2019独角兽企业重金招聘Python工程师标准>>> 
四、具体格式
上面曾经交代过,Lucene保存了从Index到Segment到Document到Field一直到Term的正向信息,也包括了从Term到Document映射的反向信息,还有其他一些Lucene特有的信息。下面对这三种信息一一介绍。
4.1. 正向信息
Index –> Segments (segments.gen, segments_N) –> Field(fnm, fdx, fdt) –> Term (tvx, tvd, tvf)
上面的层次结构不是十分的准确,因为segments.gen和segments_N保存的是段(segment)的元数据信息(metadata),其实是每个Index一个的,而段的真正的数据信息,是保存在域(Field)和词(Term)中的。
4.1.1. 段的元数据信息(segments_N)
一个索引(Index)可以同时存在多个segments_N(至于如何存在多个segments_N,在描述完详细信息之后会举例说明),然而当我们要打开一个索引的时候,我们必须要选择一个来打开,那如何选择哪个segments_N呢?
Lucene采取以下过程:
- 其一,在所有的segments_N中选择N最大的一个。基本逻辑参照SegmentInfos.getCurrentSegmentGeneration(File[] files),其基本思路就是在所有以segments开头,并且不是segments.gen的文件中,选择N最大的一个作为genA。
- 其二,打开segments.gen,其中保存了当前的N值。其格式如下,读出版本号(Version),然后再读出两个N,如果两者相等,则作为genB。

IndexInput genInput = directory.openInput(IndexFileNames.SEGMENTS_GEN);//"segments.gen"
int version = genInput.readInt();//读出版本号
if (version == FORMAT_LOCKLESS) {//如果版本号正确
long gen0 = genInput.readLong();//读出第一个N
long gen1 = genInput.readLong();//读出第二个N
if (gen0 == gen1) {//如果两者相等则为genB
genB = gen0;
}
}- 其三,在上述得到的genA和genB中选择最大的那个作为当前的N,方才打开segments_N文件。其基本逻辑如下:
if (genA > genB)
gen = genA;
else
gen = genB;
如下图是segments_N的具体格式:

- Format:
- 索引文件格式的版本号。
- 由于Lucene是在不断开发过程中的,因而不同版本的Lucene,其索引文件格式也不尽相同,于是规定一个版本号。
- Lucene 2.1此值-3,Lucene 2.9时,此值为-9。
- 当用某个版本号的IndexReader读取另一个版本号生成的索引的时候,会因为此值不同而报错。
- Version:
- 索引的版本号,记录了IndexWriter将修改提交到索引文件中的次数。
- 其初始值大多数情况下从索引文件里面读出,仅仅在索引开始创建的时候,被赋予当前的时间,已取得一个唯一值。
- 其值改变在IndexWriter.commit->IndexWriter.startCommit->SegmentInfos.prepareCommit->SegmentInfos.write->writeLong(++version)
- 其初始值之所最初取一个时间,是因为我们并不关心IndexWriter将修改提交到索引的具体次数,而更关心到底哪个是最新的。IndexReader中常比较自己的version和索引文件中的version是否相同来判断此IndexReader被打开后,还有没有被IndexWriter更新。
| //在DirectoryReader中有一下函数。 public boolean isCurrent() throws CorruptIndexException, IOException { |
- NameCount
- 是下一个新段(Segment)的段名。
- 所有属于同一个段的索引文件都以段名作为文件名,一般为_0.xxx, _0.yyy, _1.xxx, _1.yyy ……
- 新生成的段的段名一般为原有最大段名加一。
- 如同的索引,NameCount读出来是2,说明新的段为_2.xxx, _2.yyy

