第一次个人作业——词频统计
第一次做这种大作业,明显感觉陌生,各种规范和技能也是第一次使用,希望自己好运。
目录:一、基本要求
二、需求分析及时间估计
三、实现思路及过程
四、测试用例、时间性能分析及改进方法
五、经验总结
一、基本要求
1. 统计文件的字符数(只需要统计Ascii码,汉字不用考虑,换行符不用考虑,'\0'不用考虑)(ascii码大小在[32,126]之间)
2. 统计文件的单词总数
3. 统计文件的总行数(任何字符构成的行,都需要统计)(不要只看换行符的数量,要小心最后一行没有换行符的情形)(空行算一行)
4. 统计文件中各单词的出现次数,输出频率最高的10个。
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
7. 在Linux系统下,进行性能分析,过程写到blog中(附加题)
注意:
a) 空格,水平制表符,换行符,均算字符
b) 单词的定义:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
分割符:空格,非字母数字符号
例如:”file123”是一个单词,”123file”不是一个单词。file,File和FILE是同一个单词。
如果两个单词只有最后的数字结尾不同,则认为是同一个单词,例如,windows,windows95和windows7是同一个单词;
输出按字典顺序,例如,windows95,windows98和windows2000同时出现时,输出windows2000
c)词组的定义:windows95 good, windows2000 good123,可以算是同一种词组。按照词典顺序输出。
两个合法单词之间,出现一个非法字符串,比如:windows2000 abc good123,因为abc按照定义不是单词,因此这个词组其实是windows2000 good123,中间的abc当做分隔符看待。
两个单词分属两行,也可以直接组成一个词组。统计词组,只看顺序上,是否相邻。
d) 输入文件名以命令行参数传入。需要遍历整个文件夹时,则要输入文件夹的路径。
e) 输出文件result.txt
characters: number
words: number
lines: number
<word>: number
<word>为文件中真实出现的单词大小写格式,例如,如果文件中只出现了File和file,程序不应当输出FILE,且<word>按字典顺序(基于ASCII)排列,上例中程序应该输出File: 2
f) 根据命令行参数判断是否为目录
g) 将所有文件中的词汇,进行统计,最终只输出一个整体的词频统计结果。
二、需求分析及时间估计
1.统计字符总数及行数;
2.甄别单词并予以统计;
3.甄别词组并予以统计;
4.根据频率对单词、词组各自排序;
5.实现对文件夹及子文件夹的遍历;
PSP表格:
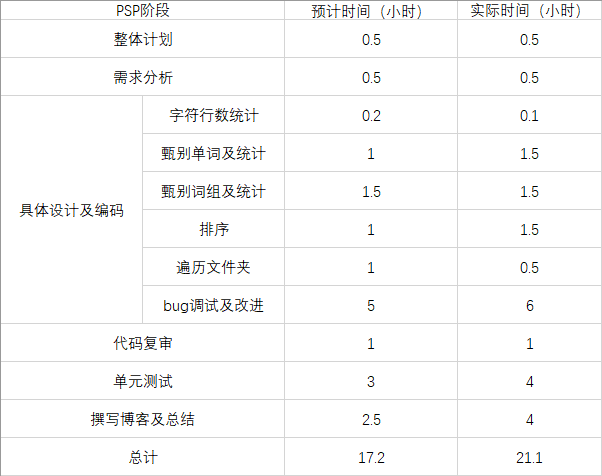
由表可看出,大部分阶段都是超时完成的,亟需改进;整体来看效率也比较低。
三、实现思路及过程
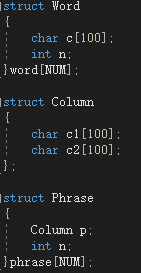
*结构体定义
1.统计字符总数及行数
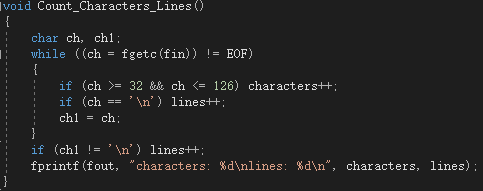
这个就是遍历一下文件,遇到ascii值在32~126之间的就计数,行数统计则是统计换行符的个数,针对最后一个字符表示换行符的文件额外再加一即可。
2.甄别单词并予以统计
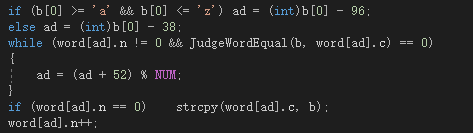
从文件第一个字符开始或者从某一分隔符开始,若检测到字母则开始借助flag标志辨别单词,当连续字母达到四个时说明找到单词,之后继续扫描并依次写入临时数组直到遇见分隔符;如果在连续遇到1~3个字母后被打断,则用标志mark判断若被数字打断则当前字符串作废,继续扫描直到遇见分隔符然后开始下一次单词甄别,如果是被分隔符打断则可以直接开始寻找下一个单词。注意最后退出的时候要判断一下当前字符串是否为单词。

