NoSQL分类
由于NoSQL中没有像传统数据库那样定义数据的组织方式为关系型的,所以只要内部的数据组织采用了非关系型的方式,就可以称之为NoSQL数据库。
目前,可以将众多的NoSQL数据库按照内部的数据组织形式进行如下分类:
- Key/Value的NoSQL数据库
- 面向文档的NoSQL数据库
- 面向列的NoSQL数据库
- 面向图的NoSQL数据库
不同的数据组织适合于不同的应用场景,后面将进行介绍。
为什么要使用NoSQL
SQL语言和关系型数据库(My SQL、PostgreSQL、Oracle等) 是通用的数据解决方案,占有绝大多数的市场。不过在最近兴起的NoSQL运动中,涌现出一批具备高可用性、支持线性扩展、支持Map/Reduce操作等特性的数据产品,它们具有如下特性:
- 频繁的写入操作、相对较少的读取统计信息的操作(如网站访问计数器),应该使用基于内存的Key/Value(键/值)存储系统(如redis) 或者是具备本地更新特性的文档存储系统(如MongoDB)。
- 海量数据(如数据仓库中需要分析的数据) 适合存储在一个结构松散、分布式的文件存储系统中,如Hadoop。
- 存储二进制文件(如mp3或者pdf文档) 并且能够直接为用户的浏览器提供下载功能,可以使用Amazon S3。
- 临时性的数据(如网站的session、缓存HTML页面信息等) 适合存储在Memcache中。
- 如果希望数据具备高可用性,并且能够将数据丢失的风险降到最低,同时整个系统具备线性扩展的能力,可以考虑使用Cassandra和HBase。
Key/Value的NoSQL库
1 memcached
memcached是国外社区网站LiveJournal开发的高性能的内存Key/Value缓存服务器,目的是通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度,从而提高系统的可扩展性。
2 redis
redis是一款先进的Key/Value存储系统。它与Memcached类似,区别如下:
redis不仅支持简单的Key/Value类型的数据,同时还提供list、set、hash等数据结构的存储。
redis支持数据的备份,即master slave模式的数据备份。
redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候再次加载进行使用。
在redis中,并不是所有的数据都一直存储在内存中。redis只会缓存所有的Key的信息,如果redis发现内存的使用量超过了某个阈值,将触发交换(swap) 的操作。redis根据“swappabillity=age*log(size_in_memory)” 计算出哪些Key对应的Value需要交换到磁盘,然后再将这些key对应的value持久化到磁盘中,同时在内存中清除。这种特性使得redis可以保持超过其机器本身内存大小的数据。当然,机器本身的内存必须要能够保持所有的key,毕竟这些数据是不会进行交换操作的。同时由于redis将内存中的数据交换到磁盘中的时候,提供服务的主线程和进行交换操作的子线程会共享这部分内存,所以如果更新需要交换的数据,redis将阻塞这个操作,直到子线程完成交换操作后才可以进行修改。
3 Dynamo
Dynamo是亚马逊公司开发的一款分布式Key/Value存储系统,用于存储用户的购物车信息。Dynamo与传统的Key/Value存储系统相比,最大的优势在于无单点故障,整个系统的可用性非常高,同时具备数据的最终一致性。
面向文档的NoSQL数据库
1 MongoDB
MongoDB是一个高性能、开源、模式自由(schma free) 的文档型数据库,它在许多场景下可用于替代传统的关系型数据库或Key/Value存储方式。MongoDB使用C++开发,具有以下特性:
- 面向文档的存储,适合存储对象及JSON形式的数据。
- 动态查询,MongoDB支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- 完整的索引支持,包括文档内嵌对象及数组。MongoDB的查询优化器会分析查询表达式,并生成一个高效的查询计划。