- SegCount
- 段(Segment)的个数。
- 如上图,此值为2。
- SegCount个段的元数据信息:
- SegName
- 段名,所有属于同一个段的文件都有以段名作为文件名。
- 如上图,第一个段的段名为"_0",第二个段的段名为"_1"
- SegSize
- 此段中包含的文档数
- 然而此文档数是包括已经删除,又没有optimize的文档的,因为在optimize之前,Lucene的段中包含了所有被索引过的文档,而被删除的文档是保存在.del文件中的,在搜索的过程中,是先从段中读到了被删除的文档,然后再用.del中的标志,将这篇文档过滤掉。
- 如下的代码形成了上图的索引,可以看出索引了两篇文档形成了_0段,然后又删除了其中一篇,形成了_0_1.del,又索引了两篇文档形成_1段,然后又删除了其中一篇,形成_1_1.del。因而在两个段中,此值都是2。
- SegName
| IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); //文档一为:Students should be allowed to go out with their friends, but not allowed to drink beer. //文档二为:My friend Jerry went to school to see his students but found them drunk which is not allowed. writer.commit();//提交两篇文档,形成_0段。 writer.deleteDocuments(new Term("contents", "school"));//删除文档二 |
-
- DelGen
- .del文件的版本号
- Lucene中,在optimize之前,删除的文档是保存在.del文件中的。
- 在Lucene 2.9中,文档删除有以下几种方式:
- IndexReader.deleteDocument(int docID)是用IndexReader按文档号删除。
- IndexReader.deleteDocuments(Term term)是用IndexReader删除包含此词(Term)的文档。
- IndexWriter.deleteDocuments(Term term)是用IndexWriter删除包含此词(Term)的文档。
- IndexWriter.deleteDocuments(Term[] terms)是用IndexWriter删除包含这些词(Term)的文档。
- IndexWriter.deleteDocuments(Query query)是用IndexWriter删除能满足此查询(Query)的文档。
- IndexWriter.deleteDocuments(Query[] queries)是用IndexWriter删除能满足这些查询(Query)的文档。
- 原来的版本中Lucene的删除一直是由IndexReader来完成的,在Lucene 2.9中虽可以用IndexWriter来删除,但是其实真正的实现是在IndexWriter中,保存了readerpool,当IndexWriter向索引文件提交删除的时候,仍然是从readerpool中得到相应的IndexReader,并用IndexReader来进行删除的。下面的代码可以说明:
- DelGen
| IndexWriter.applyDeletes() -> DocumentsWriter.applyDeletes(SegmentInfos) -> reader.deleteDocument(doc); |
-
-
-
- DelGen是每当IndexWriter向索引文件中提交删除操作的时候,加1,并生成新的.del文件。
-
-
| IndexWriter.commit() -> IndexWriter.applyDeletes() -> IndexWriter$ReaderPool.release(SegmentReader) -> SegmentReader(IndexReader).commit() -> SegmentReader.doCommit(Map) -> SegmentInfo.advanceDelGen() -> if (delGen == NO) { |
| IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); indexDocs(writer, docDir);//索引两篇文档,一篇包含"school",另一篇包含"beer" 形成的索引文件如下:
|