统计部分则是在上述代码中增设一个临时数组b,实时存储字符串,当字符串无效时清空该数组,直到其为一个合法的单词,此时将其插入哈希表,通过单词首字母确定52个元素,按自然顺序1~52构造其哈希地址,用常数52定址解决冲突,若遇到等价的单词则判断字典顺序决定是否覆盖,若没有则新占一个槽。下面是哈希部分的代码:
3.甄别数组并予以统计
这部分我没什么好的思路,基本就是每次成功甄别到一个单词就用临时数组temp记录它,当下一个单词找到时,就把temp和b代入哈希函数去寻址(以temp首字母为自变量),哈希表构造与操作同上。套路与单词统计基本一致,代码不再展示。
4.根据频率对单词、词组各自排序
由于只需要输出频率最高的10个单词及10个词组,堆排序是最好的方式。


数组a按序包含了所有单词在word结构体数组(也就是哈希表)中的下标。算法是以单词频率为排序依据,对每个单词在word数组中的下标进行排序,当已经排好前十个时停止排序并打印结果。对词组的排序与之相同,不再赘述。
5.实现对文件夹及子文件夹的遍历
查阅资料之后得知可以用句柄递归遍历文件夹,从而获取当前文件夹里所有文件的路径,然后处理一下将路径中的‘ \ ’换成 ‘ / ’即可被fopen调用来打开文件了。
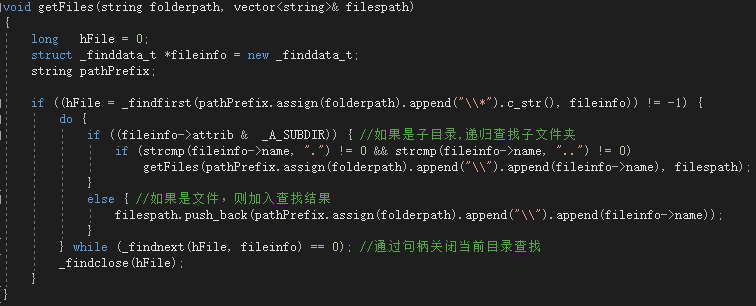
getFiles函数用于获取当前文件夹下所有文件的路径。
完整的源代码地址:https://github.com/ustcychu/HW1_PB16060445.git
四、测试用例及时间性能分析
1.第一次调试用了个555k的文件夹,然后用了7.688秒orz,所以就靠优化工作了。
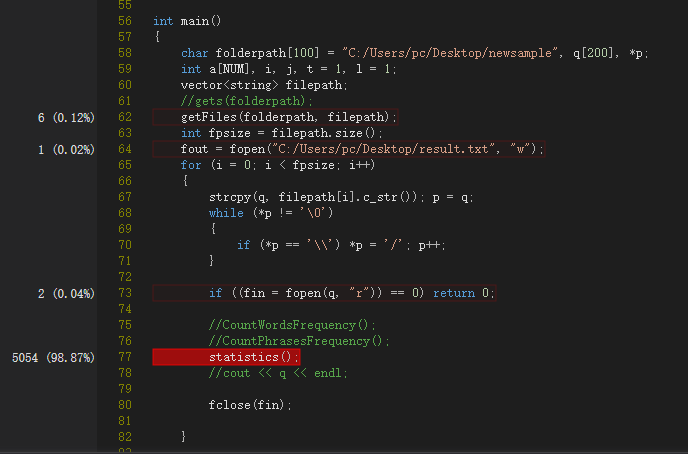
主函数中的热行当然在于调用分析函数statistics()。
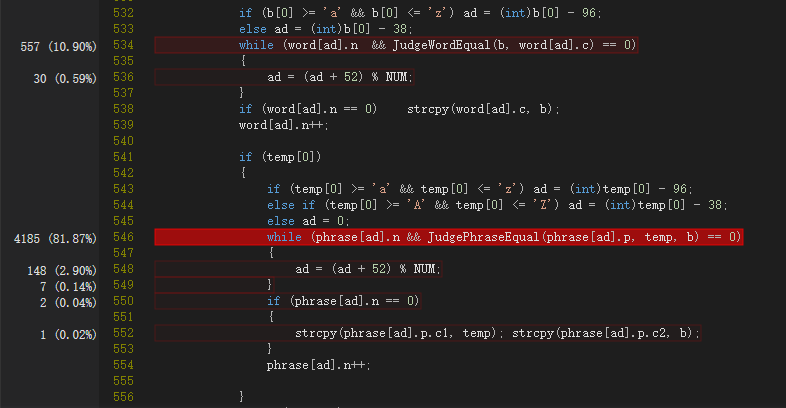
statistics函数中的热行在于两次构造哈希表查找空槽和判断是否等价的过程,而且词组部分的耗时明显高于单词部分。

