最近处理的小问题很多,我就拿出来几个,简单和大家说一说。我就分为三个方面,硬件问题,Oracle表空间迁移,MySQL断电恢复
首先是硬件问题。
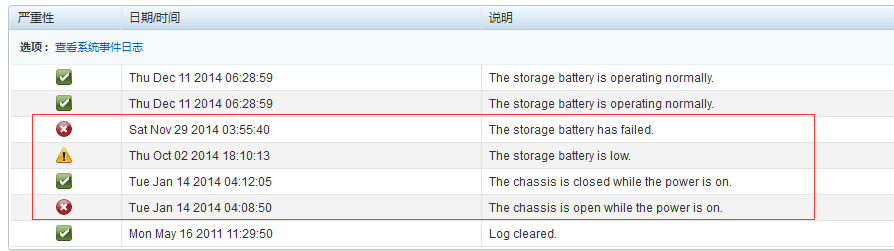
如果看到下面的系统日志,就会发现早在2014年就出现了一些警告和问题,随后看似已经修复了部分,但是实际情况是这台服务器的电源已经坏了一个,另外一个已经快扛不住了。但是通过这些信息就很难读到之前的问题,因为问题已经过去了好久,一直没有问题,应该就是没有问题吧,或者之前的人已经处理了吧,如果这样想,是一种乐观的方式。
最好还是做一些确认,我就是那么想的,然后在某一天一台备库的服务器就突然殉职了。究其原因就是电源问题。
打开系统的ILO界面,才突然发现只识别了一个电源,而且已经无法正常开启电源了。
对于这类问题,还有一个想法就是,机器过就过老,更新换代如此频繁,还是有好的硬件配置就用上,很多时候都是感觉舍不得,动不得,如果你要迁移某个服务器,去和各个部门协调,总会有这个不能动,那个不能改的顾虑,但是服务器可不会讲这些情面,有时候**还是有道理的,这些问题也能够反应出来我们对待问题的态度,都是被动接受,而不是主动改进。出了问题之后发现这些必须得动,必须得改,感觉那个时候就有些匆忙,仓促了。
然后第二个问题,是一个表空间的迁移问题。
之前帮助开发的同事处理了一个表空间无法扩展的小case,然后建议他们后续进行硬盘扩容,从根本上解决这个问题,开发同事还真听进去了,申请了一块较大的硬盘,但是还是希望我来帮助他们来迁移这个表空间,这个问题其实很简单。
可以使用常规的方法即可,唯一的不同在于这个表空间是个bigfile tablespace,所以心里还是存在一点小小的顾虑,是否对于能够100%成功。
因为这个表空间的设置,里面只有一个数据文件,新的磁盘分区在/data下面。
在迁移的时候,开发的同事还是希望能够在线迁移,从我的大量实践来说,这些也都不是大的问题,然后使用了下面的脚本。
alter tablespace CYTJ_DATA offline;
!cp '/home/oracle/tablespace/cytj_data.dbf' '/data/cytj/datafile/cytj_data.dbf';
alter tablespace CYTJ_DATA rename datafile '/home/oracle/tablespace/cytj_data.dbf' to '/data/cytj/datafile/cytj_data.dbf';
alter tablespace CYTJ_DATA online;
当然拷贝大的文件,第二步花费了一些时间,其它步骤都是秒级完成。
迁移完了,还是有一些后续的补充工作的。
首先要删除原有的文件,再三确认之后,就可以删除了。
但是使用df -h发现,空间却压根没有释放,应该能够释放50多G才对。
#df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda5 4.0G 359M 3.4G 10% /
/dev/sda11 106G 96G 5.5G 95% /home
/dev/sdb1 551G 61G 463G 12% /data
对于这个问题,解决方法也比较简单,就是查看句柄的使用情况。
通过下面的命令可以看到迁移前和迁移后都存在一些句柄关联,哪些迁移前的文件已然被标示为deleted
#lsof |grep cytj_data.dbf
oracle 1536 oracle 263u REG 8,11 64424517632 2490413 /home/oracle/tablespace/cytj_data.dbf (deleted)
oracle 5427 oracle 262uW REG 8,17 64424517632 31719427 /data/cytj/datafile/cytj_data.dbf
oracle 5431 oracle 262u REG 8,17 64424517632 31719427 /data/cytj/datafile/cytj_data.dbf
oracle 5433 oracle 260u REG 8,17 64424517632 31719427 /data/cytj/datafile/cytj_data.dbf
oracle 6393 oracle 257u REG 8,17 64424517632 31719427 /data/cytj/datafile/cytj_data.dbf
oracle 8729 oracle 257u REG 8,11 64424517632 2490413 /home/oracle/tablespace/cytj_data.dbf (deleted)
oracle 8971 oracle 256u REG 8,11 64424517632 2490413 /home/oracle/tablespace/cytj_data.dbf (deleted)
oracle 9358 oracle 256u REG 8,11 64424517632 2490413 /home/oracle/tablespace/cytj_data.dbf (deleted)
以其中的一个进程为例,发现是一个应用连接。
#ps -ef|grep 1536
oracle 1536 1 0 18:07 ? 00:00:00 oraclecytj (LOCAL=NO)
root 6321 5715 0 22:48 pts/0 00:00:00 grep 1536
所以这些session还是对这个迁移造成了潜移默化的影响,我们需要释放这些句柄来,就可以kill掉了。
清理掉这些进程之后,再次查看就没有问题了。
#df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda11 106G 52G 50G 52% /home
/dev/sdb1 551G 61G 463G 12% /data
问题解决完了,还需要注意什么呢,需要设置这个数据文件的maxsize,这个分区目前有500G左右,所以大可以放心把它置为500G以内。原来的maxsize值是50G,差的还很远呢。
第三个问题是关于MySQL的从库问题。
因为之前有一台服务器因为硬件问题掉电,在补充了新的电源之后又开始正常工作了,但是查看从库的状态发现显示为:
> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.127.0.91