-
- DocStoreOffset
- DocStoreSegment
- DocStoreIsCompoundFile
- 对于域(Stored Field)和词向量(Term Vector)的存储可以有不同的方式,即可以每个段(Segment)单独存储自己的域和词向量信息,也可以多个段共享域和词向量,把它们存储到一个段中去。
- 如果DocStoreOffset为-1,则此段单独存储自己的域和词向量,从存储文件上来看,如果此段段名为XXX,则此段有自己的XXX.fdt,XXX.fdx,XXX.tvf,XXX.tvd,XXX.tvx文件。DocStoreSegment和DocStoreIsCompoundFile在此处不被保存。
- 如果DocStoreOffset不为-1,则DocStoreSegment保存了共享的段的名字,比如为YYY,DocStoreOffset则为此段的域及词向量信息在共享段中的偏移量。则此段没有自己的XXX.fdt,XXX.fdx,XXX.tvf,XXX.tvd,XXX.tvx文件,而是将信息存放在共享段的YYY.fdt,YYY.fdx,YYY.tvf,YYY.tvd,YYY.tvx文件中。
- DocumentsWriter中有两个成员变量:String segment是当前索引信息存放的段,String docStoreSegment是域和词向量信息存储的段。两者可以相同也可以不同,决定了域和词向量信息是存储在本段中,还是和其他的段共享。
- IndexWriter.flush(boolean triggerMerge, boolean flushDocStores, boolean flushDeletes)中第二个参数flushDocStores会影响到是否单独或是共享存储。其实最终影响的是DocumentsWriter.closeDocStore()。每当flushDocStores为false时,closeDocStore不被调用,说明下次添加到索引文件中的域和词向量信息是同此次共享一个段的。直到flushDocStores为true的时候,closeDocStore被调用,从而下次添加到索引文件中的域和词向量信息将被保存在一个新的段中,不同此次共享一个段(在这里需要指出的是Lucene的一个很奇怪的实现,虽然下次域和词向量信息是被保存到新的段中,然而段名却是这次被确定了的,在initSegmentName中当docStoreSegment == null时,被置为当前的segment,而非下一个新的segment,docStoreSegment = segment,于是会出现如下面的例子的现象)。
- 好在共享域和词向量存储并不是经常被使用到,实现也或有缺陷,暂且解释到此。
| IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); //flush生成segment "_0",并且flush函数中,flushDocStores设为false,也即下个段将同本段共享域和词向量信息,这时DocumentsWriter中的docStoreSegment= "_0"。 indexDocs(writer, docDir); //commit生成segment "_1",由于上次flushDocStores设为false,于是段"_1"的域以及词向量信息是保存在"_0"中的,在这个时刻,段"_1"并不生成自己的"_1.fdx"和"_1.fdt"。然而在commit函数中,flushDocStores设为true,也即下个段将单独使用新的段来存储域和词向量信息。然而这时,DocumentsWriter中的docStoreSegment= "_1",也即当段"_2"存储其域和词向量信息的时候,是存在"_1.fdx"和"_1.fdt"中的,而段"_1"的域和词向量信息却是存在"_0.fdt"和"_0.fdx"中的,这一点非常令人困惑。 如图writer.commit的时候,_1.fdt和_1.fdx并没有形成。
indexDocs(writer, docDir); //段"_2"形成,由于上次flushDocStores设为true,其域和词向量信息是新创建一个段保存的,却是保存在_1.fdt和_1.fdx中的,这时候才产生了此二文件。
indexDocs(writer, docDir); //段"_3"形成,由于上次flushDocStores设为false,其域和词向量信息是共享一个段保存的,也是是保存在_1.fdt和_1.fdx中的 indexDocs(writer, docDir); //段"_4"形成,由于上次flushDocStores设为false,其域和词向量信息是共享一个段保存的,也是是保存在_1.fdt和_1.fdx中的。然而函数commit中flushDocStores设为true,也意味着下一个段将新创建一个段保存域和词向量信息,此时DocumentsWriter中docStoreSegment= "_4",也表明了虽然段"_4"的域和词向量信息保存在了段"_1"中,将来的域和词向量信息却要保存在段"_4"中。此时"_4.fdx"和"_4.fdt"尚未产生。
indexDocs(writer, docDir); //段"_5"形成,由于上次flushDocStores设为true,其域和词向量信息是新创建一个段保存的,却是保存在_4.fdt和_4.fdx中的,这时候才产生了此二文件。
indexDocs(writer, docDir); //段"_6"形成,由于上次flushDocStores设为false,其域和词向量信息是共享一个段保存的,也是是保存在_4.fdt和_4.fdx中的
|