- 查询监视,MongoDB包含一个监视工具用于分析数据库操作的性能。
- 复制及自动故障转移,MongoDB数据库支持服务器之间的数据复制,支持主-从模式(Master/Slave)及服务器之间的相互复制。复制的主要目标是提供冗余及自动故障转移。
- 高效的传统存储方式,支持二进制数据及大型对象(如照片或图片)。
- 自动分片以支持云级别的伸缩性,自动分片功能支持水平的数据库集群,可动态添加额外的机器。
- 模式自由,意味着对于存储在MongoDB数据库中的文件,我们不需要知道它的任何结构定义。
- 支持Map/Reduce计算,代表MongoDB具有强大的数据分析能力。
2 CouchDB
CouchDB是Apache社区中的一款文档型数据库服务器。与现在流行的关系数据库服务器不同,CouchDB是围绕一系列语义上自包含的文档而组织的。CouchDB中的文档是模式自由的,也就是说,并不要求文档具有某种特定的结构。CouchDB的这种特性使得它相对于传统的关系数据库而言,有自己的适用范围。一般来说,围绕文档来构建的应用都比较适合使用CouchDB作为其后台存储。CouchDB强调其中所存储的文档,在语义上是自包含的。这种面向文档的设计思路,更贴近很多应用的问题域的真实情况。对于这类应用,使用CouchDB的文档来进行建模,会更加自然和简单。与此同时,CouchDB也提供基于Map/Reduce编程模型的视图来对文档进行查询,可以提供类似于关系数据库中SQL语句的能力。CouchDB对于很多应用来说,提供了关系数据库之外的更好的选择。
面向列的NoSQL数据库
1 Cassandra
Cassandra是一款面向列的NoSQL数据库,和Google的Bigtable数据库属于同一类。此数据库比一个类似Dynamo的Key/Value数据库功能更多,但相比于面向文档的数据库(如MongoDB),它所支持的查询类型要少。
- Cassandra结合了Dynamo的Key/Value与Bigtable的面向列的特点。
- 模式灵活:数据不需要像数据库一样使用预先设计的模式,增加或者删除字段非常方便(onthefly)。
- 支持范围查询:可以对任意Key进行范围查询。
- 支持二级索引查询:可以对任意列(Column)的值进行查询。
- 支持Map/Reduce计算:可以对Cassandra中的数据批量进行复杂的分析计算。
- 数据具备最终一致性,集群整体的可用性非常高。
- 高可用,可扩展:单点故障不影响集群服务,集群的性能可线性扩展。
- 数据可靠性高:一旦数据写入成功,数据就已经在机器的磁盘中完成了存储,不容易丢失。
HBase
HBase是Hadoop项目中的数据库。它用于需要对大量的数据进行随机、实时的读写操作的场景中。HBase的目标就是处理数据量非常庞大的表,可以用普通的计算机处理超过10亿行数据,还可处理有数百万列元素的数据表。
HBase是一个开源的、分布式的、支持多版本的、面向列存储的GoogleBigtable实现。
HBase的实现基于Hadoop分布式文件系统(HDFS),模仿并提供了基于Google文件系统的Bigtable数据库的所有功能。HBase有如下特点:
- 可以直接从HBase中读取数据运行Map/Reduce任务,并可以将运行后的结果直接写入HBase中。
- 数据查询过滤和扫描操作在服务器端进行。
- 为实时查询做了特殊优化。
- 使用高性能的Thrift通信框架。
- 支持REST、Protobuf以及二进制形式的数据交互。
- 可以与Cascading、Hive和Pig配合使用,从而提高使用的效率。
- 提供可扩展的JRuby(JIRB)的命令行工具。
- 支持Ganglia和JMX,能够方便监视整个程序的运行状态。
面向图的NoSQL数据库
