1.必须知道的两组Python基础术语
A.变量和赋值
Python可以直接定义变量名字并进行赋值的,例如我们写出a = 4时,Python解释器干了两件事情:
- 在内存中创建了一个值为4的整型数据
- 在内存中创建了一个名为a的变量,并把它指向4
用一张示意图表示Python变量和赋值的重点:
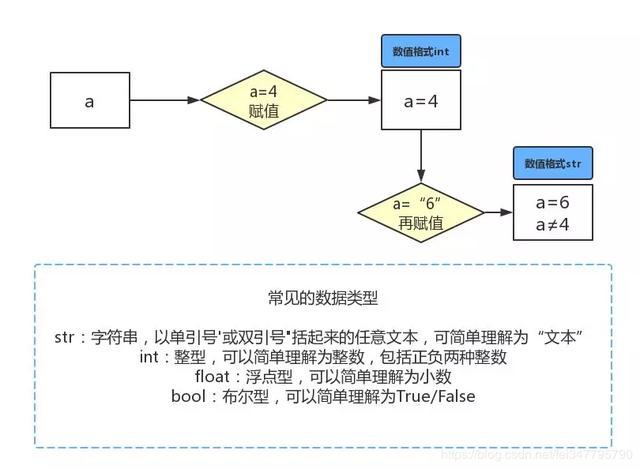
例如下图代码,“=”的作用就是赋值,同时Python会自动识别数据类型:
请阅读代码块里的代码和注释,你会发现Python是及其易读易懂的。
B.数据类型
在初级的数据分析过程中,有三种数据类型是很常见的:
- 列表list(Python内置)
- 字典dic(Python内置)
- DataFrame(工具包pandas下的数据类型,需要import pandas才能调用)
它们分别是这么写的:
列表(list):
list是一种有序的集合,里面的元素可以是之前提到的任何一种数据格式和数据类型(整型、浮点、列表……),并可以随时指定顺序添加其中的元素,其形式是:
字典(dict):
字典使用键-值(key-value)存储,无序,具有极快的查找速度。以上面的字典为例,想要快速知道周杰伦的年龄,就可以这么写:
dict内部存放的顺序和key放入的顺序是没有关系的,也就是说,"章泽天"并非是在"刘强东"的后面。
DataFrame:
DataFrame可以简单理解为Excel里的表格格式。导入pandas包后,字典和列表都可以转化为DataFrame,以上面的字典为例,转化为DataFrame是这样的:
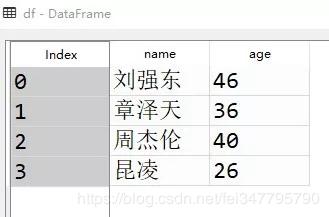
和excel一样,DataFrame的任何一列或任何一行都可以单独选出进行分析。
以上三种数据类型是python数据分析中用的最多的类型,基础语法到此结束,接下来就可以着手写一些函数计算数据了。
从Python爬虫学循环函数
掌握了以上基本语法概念,我们就足以开始学习一些有趣的函数。我们以爬虫中绕不开的遍历url为例,讲讲大家最难理解的循环函数for的用法:
A.for函数
for函数是一个常见的循环函数,先从简单代码理解for函数的用途:
因为dict的存储不是按照list的方式顺序排列,所以,迭代出的结果顺序很可能不是每次都一样。默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时#迭代key和value,可以用for k, v in d.items()
可以看到,字典里的人名被一一打印出来了。for 函数的作用就是用于遍历数据。掌握for函数,可以说是真正入门了Python函数。
B.爬虫和循环
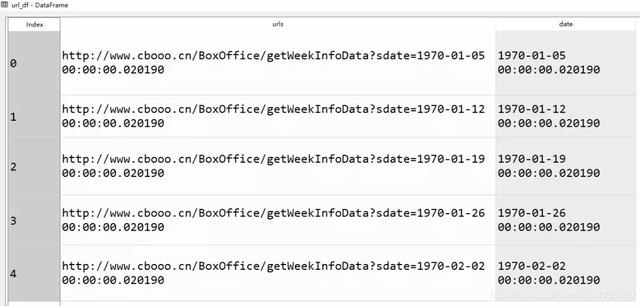
for函数在书写Python爬虫中经常被应用,因为爬虫经常需要遍历每一个网页,以获取信息,所以构建完整而正确的网页链接十分关键。以某票房数据网为例,他的网站信息长这样:
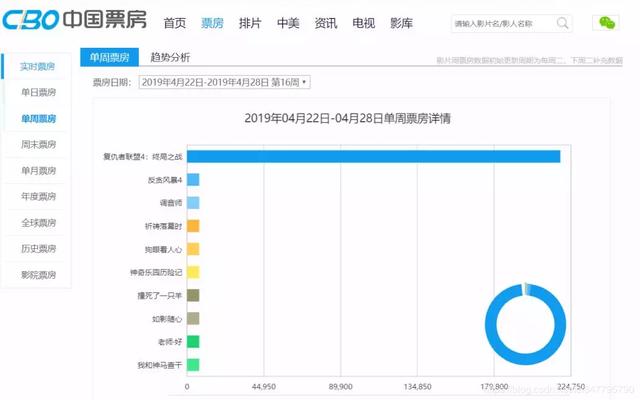

该网站的周票房json数据地址可以通过抓包工具找到,网址为http://www.cbooo.cn/BoxOffice/getWeekInfoData?sdate=20190114
仔细观察,该网站不同日期的票房数据网址(url)只有后面的日期在变化,访问不同的网址(url)就可以看到不同日期下的票房数据:

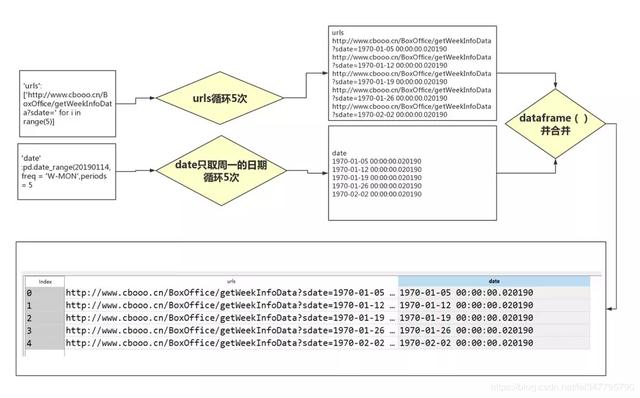
我们要做的是,遍历每一个日期下的网址,用Python代码把数据爬下来。此时for函数就派上用场了,使用它我们可以快速生成多个符合条件的网址:
为了方便理解,我给大家画了一个for函数的遍历过程示意图:
3.Python怎么实现数据分析?
A.Python分析
在做好数据采集和导入后,选择字段进行初步分析可以说是数据分析的必经之路。在Dataframe数据格式的帮助下,这个步骤变得很简单。
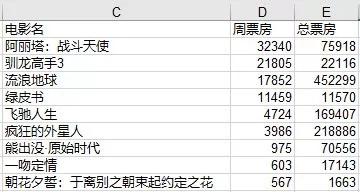
比如当我们想看单周票房第一的排名分别都是哪些电影时,可以使用pandas工具库中常用的方法,筛选出周票房为第一名的所有数据,并保留相同电影中周票房最高的数据进行分析整理:
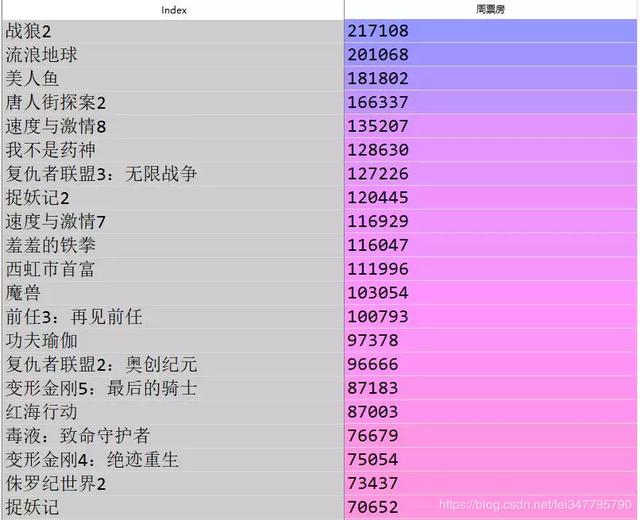
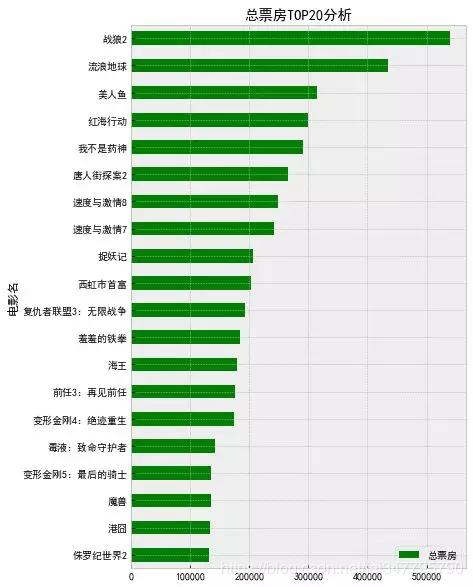
9行代码,我们完成了Excel里的透视表、拖动、排序等鼠标点击动作。最后再用Python中的可视化包matplotlib,快速出图:
B.函数化分析
以上是一个简单的统计分析过程。接下来就讲讲Excel基础功能不能做的事——自定义函数提效。观察数据可以发现,数据中记录了周票房和总票房的排名,那么刚刚计算了周票房排名的代码,还能不能复用做一张总票房分析呢?
当然可以,只要使用def函数和刚刚写好的代码建立自定义函数,并说明函数规则即可:
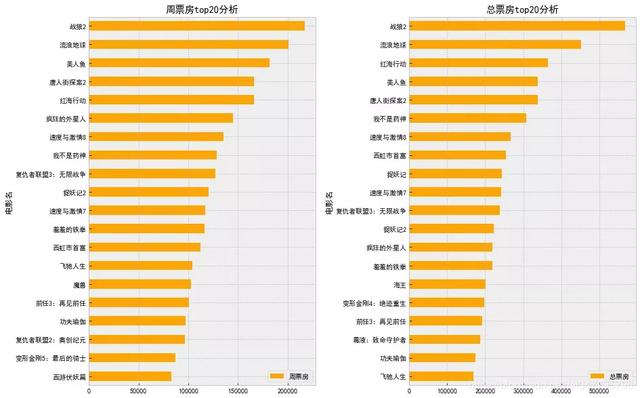
学会函数的构建,一个数据分析师才算真正能够告别Excel的鼠标点击模式,迈入高效分析的领域。
 - 图像复原与重建12 - 空间滤波 - 使用频率域滤波降低周期噪声 - 陷波滤波、最优陷波滤波)






 - 图像复原与重建13 - 空间滤波 - 线性位置不变退化 - 退化函数估计、运动模糊函数)



 - 图像复原与重建14 - 逆滤波)
窗体全屏显示)



 - 图像复原与重建15 - 最小均方误差(维纳)滤波)