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000226
Read_Master_Log_Pos: 506545322
Relay_Log_File: mysql-relay.000023
Relay_Log_Pos: 884805415
Relay_Master_Log_File: mysql-bin.000225
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1594
Last_Error: Relay log read failure: Could not parse relay log event entry. The possible reasons are: the master's
Skip_Counter: 0
Exec_Master_Log_Pos: 884805205
Relay_Log_Space: 1580224534
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1594
Last_SQL_Error: Relay log read failure: Could not parse relay log event entry. The possible reasons are: the master's
Replicate_Ignore_Server_Ids:
Master_Server_Id: 200
Master_UUID: 170281bc-1957-11e4-ad6e-842b2b4841e9
Master_Info_File: /U01/app/mysql_3306/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Master_Retry_Count: 86400
对于这个问题,stop slave,start slave是不会自动修复的。
可以使用change master来修复。
> stop slave;
Query OK, 0 rows affected (0.02 sec)
如果以前修复可以手工对应下标和日志来指定修复,但是在gtid的场景里,还是不需要这样了。
> change master to Master_Log_File='mysql-bin.000226', Master_Log_Pos=884805205;
ERROR 1776 (HY000): Parameters MASTER_LOG_FILE, MASTER_LOG_POS, RELAY_LOG_FILE and RELAY_LOG_POS cannot be set when MASTER_AUTO_POSITION is active.
> change master to master_host='10.127.0.xxx',master_port =3306,master_user='repl',master_password='xxxx',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.51 sec)
然后再次查看发现就开始缩小了日志差距,大概等了十几分钟之后,就追平了日志gap.
同一件事情总是会碰到这样许许多多的小问题,总是让人很操心,不过不总结不会进步啊。
首先是硬件问题。
如果看到下面的系统日志,就会发现早在2014年就出现了一些警告和问题,随后看似已经修复了部分,但是实际情况是这台服务器的电源已经坏了一个,另外一个已经快扛不住了。但是通过这些信息就很难读到之前的问题,因为问题已经过去了好久,一直没有问题,应该就是没有问题吧,或者之前的人已经处理了吧,如果这样想,是一种乐观的方式。
最好还是做一些确认,我就是那么想的,然后在某一天一台备库的服务器就突然殉职了。究其原因就是电源问题。
打开系统的ILO界面,才突然发现只识别了一个电源,而且已经无法正常开启电源了。
对于这类问题,还有一个想法就是,机器过就过老,更新换代如此频繁,还是有好的硬件配置就用上,很多时候都是感觉舍不得,动不得,如果你要迁移某个服务器,去和各个部门协调,总会有这个不能动,那个不能改的顾虑,但是服务器可不会讲这些情面,有时候**还是有道理的,这些问题也能够反应出来我们对待问题的态度,都是被动接受,而不是主动改进。出了问题之后发现这些必须得动,必须得改,感觉那个时候就有些匆忙,仓促了。
然后第二个问题,是一个表空间的迁移问题。
之前帮助开发的同事处理了一个表空间无法扩展的小case,然后建议他们后续进行硬盘扩容,从根本上解决这个问题,开发同事还真听进去了,申请了一块较大的硬盘,但是还是希望我来帮助他们来迁移这个表空间,这个问题其实很简单。
可以使用常规的方法即可,唯一的不同在于这个表空间是个bigfile tablespace,所以心里还是存在一点小小的顾虑,是否对于能够100%成功。
因为这个表空间的设置,里面只有一个数据文件,新的磁盘分区在/data下面。
在迁移的时候,开发的同事还是希望能够在线迁移,从我的大量实践来说,这些也都不是大的问题,然后使用了下面的脚本。
alter tablespace CYTJ_DATA offline;
!cp '/home/oracle/tablespace/cytj_data.dbf' '/data/cytj/datafile/cytj_data.dbf';
alter tablespace CYTJ_DATA rename datafile '/home/oracle/tablespace/cytj_data.dbf' to '/data/cytj/datafile/cytj_data.dbf';
alter tablespace CYTJ_DATA online;
当然拷贝大的文件,第二步花费了一些时间,其它步骤都是秒级完成。
迁移完了,还是有一些后续的补充工作的。
首先要删除原有的文件,再三确认之后,就可以删除了。
但是使用df -h发现,空间却压根没有释放,应该能够释放50多G才对。
#df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda5 4.0G 359M 3.4G 10% /
/dev/sda11 106G 96G 5.5G 95% /home
/dev/sdb1 551G 61G 463G 12% /data
对于这个问题,解决方法也比较简单,就是查看句柄的使用情况。
通过下面的命令可以看到迁移前和迁移后都存在一些句柄关联,哪些迁移前的文件已然被标示为deleted