所以首先该分析的是JudgeWordEqual函数。其大致工作流程是判断俩字符串长度大小关系然后从后往前扫描,如果最后一段数字之前(如果有的话)的部分等价就判定俩单词等价,然再从头遍历判断二者字典顺序并予以覆盖,方便后续操作。
分析结果显示,大部分判断长度大小关系的结果都是二者相等,所以应放在第一个判断从句;用strlen取字符串长度耗时较多;上述两次遍历时间太长。
因此决定先针对性优化,效果不好就尝试别的方法。经过改进,时间缩至6.56秒。
接着我又重写了一种方法:
从两个字符串末尾开始扫描直到非数字的字符,将这之前的字符串片段取出进行不区分字母大小写的比较(stricmp),若匹配则说明俩字符串等价,然后用strcmp判断二者字典顺序选择是否进行覆盖,方便之后的操作。

似乎有了进步—5.01秒,但好像也不是特别好qaq。
再在lb--后面加上判断la与lb是否相等的判断以避免不必要的运算—时间缩至4.833秒。
之后再经过分析认为可能是哈希函数的问题,于是作了修改(主要就是扩大哈希函数的值域以减少搜索):

对应的查找与插入:
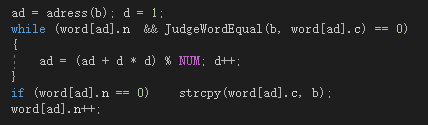
事实上,哈希函数如果给自变量加权的话可能效果更好,还有散列函数还可以选择二次探测法和拉链法(有时间的话再写一份拉链法的毕竟指针操作快很多 可惜开始没有想到),出于时间限制没有继续写下去了。
此次修改之后对应时间缩至1.633秒(还是有了一点点效果)。
2.测试空文件

(按要求空文件也记行 虽然不知道为啥要记...)
3.测试只有一个单词的文件

4.测试只有一行的文件:hhhh a1hhh hhhh lalalala

5.其他测试集 ( 优化前)
A.(27k,0.018s)

B.(32k,0.024s)
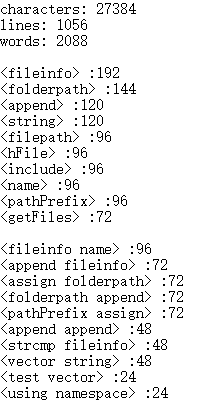
C.(1M, 5.243秒)

