在语音识别领域,比较常用的两个模块就是librosa和python_speech_features了。
最近也是在做音乐方向的项目,借此做一下笔记,并记录一些两者的差别。下面是两模块的官方文档
LibROSA - librosa 0.6.3 documentationlibrosa.github.ioWelcome to python_speech_features’s documentation!python-speech-features.readthedocs.io直接对比两文档就可以看出librosa功能十分强大,涉及到了音频的特征提取、谱图分解、谱图显示、顺序建模、创建音频等功能,而python_speech_features只涉及了音频特征提取。就特征提取的实现方法和种类来看,两者也有所不同。
python_speech_features的特征
支持的特征:
- python_speech_features.mfcc() - 梅尔倒谱系数
- python_speech_features.fbank() - 滤波器组能量
- python_speech_features.logfbank() - 对数滤波器组能量
- python_speech_features.ssc() - 子带频谱质心特征
提取mfcc、logfbank特征的方法
from python_speech_features import mfcc
from python_speech_features import logfbank
import scipy.io.wavfile as wav(rate,sig) = wav.read("file.wav") # 返回信号的采样率以及信号数组ndarray
mfcc_feat = mfcc(sig,rate) # 返回一个二维ndarray数组
fbank_feat = logfbank(sig,rate) # 返回一个二维ndarray数组print(fbank_feat[1:3,:])python_speech_features的比较好用的地方就是自带预加重参数,只需要设定preemph的值,就可以对语音信号进行预加重,增强高频信号。
python_speech_features模块提供的函数
python_speech_features.base.mfcc(signal, samplerate=16000, winlen=0.025, winstep=0.01, numcep=13, nfilt=26, nfft=512, lowfreq=0, highfreq=None, preemph=0.97, ceplifter=22, appendEnergy=True, winfunc=<function <lambda>>)
计算一个音频信号的MFCC特征
返回: 一个大小为numcep的numpy数组,包含着特征,每一行都包含一个特征向量。
参数:
signal - 需要用来计算特征的音频信号,应该是一个N*1的数组
samplerate - 我们用来工作的信号的采样率
winlen - 分析窗口的长度,按秒计,默认0.025s(25ms)
winstep - 连续窗口之间的步长,按秒计,默认0.01s(10ms)
numcep - 倒频谱返回的数量,默认13
nfilt - 滤波器组的滤波器数量,默认26
nfft - FFT的大小,默认512
lowfreq - 梅尔滤波器的最低边缘,单位赫兹,默认为0
highfreq - 梅尔滤波器的最高边缘,单位赫兹,默认为采样率/2
preemph - 应用预加重过滤器和预加重过滤器的系数,0表示没有过滤器,默认0.97
ceplifter - 将升降器应用于最终的倒谱系数。 0没有升降机。默认值为22。
appendEnergy - 如果是true,则将第0个倒谱系数替换为总帧能量的对数。
winfunc - 分析窗口应用于每个框架。 默认情况下不应用任何窗口。 你可以在这里使用numpy窗口函数 例如:winfunc=numpy.hamming
