feed_dict={imageInput:mnist.test.images,labeInput:mnist.test.labels})print(acc_result)


方法与示例)




)
方法与示例)






方法及示例)

——概述(各种事务隔离级别发生的影响))