-
- HasSingleNormFile
- 在搜索的过程中,标准化因子(Normalization Factor)会影响文档最后的评分。
- 不同的文档重要性不同,不同的域重要性也不同。因而每个文档的每个域都可以有自己的标准化因子。
- 如果HasSingleNormFile为1,则所有的标准化因子都是存在.nrm文件中的。
- 如果HasSingleNormFile不是1,则每个域都有自己的标准化因子文件.fN
- NumField
- 域的数量
- NormGen
- 如果每个域有自己的标准化因子文件,则此数组描述了每个标准化因子文件的版本号,也即.fN的N。
- IsCompoundFile
- 是否保存为复合文件,也即把同一个段中的文件按照一定格式,保存在一个文件当中,这样可以减少每次打开文件的个数。
- 是否为复合文件,由接口IndexWriter.setUseCompoundFile(boolean)设定。
- 非符合文件同符合文件的对比如下图:
- HasSingleNormFile
非复合文件:  | 复合文件:  |
-
- DeletionCount
- 记录了此段中删除的文档的数目。
- HasProx
- 如果至少有一个段omitTf为false,也即词频(term freqency)需要被保存,则HasProx为1,否则为0。
- Diagnostics
- 调试信息。
- DeletionCount
- User map data
- 保存了用户从字符串到字符串的映射Map
- CheckSum
- 此文件segment_N的校验和。
| 读取此文件格式参考SegmentInfos.read(Directory directory, String segmentFileName):
|
4.1.2. 域(Field)的元数据信息(.fnm)
一个段(Segment)包含多个域,每个域都有一些元数据信息,保存在.fnm文件中,.fnm文件的格式如下:

- FNMVersion
- 是fnm文件的版本号,对于Lucene 2.9为-2
- FieldsCount
- 域的数目
- 一个数组的域(Fields)
- FieldName:域名,如"title","modified","content"等。
- FieldBits:一系列标志位,表明对此域的索引方式
- 最低位:1表示此域被索引,0则不被索引。所谓被索引,也即放到倒排表中去。
- 仅仅被索引的域才能够被搜到。
- Field.Index.NO则表示不被索引。
- Field.Index.ANALYZED则表示不但被索引,而且被分词,比如索引"hello world"后,无论是搜"hello",还是搜"world"都能够被搜到。
- Field.Index.NOT_ANALYZED表示虽然被索引,但是不分词,比如索引"hello world"后,仅当搜"hello world"时,能够搜到,搜"hello"和搜"world"都搜不到。
- 一个域出了能够被索引,还能够被存储,仅仅被存储的域是搜索不到的,但是能通过文档号查到,多用于不想被搜索到,但是在通过其它域能够搜索到的情况下,能够随着文档号返回给用户的域。
- Field.Store.Yes则表示存储此域,Field.Store.NO则表示不存储此域。
- 倒数第二位:1表示保存词向量,0为不保存词向量。
- Field.TermVector.YES表示保存词向量。
- Field.TermVector.NO表示不保存词向量。
- 倒数第三位:1表示在词向量中保存位置信息。
- Field.TermVector.WITH_POSITIONS
- 倒数第四位:1表示在词向量中保存偏移量信息。
- Field.TermVector.WITH_OFFSETS
- 倒数第五位:1表示不保存标准化因子
- Field.Index.ANALYZED_NO_NORMS
- Field.Index.NOT_ANALYZED_NO_NORMS
- 倒数第六位:是否保存payload
- 最低位:1表示此域被索引,0则不被索引。所谓被索引,也即放到倒排表中去。
要了解域的元数据信息,还要了解以下几点:
- 位置(Position)和偏移量(Offset)的区别
- 位置是基于词Term的,偏移量是基于字母或汉字的。