Neo4J是一个用Java实现、完全兼容ACID的图形数据库。数据以一种针对图形网络进行过优化的格式保存在磁盘上。Neo4J的内核是一种极快的图形引擎,具有数据库产品期望的所有特性,如恢复、两阶段提交、符合XA等。自2003年起,Neo4J就已经作为724的产品使用。该项目已经发布了12版,它是关于伸缩性和社区测试的一个主要里程碑。通过联机备份实现的高可用性和主从复制功能目前处于测试阶段,预计在下一版本中发布。Neo4J既可作为无须任何管理开销的内嵌数据库使用,也可以作为单独的服务器使用,在这种使用场景下,它提供了广泛使用的REST接口,能够方便地集成到基于PHP、NET和JavaScript的环境里。
Neo4J的特点如下:
- 用直观的图模型取代了严格定义的表模型,从而可以使用节点(node)、关系(relationship)、属性(property)来表达复杂的数据模型,如图1-2所示。
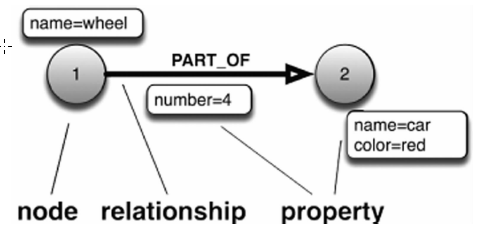
- 针对磁盘存储进行了特殊优化,使得其具备优异的性能和可扩展性。
- 每一台Neo4J服务器都可以处理上10亿的数据,并且可以通过水平拆分支持更大的数据量。
- 包含高效的图遍历算法,大大提高了数据的查询和分析能力。
- 程序本身非常简单小巧,核心功能的Jar包大小只有500KB。
- 具备简单好用的编程接口,方便程序的开发。
示例:
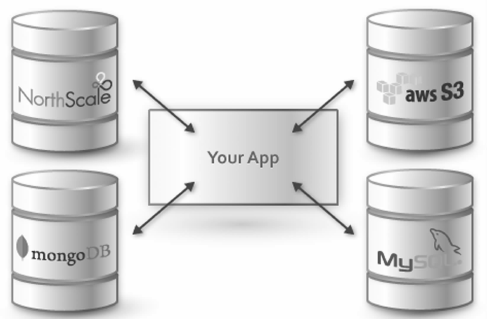
如图1-1所示,可以在一个网站中使用4款数据产品来提供服务。
- My SQL用于存储敏感的数据,比如用户的资料、交易的信息等。
- MongoDB用于存储大量的、相对不敏感的数据,比如博客文章的内容、文章访问次数等。
- Amazon S3用于存储用户上传的文档、图片、音乐等数据。
- Memcached用于存储临时性的信息,比如缓存HTML页面等。
选择多样的数据存储方案同样有利于提升我们对NoSQL的数据产品的理解,帮助我们从大量的解决方案中选择最适用的产品,而不是把眼光仅仅放在某一款产品上。
核心的思想是:最适用的才是最好的。
Redis与Memcached的比较
1、Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等,而Redis,并不是所有的数据都一直存储在内存中的。
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3、虚拟内存--Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
4、过期策略--memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10
5、分布式--设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从
6、存储数据安全--memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化),重启的时候可以再次加载进行使用。
7、灾难恢复--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
8、Redis支持数据的备份,即master-slave模式的数据备份
Redis在很多方面具备数据库的特征,或者说就是一个数据库系统,而Memcached只是简单的K/V缓存
实现原理等不同:
- 网络IO模型
Memcached是多线程,非阻塞IO复用的网络模型,分为监听主线程和worker子线程,监听线程监听网络连接,接受请求后,将连接描述字pipe 传递给worker线程,进行读写IO, 网络层使用libevent封装的事件库,多线程模型可以发挥多核作用,但是引入了cache coherency和锁的问题,比如,Memcached最常用的stats 命令,实际Memcached所有操作都要对这个全局变量加锁,进行计数等工作,带来了性能损耗。
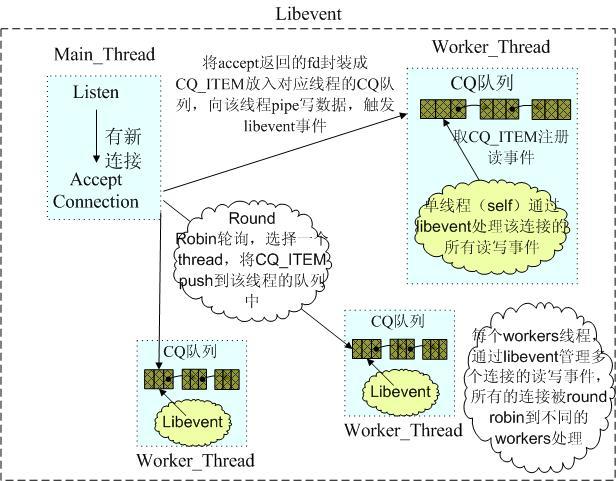
(Memcached网络IO模型)
Redis使用单线程的IO复用模型,自己封装了一个简单的AeEvent事件处理框架,主要实现了epoll、kqueue和select,对于单纯只有IO操作来说,单线程可以将速度优势发挥到最大,但是Redis也提供了一些简单的计算功能,比如排序、聚合等,对于这些操作,单线程模型实际会严重影响整体吞吐量,CPU计算过程中,整个IO调度都是被阻塞住的。