6.其他测试集(优化后)
A.(1.2M, 2.56秒)

B.(5.2M,3.791秒)

C.(21M, 11.143秒)

附时间性能分析


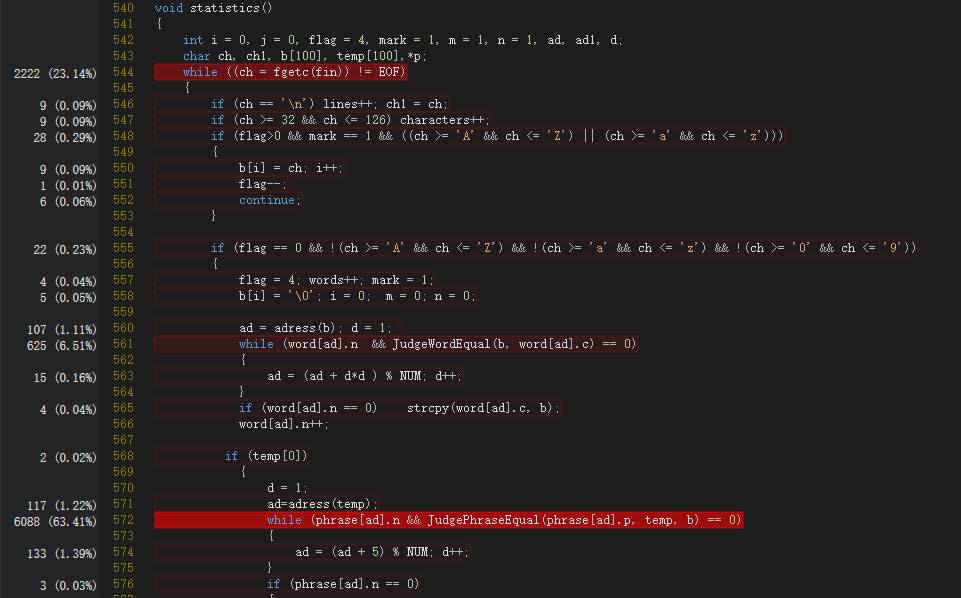
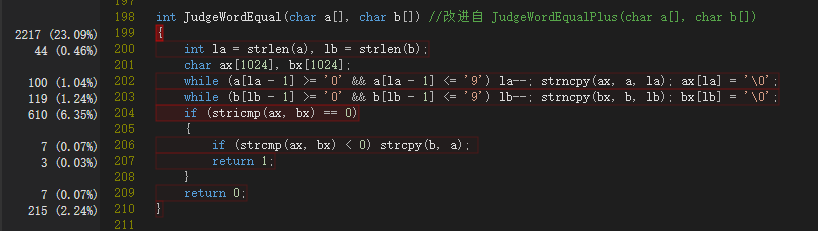
可以看出代码的热行没有改变,改动的两个地方(JudgeWordEqual和哈希函数)的时间性能好了很多。
很明显可优化的地方还很多,今后继续学习逐渐进步。
***标准测试集(177M,21min)***

五、经验总结
通过本次实验,回顾了不少编程知识,也在看书浏览博客的过程中收获了很多技能;与之前的编程经历相比进步在于编程增加模块功能时结构更清晰、语句整理更熟练、细节bug明显减少,但在代码运行效率方面还有很大的进步空间,首先需要学习更多更高级的语言和工具,目前也是在进行中为团队项目做准备,其次是在编程算法上有待锻炼,目前感觉还是太老套,需要更多的阅读积累。希望通过本学期的学习能够很好地提升自己的软件编程能力,为今后做好准备。


![【uoj#209】[UER #6]票数统计 组合数+乱搞](http://pic.xiahunao.cn/【uoj#209】[UER #6]票数统计 组合数+乱搞)






)
)


Redis 持久化AOF方式)





)