- 索引域(Indexed)和存储域(Stored)的区别
- 一个域为什么会被存储(store)而不被索引(Index)呢?在一个文档中的所有信息中,有这样一部分信息,可能不想被索引从而可以搜索到,但是当这个文档由于其他的信息被搜索到时,可以同其他信息一同返回。
- 举个例子,读研究生时,您好不容易写了一篇论文交给您的导师,您的导师却要他所第一作者而您做第二作者,然而您导师不想别人在论文系统中搜索您的名字时找到这篇论文,于是在论文系统中,把第二作者这个Field的Indexed设为false,这样别人搜索您的名字,永远不知道您写过这篇论文,只有在别人搜索您导师的名字从而找到您的文章时,在一个角落表述着第二作者是您。
- payload的使用
- 我们知道,索引是以倒排表形式存储的,对于每一个词,都保存了包含这个词的一个链表,当然为了加快查询速度,此链表多用跳跃表进行存储。
- Payload信息就是存储在倒排表中的,同文档号一起存放,多用于存储与每篇文档相关的一些信息。当然这部分信息也可以存储域里(stored Field),两者从功能上基本是一样的,然而当要存储的信息很多的时候,存放在倒排表里,利用跳跃表,有利于大大提高搜索速度。
- Payload的存储方式如下图:

-
- Payload主要有以下几种用法:
- 存储每个文档都有的信息:比如有的时候,我们想给每个文档赋一个我们自己的文档号,而不是用Lucene自己的文档号。于是我们可以声明一个特殊的域(Field)"_ID"和特殊的词(Term)"_ID",使得每篇文档都包含词"_ID",于是在词"_ID"的倒排表里面对于每篇文档又有一项,每一项都有一个payload,于是我们可以在payload里面保存我们自己的文档号。每当我们得到一个Lucene的文档号的时候,就能从跳跃表中查找到我们自己的文档号。
- Payload主要有以下几种用法:
| //声明一个特殊的域和特殊的词 public static final String ID_PAYLOAD_FIELD = "_ID"; public static final String ID_PAYLOAD_TERM = "_ID"; public static final Term ID_TERM = new Term(ID_PAYLOAD_TERM, ID_PAYLOAD_FIELD); //声明一个特殊的TokenStream,它只生成一个词(Term),就是那个特殊的词,在特殊的域里面。 static class SinglePayloadTokenStream extends TokenStream { SinglePayloadTokenStream(String idPayloadTerm) { void setPayloadValue(byte[] value) { public Token next() throws IOException { //对于每一篇文档,都让它包含这个特殊的词,在特殊的域里面 SinglePayloadTokenStream singlePayloadTokenStream = new SinglePayloadTokenStream(ID_PAYLOAD_TERM); long id = 0; |
-
-
- 影响词的评分
- 在Similarity抽象类中有函数public float scorePayload(byte [] payload, int offset, int length) 可以根据payload的值影响评分。
- 影响词的评分
-
- 读取域元数据信息的代码如下:
| FieldInfos.read(IndexInput, String)
|
4.1.3. 域(Field)的数据信息(.fdt,.fdx)