- 内存管理方面
Memcached使用预分配的内存池的方式,使用slab和大小不同的chunk来管理内存,Item根据大小选择合适的chunk存储,内存池的方式可以省去申请/释放内存的开销,并且能减小内存碎片产生,但这种方式也会带来一定程度上的空间浪费,并且在内存仍然有很大空间时,新的数据也可能会被剔除,原因可以参考Timyang的文章:http://timyang.net/data/Memcached-lru-evictions/
Redis使用现场申请内存的方式来存储数据,并且很少使用free-list等方式来优化内存分配,会在一定程度上存在内存碎片,Redis跟据存储命令参数,会把带过期时间的数据单独存放在一起,并把它们称为临时数据,非临时数据是永远不会被剔除的,即便物理内存不够,导致swap也不会剔除任何非临时数据(但会尝试剔除部分临时数据),这点上Redis更适合作为存储而不是cache。
- 数据一致性问题
Memcached提供了cas命令,可以保证多个并发访问操作同一份数据的一致性问题。 Redis没有提供cas 命令,并不能保证这点,不过Redis提供了事务的功能,可以保证一串 命令的原子性,中间不会被任何操作打断。
- 存储方式及其它方面
Memcached基本只支持简单的key-value存储,不支持枚举,不支持持久化和复制等功能
Redis除key/value之外,还支持list,set,sorted set,hash等众多数据结构,提供了KEYS
进行枚举操作,但不能在线上使用,如果需要枚举线上数据,Redis提供了工具可以直接扫描其dump文件,枚举出所有数据,Redis还同时提供了持久化和复制等功能。
- 关于不同语言的客户端支持
在不同语言的客户端方面,Memcached和Redis都有丰富的第三方客户端可供选择,不过因为Memcached发展的时间更久一些,目前看在客户端支持方面,Memcached的很多客户端更加成熟稳定,而Redis由于其协议本身就比Memcached复杂,加上作者不断增加新的功能等,对应第三方客户端跟进速度可能会赶不上,有时可能需要自己在第三方客户端基础上做些修改才能更好的使用。
根据以上比较不难看出,当我们不希望数据被踢出,或者需要除key/value之外的更多数据类型时,或者需要落地功能时,使用Redis比使用Memcached更合适。
关于Redis的一些周边功能
Redis除了作为存储之外还提供了一些其它方面的功能,比如聚合计算、pubsub、scripting等,对于此类功能需要了解其实现原理,清楚地了解到它的局限性后,才能正确的使用,比如pubsub功能,这个实际是没有任何持久化支持的,消费方连接闪断或重连之间过来的消息是会全部丢失的,又比如聚合计算和scripting等功能受Redis单线程模型所限,是不可能达到很高的吞吐量的,需要谨慎使用。
总的来说Redis作者是一位非常勤奋的开发者,可以经常看到作者在尝试着各种不同的新鲜想法和思路,针对这些方面的功能就要求我们需要深入了解后再使用。
总结:
- Redis使用最佳方式是全部数据in-memory。
- Redis更多场景是作为Memcached的替代者来使用。
- 当需要除key/value之外的更多数据类型支持时,使用Redis更合适。
- 当存储的数据不能被剔除时,使用Redis更合适。
后续关于Redis文章计划:
- Redis数据类型与容量规划。
- 如何根据业务场景搭建稳定,可靠,可扩展的Redis集群。
- Redis参数,代码优化及二次开发基础实践。
最近项目组有用到这三个缓存,去各自的官方看了下,觉得还真的各有千秋!今天特意归纳下各个缓存的优缺点,仅供参考!
Ehcache
在java项目广泛的使用。它是一个开源的、设计于提高在数据从RDBMS中取出来的高花费、高延迟采取的一种缓存方案。正因为Ehcache具有健壮性(基于java开发)、被认证(具有apache 2.0 license)、充满特色(稍后会详细介绍),所以被用于大型复杂分布式web application的各个节点中。
什么特色?