python_speech_features.base.fbank(signal, samplerate=16000, winlen=0.025, winstep=0.01, nfilt=26, nfft=512, lowfreq=0, highfreq=None, preemph=0.97, winfunc=<function <lambda>>)
从一个音频信号中计算梅尔滤波器能量特征
返回:2个值。第一个是一个包含着特征的大小为nfilt的numpy数组,每一行都有一个特征向量。第二个返回值是每一帧的能量
python_speech_features.base.logfbank(signal, samplerate=16000, winlen=0.025, winstep=0.01, nfilt=26, nfft=512, lowfreq=0, highfreq=None, preemph=0.97)
从一个音频信号中计算梅尔滤波器能量特征的对数
返回: 一个包含特征的大小为nfilt的numpy数组,每一行都有一个特征向量
python_speech_features.base.ssc(signal, samplerate=16000, winlen=0.025, winstep=0.01, nfilt=26, nfft=512, lowfreq=0, highfreq=None, preemph=0.97, winfunc=<function <lambda>>)
从一个音频信号中计算子带频谱质心特征
返回:一个包含特征的大小为nfilt的numpy数组,每一行都有一个特征向量
librosa的特征提取
librosa的可以提取的特征种类十分丰富
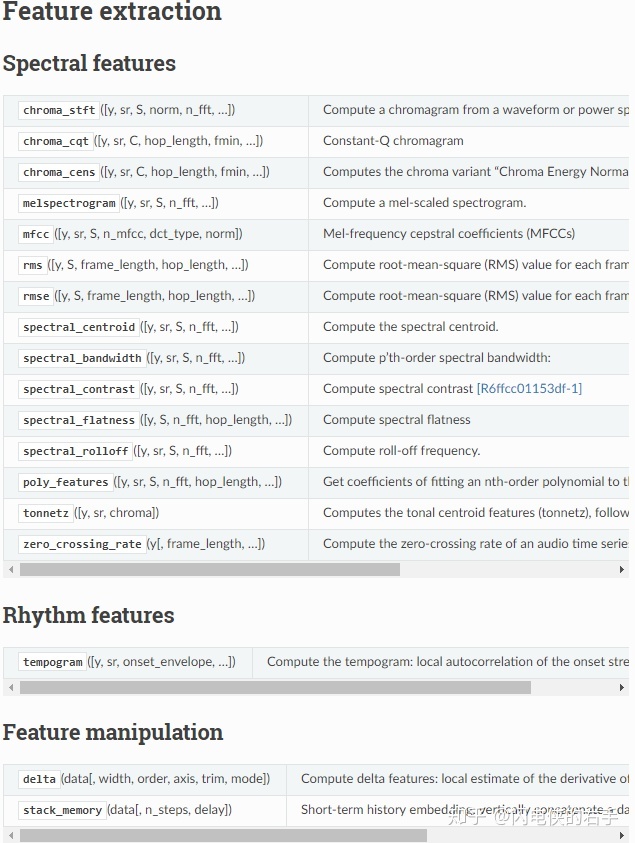
篇幅原因不多介绍
librosa.features.mfcc(y=None,sr=22050,S=None,n_mfcc=20,dct_type=2,norm='ortho',**kwargs)
y, sr = librosa.load('test.wav',offset=30, duration=5)
librosa.feature.mfcc(y=y, sr=sr, n_mfcc=40) # 返回shape=(n_mfcc, timestep)的二维矩阵librosa.feature.spectral_centroid(y=None,sr=22050,S=None,n_fft=2048,hop_length=512,freq=None)
计算频谱质心
>>> y, sr = librosa.load('test.wav')
>>> cent = librosa.feature.spectral_centroid(y=y, sr=sr)
>>> cent
array([[ 4382.894, 626.588, ..., 5037.07 , 5413.398]])蓝调音乐的频谱质心在频谱偏中心的位置,金属音乐在靠后的位置
librosa.feature.zero_crossing_rate(y,frame_length=2048,hop_length=512,center=True,**kwargs)
计算过零率
>>> y, sr = librosa.load('test.wav')
>>> librosa.feature.zero_crossing_rate(y)
array([[ 0.134, 0.139, ..., 0.387, 0.322]])相对于python_speech_features来说,librosa没有预加重的处理。或者说librosa提供自定义预加重功能。
预加重的一般传递函数为
差分方程实现预加重的方程为



)
 - 图像复原与重建10 - 空间滤波 - 统计排序滤波器 - 中值、最大值、最小值、中点、修正阿尔法均值滤波器)





 - 图像复原与重建11 - 空间滤波 - 自适应滤波器 - 自适应局部降噪、自适应中值滤波器)





 - 图像复原与重建12 - 空间滤波 - 使用频率域滤波降低周期噪声 - 陷波滤波、最优陷波滤波)