#lsof |grep cytj_data.dbf
oracle 1536 oracle 263u REG 8,11 64424517632 2490413 /home/oracle/tablespace/cytj_data.dbf (deleted)
oracle 5427 oracle 262uW REG 8,17 64424517632 31719427 /data/cytj/datafile/cytj_data.dbf
oracle 5431 oracle 262u REG 8,17 64424517632 31719427 /data/cytj/datafile/cytj_data.dbf
oracle 5433 oracle 260u REG 8,17 64424517632 31719427 /data/cytj/datafile/cytj_data.dbf
oracle 6393 oracle 257u REG 8,17 64424517632 31719427 /data/cytj/datafile/cytj_data.dbf
oracle 8729 oracle 257u REG 8,11 64424517632 2490413 /home/oracle/tablespace/cytj_data.dbf (deleted)
oracle 8971 oracle 256u REG 8,11 64424517632 2490413 /home/oracle/tablespace/cytj_data.dbf (deleted)
oracle 9358 oracle 256u REG 8,11 64424517632 2490413 /home/oracle/tablespace/cytj_data.dbf (deleted)
以其中的一个进程为例,发现是一个应用连接。
#ps -ef|grep 1536
oracle 1536 1 0 18:07 ? 00:00:00 oraclecytj (LOCAL=NO)
root 6321 5715 0 22:48 pts/0 00:00:00 grep 1536
所以这些session还是对这个迁移造成了潜移默化的影响,我们需要释放这些句柄来,就可以kill掉了。
清理掉这些进程之后,再次查看就没有问题了。
#df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda11 106G 52G 50G 52% /home
/dev/sdb1 551G 61G 463G 12% /data
问题解决完了,还需要注意什么呢,需要设置这个数据文件的maxsize,这个分区目前有500G左右,所以大可以放心把它置为500G以内。原来的maxsize值是50G,差的还很远呢。
第三个问题是关于MySQL的从库问题。
因为之前有一台服务器因为硬件问题掉电,在补充了新的电源之后又开始正常工作了,但是查看从库的状态发现显示为:
> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.127.0.91
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000226
Read_Master_Log_Pos: 506545322
Relay_Log_File: mysql-relay.000023
Relay_Log_Pos: 884805415
Relay_Master_Log_File: mysql-bin.000225
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1594
Last_Error: Relay log read failure: Could not parse relay log event entry. The possible reasons are: the master's
Skip_Counter: 0
Exec_Master_Log_Pos: 884805205
Relay_Log_Space: 1580224534
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1594
Last_SQL_Error: Relay log read failure: Could not parse relay log event entry. The possible reasons are: the master's
Replicate_Ignore_Server_Ids:
Master_Server_Id: 200
Master_UUID: 170281bc-1957-11e4-ad6e-842b2b4841e9
Master_Info_File: /U01/app/mysql_3306/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Master_Retry_Count: 86400
对于这个问题,stop slave,start slave是不会自动修复的。
可以使用change master来修复。
> stop slave;
Query OK, 0 rows affected (0.02 sec)
如果以前修复可以手工对应下标和日志来指定修复,但是在gtid的场景里,还是不需要这样了。
> change master to Master_Log_File='mysql-bin.000226', Master_Log_Pos=884805205;
ERROR 1776 (HY000): Parameters MASTER_LOG_FILE, MASTER_LOG_POS, RELAY_LOG_FILE and RELAY_LOG_POS cannot be set when MASTER_AUTO_POSITION is active.
> change master to master_host='10.127.0.xxx',master_port =3306,master_user='repl',master_password='xxxx',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.51 sec)
然后再次查看发现就开始缩小了日志差距,大概等了十几分钟之后,就追平了日志gap.
同一件事情总是会碰到这样许许多多的小问题,总是让人很操心,不过不总结不会进步啊。