1. 够快
Ehcache的发行有一段时长了,经过几年的努力和不计其数的性能测试,Ehcache终被设计于large, high concurrency systems.
2. 够简单
开发者提供的接口非常简单明了,从Ehcache的搭建到运用运行仅仅需要的是你宝贵的几分钟。其实很多开发者都不知道自己用在用Ehcache,Ehcache被广泛的运用于其他的开源项目
比如:hibernate
3.够袖珍
关于这点的特性,官方给了一个很可爱的名字small foot print ,一般Ehcache的发布版本不会到2M,V 2.2.3 才 668KB。
4. 够轻量
核心程序仅仅依赖slf4j这一个包,没有之一!
5.好扩展
Ehcache提供了对大数据的内存和硬盘的存储,最近版本允许多实例、保存对象高灵活性、提供LRU、LFU、FIFO淘汰算法,基础属性支持热配置、支持的插件多
6.监听器
缓存管理器监听器 (CacheManagerListener)和 缓存监听器(CacheEvenListener),做一些统计或数据一致性广播挺好用的
如何使用?
够简单就是Ehcache的一大特色,自然用起来just so easy!
贴一段基本使用代码
CacheManager manager = CacheManager.newInstance("src/config/ehcache.xml");
Ehcache cache = new Cache("testCache", 5000, false, false, 5, 2);
cacheManager.addCache(cache); 代码中有个ehcache.xml文件,现在来介绍一下这个文件中的一些属性
name:缓存名称。maxElementsInMemory:缓存最大个数。eternal:对象是否永久有效,一但设置了,timeout将不起作用。timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。timeToLiveSeconds:设置对象在失效前允许存活时间,最大时间介于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默认是0.,也就是对象存活时 间无穷大。overflowToDisk:当内存中对象数量达到maxElementsInMemory时,Ehcache将会对象写到磁盘中。diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。maxElementsOnDisk:硬盘最大缓存个数。diskPersistent:是否缓存虚拟机重启期数据 Whether the disk store persists between restarts of the Virtual Machine. The default value is false.diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU。你可以设置为 FIFO或是LFU。clearOnFlush:内存数量最大时是否清除。
memcache
memcache 是一种高性能、分布式对象缓存系统,最初设计于缓解动态网站数据库加载数据的延迟性,你可以把它想象成一个大的内存HashTable,就是一个key-value键值缓存。Danga Interactive为了LiveJournal所发展的,以BSD license释放的一套开放源代码软件。
1.依赖
memcache C语言所编写,依赖于最近版本的GCC和libevent。GCC是它的编译器,同事基于libevent做socket io。在安装memcache时保证你的系统同事具备有这两个环境。
2.多线程支持
memcache支持多个cpu同时工作,在memcache安装文件下有个叫threads.txt中特别说明,By default, memcached is compiled as a single-threaded application.默认是单线程编译安装,如果你需要多线程则需要修改./configure --enable-threads,为了支持多核系统,前提是你的系统必须具有多线程工作模式。开启多线程工作的线程数默认是4,如果线程数超过cpu数容易发生操作死锁的概率。结合自己业务模式选择才能做到物尽其用。
3.高性能
通过libevent完成socket 的通讯,理论上性能的瓶颈落在网卡上。
简单安装:
1.分别把memcached和libevent下载回来,放到 /tmp 目录下:
# cd /tmp
# wget http://www.danga.com/memcached/dist/memcached-1.2.0.tar.gz
# wget http://www.monkey.org/~provos/libevent-1.2.tar.gz

2.先安装libevent:
# tar zxvf libevent-1.2.tar.gz
# cd libevent-1.2
# ./configure -prefix=/usr
# make (如果遇到提示gcc 没有安装则先安装gcc)
# make install
3.测试libevent是否安装成功:
# ls -al /usr/lib | grep libevent
lrwxrwxrwx 1 root root 21 11?? 12 17:38 libevent-1.2.so.1 -> libevent-1.2.so.1.0.3
-rwxr-xr-x 1 root root 263546 11?? 12 17:38 libevent-1.2.so.1.0.3