- 域数据文件(fdt):
- 真正保存存储域(stored field)信息的是fdt文件
- 在一个段(segment)中总共有segment size篇文档,所以fdt文件中共有segment size个项,每一项保存一篇文档的域的信息
- 对于每一篇文档,一开始是一个fieldcount,也即此文档包含的域的数目,接下来是fieldcount个项,每一项保存一个域的信息。
- 对于每一个域,fieldnum是域号,接着是一个8位的byte,最低一位表示此域是否分词(tokenized),倒数第二位表示此域是保存字符串数据还是二进制数据,倒数第三位表示此域是否被压缩,再接下来就是存储域的值,比如new Field("title", "lucene in action", Field.Store.Yes, …),则此处存放的就是"lucene in action"这个字符串。
- 域索引文件(fdx)
- 由域数据文件格式我们知道,每篇文档包含的域的个数,每个存储域的值都是不一样的,因而域数据文件中segment size篇文档,每篇文档占用的大小也是不一样的,那么如何在fdt中辨别每一篇文档的起始地址和终止地址呢,如何能够更快的找到第n篇文档的存储域的信息呢?就是要借助域索引文件。
- 域索引文件也总共有segment size个项,每篇文档都有一个项,每一项都是一个long,大小固定,每一项都是对应的文档在fdt文件中的起始地址的偏移量,这样如果我们想找到第n篇文档的存储域的信息,只要在fdx中找到第n项,然后按照取出的long作为偏移量,就可以在fdt文件中找到对应的存储域的信息。
- 读取域数据信息的代码如下:
| Document FieldsReader.doc(int n, FieldSelector fieldSelector)
|
4.1.3. 词向量(Term Vector)的数据信息(.tvx,.tvd,.tvf)
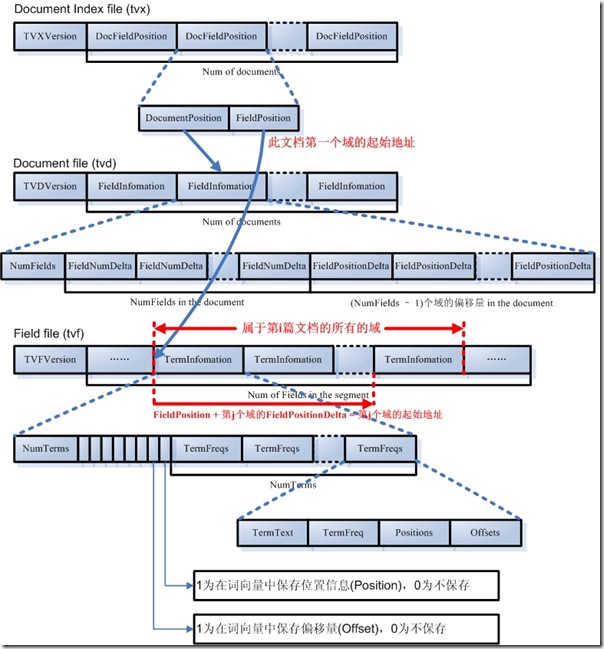
词向量信息是从索引(index)到文档(document)到域(field)到词(term)的正向信息,有了词向量信息,我们就可以得到一篇文档包含那些词的信息。
- 词向量索引文件(tvx)
- 一个段(segment)包含N篇文档,此文件就有N项,每一项代表一篇文档。
- 每一项包含两部分信息:第一部分是词向量文档文件(tvd)中此文档的偏移量,第二部分是词向量域文件(tvf)中此文档的第一个域的偏移量。
- 词向量文档文件(tvd)
- 一个段(segment)包含N篇文档,此文件就有N项,每一项包含了此文档的所有的域的信息。
- 每一项首先是此文档包含的域的个数NumFields,然后是一个NumFields大小的数组,数组的每一项是域号。然后是一个(NumFields - 1)大小的数组,由前面我们知道,每篇文档的第一个域在tvf中的偏移量在tvx文件中保存,而其他(NumFields - 1)个域在tvf中的偏移量就是第一个域的偏移量加上这(NumFields - 1)个数组的每一项的值。
- 词向量域文件(tvf)
- 此文件包含了此段中的所有的域,并不对文档做区分,到底第几个域到第几个域是属于那篇文档,是由tvx中的第一个域的偏移量以及tvd中的(NumFields - 1)个域的偏移量来决定的。
- 对于每一个域,首先是此域包含的词的个数NumTerms,然后是一个8位的byte,最后一位是指定是否保存位置信息,倒数第二位是指定是否保存偏移量信息。然后是NumTerms个项的数组,每一项代表一个词(Term),对于每一个词,由词的文本TermText,词频TermFreq(也即此词在此文档中出现的次数),词的位置信息,词的偏移量信息。
- 读取词向量数据信息的代码如下:
| TermVectorsReader.get(int docNum, String field, TermVectorMapper)
|
分类: Lucene原理与代码分析

)


)












![ecshop模板支持php,[老杨原创]关于ECSHOP模板架设的服务器php版本过高报错的解决方法集合...](http://pic.xiahunao.cn/ecshop模板支持php,[老杨原创]关于ECSHOP模板架设的服务器php版本过高报错的解决方法集合...)