-rw-r-r- 1 root root 454156 11?? 12 17:38 libevent.a
-rwxr-xr-x 1 root root 811 11?? 12 17:38 libevent.la
lrwxrwxrwx 1 root root 21 11?? 12 17:38 libevent.so -> libevent-1.2.so.1.0.3
还不错,都安装上了。
4.安装memcached,同时需要安装中指定libevent的安装位置:
# cd /tmp
# tar zxvf memcached-1.2.0.tar.gz
# cd memcached-1.2.0
# ./configure -with-libevent=/usr
# make
# make install
如果中间出现报错,请仔细检查错误信息,按照错误信息来配置或者增加相应的库或者路径。
安装完成后会把memcached放到 /usr/local/bin/memcached ,
5.测试是否成功安装memcached:
# ls -al /usr/local/bin/mem*
-rwxr-xr-x 1 root root 137986 11?? 12 17:39 /usr/local/bin/memcached
-rwxr-xr-x 1 root root 140179 11?? 12 17:39 /usr/local/bin/memcached-debug
启动Memcached服务:
1.启动Memcache的服务器端:
# /usr/local/bin/memcached -d -m 8096 -u root -l 192.168.77.105 -p 12000 -c 256 -P /tmp/memcached.pid
-d选项是启动一个守护进程,
-m是分配给Memcache使用的内存数量,单位是MB,我这里是8096MB,
-u是运行Memcache的用户,我这里是root,
-l是监听的服务器IP地址,如果有多个地址的话,我这里指定了服务器的IP地址192.168.77.105,
-p是设置Memcache监听的端口,我这里设置了12000,最好是1024以上的端口,
-c选项是最大运行的并发连接数,默认是1024,我这里设置了256,按照你服务器的负载量来设定,
-P是设置保存Memcache的pid文件,我这里是保存在 /tmp/memcached.pid,
2.如果要结束Memcache进程,执行:
# cat /tmp/memcached.pid 或者 ps -aux | grep memcache (找到对应的进程id号)
# kill 进程id号
也可以启动多个守护进程,不过端口不能重复。
memcache 的连接
telnet ip port
注意连接之前需要再memcache服务端把memcache的防火墙规则加上
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 3306 -j ACCEPT
重新加载防火墙规则
service iptables restart
OK ,现在应该就可以连上memcache了
在客户端输入stats 查看memcache的状态信息

pid memcache服务器的进程ID
uptime 服务器已经运行的秒数
time 服务器当前的unix时间戳
version memcache版本
pointer_size 当前操作系统的指针大小(32位系统一般是32bit)
rusage_user 进程的累计用户时间
rusage_system 进程的累计系统时间
curr_items 服务器当前存储的items数量
total_items 从服务器启动以后存储的items总数量
bytes 当前服务器存储items占用的字节数
curr_connections 当前打开着的连接数
total_connections 从服务器启动以后曾经打开过的连接数
connection_structures 服务器分配的连接构造数
cmd_get get命令 (获取)总请求次数
cmd_set set命令 (保存)总请求次数
get_hits 总命中次数
get_misses 总未命中次数
evictions 为获取空闲内存而删除的items数(分配给memcache的空间用满后需要删除旧的items来得到空间分配给新的items)
bytes_read 读取字节数(请求字节数)
bytes_written 总发送字节数(结果字节数)
limit_maxbytes 分配给memcache的内存大小(字节)
threads 当前线程数
redis
redis是在memcache之后编写的,大家经常把这两者做比较,如果说它是个key-value store 的话但是它具有丰富的数据类型,我想暂时把它叫做缓存数据流中心,就像现在物流中心那样,order、package、store、classification、distribute、end。现在还很流行的LAMP PHP架构 不知道和 redis+mysql 或者 redis + mongodb的性能比较(听群里的人说mongodb分片不稳定)。
先说说reidis的特性
1. 支持持久化
redis的本地持久化支持两种方式:RDB和AOF。RDB 在redis.conf配置文件里配置持久化触发器,AOF指的是redis每增加一条记录都会保存到持久化文件中(保存的是这条记录的生成命令),如果不是用redis做DB用的话还会不要开AOF ,数据太庞大了,重启恢复的时候是一个巨大的工程!
2.丰富的数据类型
redis 支持 String 、Lists、sets、sorted sets、hashes 多种数据类型,新浪微博会使用redis做nosql主要也是它具有这些类型,时间排序、职能排序、我的微博、发给我的这些功能List 和 sorted set 的强大操作功能息息相关
3.高性能
这点跟memcache很相像,内存操作的级别是毫秒级的比硬盘操作秒级操作自然高效不少,较少了磁头寻道、数据读取、页面交换这些高开销的操作!这也是NOSQL冒出来的原因吧,应该是高性能是基于RDBMS的衍生产品,虽然RDBMS也具有缓存结构,但是始终在app层面不是我们想要的那么操控的。
4.replication
redis提供主从复制方案,跟mysql一样增量复制而且复制的实现都很相似,这个复制跟AOF有点类似复制的是新增记录命令,主库新增记录将新增脚本发送给从库,从库根据脚本生成记录,这个过程非常快,就看网络了,一般主从都是在同一个局域网,所以可以说redis的主从近似及时同步,同事它还支持一主多从,动态添加从库,从库数量没有限制。 主从库搭建,我觉得还是采用网状模式,如果使用链式(master-slave-slave-slave-slave·····)如果第一个slave出现宕机重启,首先从master 接收数据恢复脚本,这个是阻塞的,如果主库数据几TB的情况恢复过程得花上一段时间,在这个过程中其他的slave就无法和主库同步了。
5.更新快
这点好像从我接触到redis到目前为止 已经发了大版本就4个,小版本没算过。redis作者是个非常积极的人,无论是邮件提问还是论坛发帖,他都能及时耐心的为你解答,维护度很高。有人维护的话,让我们用的也省心和放心。目前作者对redis 的主导开发方向是redis的集群方向。
redis的安装
redis的安装其实还是挺简单的,总的来说就三步:下载tar包,解压tar包,安装。
不过最近我在2.6.7后用centos 5.5 32bit 时碰到一个安装问题,下面我就用图片分享下安装过程碰到的问题,在redis 文件夹内执行make时有个如下的错 undefined reference to '__sync_add_and_fetch_4'

上网找了了好多最后在 https://github.com/antirez/redis/issues/736 找到解决方案,write CFLAGS= -march=i686 on src/Makefile head!

记得要把刚安装失败的文件删除,重新解压新的安装文件,修改Makefile文件,再make安装。就不会发现原来那个错误了
关于redis的一些属性注释和基本类型操作在上一篇redis 的开胃菜有详细的说明,这里就不再重复累赘了(实质是想偷懒 ,哈哈!)
最后,把memcache和redis放在一起不得不会让人想到两者的比较,谁快谁好用啊,群里面已经为这个事打架很久了,我就把我看到的在这里跟大家分享下。
在别人发了一个memcache性能比redis好很多后,redis 作者 antirez 发表了一篇博文,主要是说到如何给redis 和 memcache 做压力测试,文中讲到有个人说许多开源软件都应该丢进厕所,因为他们的压力测试脚本太2了,作者对这个说明了一番。redis vs memcache is definitely an apple to apple comparison。 呵呵,很明确吧,两者的比较是不是有点鸡蛋挑骨头的效果,作者在相同的运行环境做了三次测试取多好的值,得到的结果如下图:

需要申明的是此次测试在单核心处理的过程的数据,memcache是支持多核心多线程操作的(默认没开)所以在默认情况下上图具有参考意义,若然则memcache快于redis。那为什么redis不支持多线程多核心处理呢?作者也发表了一下自己的看法,首先是多线程不变于bug的修复,其实是不易软件的扩展,还有数据一致性问题因为redis所有的操作都是原子操作,作者用到一个词nightmare 噩梦,呵呵! 当然不支持多线程操作,肯定也有他的弊端的比如性能想必必然差,作者从2.2版本后专注redis cluster的方向开发来缓解其性能上的弊端,说白了就是纵向不行,横向提高。
 module for PHP 5))


-Wednesday)
...)


![[OJ] Wildcard Matching (Hard)](http://pic.xiahunao.cn/[OJ] Wildcard Matching (Hard))
)






![[软件测试airtest软件安装]——填坑](http://pic.xiahunao.cn/[软件测试airtest软件安装]——填坑)


右移操作>>)
