Python 在数据分析领域里是一门非常强大的语言,在数据分析方面有着出色的生态系统。Pandas 包就是其中之一,它的主要特点是导入和分析数据非常的容易,Pandas 类似 Numpy、Matplotlib,提供了单一且方便的方式来处理数据分析和形象化的工作。
本文中,我们使用 Pandas 来分析 IGN(www.ign.com) 上的游戏评论数据,IGN 是一个颇受欢迎的游戏评论网站。相关数据可以从这里(https://www.kaggle.com/egrinstein/20-years-of-games)获取到,也可以通过我的 Github 获取(https://raw.githubusercontent.com/keer2345/DataAnalysisWithPython/master/myself-notebook/dataquest.io/ign.csv)。通过分析评论数据,我们将学到类似索引等 Pandas 关键的方面。
比如类似巫师3(Witcher3)这款游戏,在 PS4 上的评论会比 Xbox One 上更多吗?数据集能帮我们给出结果。

使用Pandas导入数据
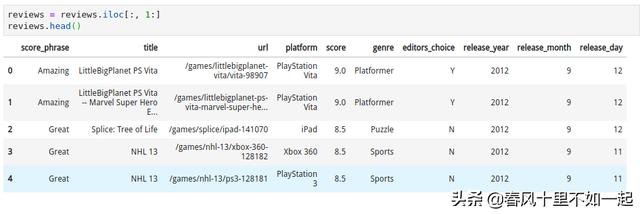
首先,我们先查看数据。数据以逗号分隔符来存储,或者 csv 文件,每一行通过换行来分隔,每一列以逗号,来分隔,下面是 ign.csv 文件的前面几行:
,score_phrase,title,url,platform,score,genre,editors_choice,release_year,release_month,release_day0,Amazing,LittleBigPlanet PS Vita,/games/littlebigplanet-vita/vita-98907,PlayStation Vita,9.0,Platformer,Y,2012,9,121,Amazing,LittleBigPlanet PS Vita -- Marvel Super Hero Edition,/games/littlebigplanet-ps-vita-marvel-super-hero-edition/vita-20027059,PlayStation Vita,9.0,Platformer,Y,2012,9,122,Great,Splice: Tree of Life,/games/splice/ipad-141070,iPad,8.5,Puzzle,N,2012,9,123,Great,NHL 13,/games/nhl-13/xbox-360-128182,Xbox 360,8.5,Sports,N,2012,9,11正如我们看到的,每一行代表游戏的一个 IGN 评论。每一列的含义如下:
- score_phrase: IGN 评论的唯一值
- title: 游戏名称
- url: 通过 URL 可以看到详细评论
- platform: 通过何种平台评论游戏(PC, PS4, etc)
- score: 评分,从 1.0 ~ 10.0
- genre: 游戏种类
- editors_choice: 如果游戏并非通过选择打分的为 N,否则为 Y
- release_year: 游戏发布年份
- release_month: 游戏发布月份
- release_day:游戏发布日期
数据里还有一列包含索引值,到后面深入索引数据之前我们可以忽略这一列。我们通过 Pandas DataFrame 加载数据,DataFrame 是一种处理表格数据的方式,表格数据拥有行和列,类似上面的 csv 文件。
为了读取数据,我们使用 pandas.read_csv 函数。该函数能返回 csv 文件的 DataFrame:
- 导入 pandas 库,并习惯性的重命名为 pd,以便能以后能快速地调用它。
- 读取 ign.csv 文件到 DataFrame,并赋值给 reviews。
import pandas as pdreviews = pd.read_csv("ign.csv")获取完数据后,Pandas 提供了两个方法来快速打印数据:
- pandas.DataFrame.head:打印 DataFrame 的前 N 行,默认值为 5
- pandas.DataFrame.tail:打印 DataFrame 的后 N 行,默认值为 5
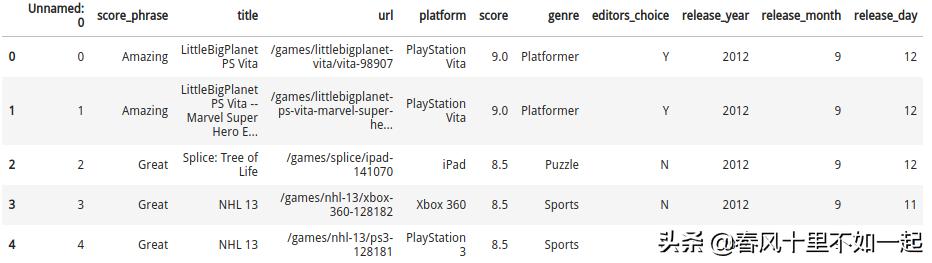
reviews.tail(3)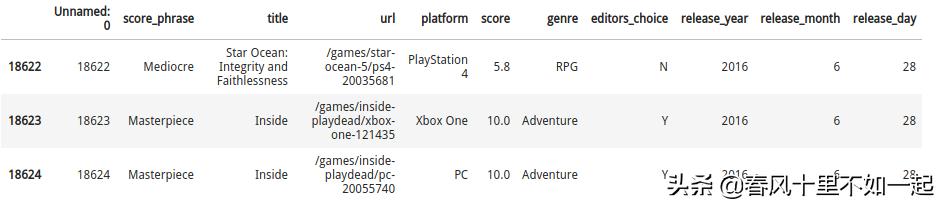
我们还可以通过 pandas.DataFrame.shape 属性来查看行数和列数:
reviews.shape(18625, 11)通过结果可以看到,我们的数据有 18625 行,11 列。
Pandas 对比 Numpy 的一大优势就是 Pandas 允许我们可以有不同数据类型的列。reviews 有的类似 store 的 float 列;有的类似 score_phrase 的 string 列;有的类似 release_year 的 integer 列。
现在,让我们通过索引 reviews 来获取想要的行和列。
使用Pandas索引DataFrames
前面我们使用 head 方法来打印前 5 行数据,我们可以使用 pandas.DataFrame.iloc 来实现同样的功能。iloc 方法允许我们检索行和列的位置:

正如我们所看到的,指定了想要的行数 0:5,意思是位置从 0 行开始的 5 行,即 0, 1, 2, 3, 4。这种情况下,也可以简写为 :5。
我们使用 : 来指定列的位置,表示获取所有列。
下面是一些索引(indexing)的例子:
- reviews.iloc[:5, :]:前5行、所有列
- reviews.iloc[:, :]:所有数据
- reviews.iloc[5:, 5:]:第5行和第5列之后的数据
- reviews.iloc[:, 0]:所有行的第一列数据
- reviews.iloc[9, :]:第10行数据
通过位置来索引与 Numpy 索引很相似。
现在,让我们移除没什么意义的第一列:
在Pandas中使用标签来检索
我们已经知道如何通过行和列的位置来检索数据,现在我们通过 DataFrame 的其他主要的方法来检索数据,就是通过航和咧的标签来检索。
Pandas 优于 Numpy 的其中一点是 Pandas 的行和列都有标签,通过列的位置当然可以检索,但是这很难跟踪哪些数字对应哪些列。我们通过 pandas.DataFrame.loc 方法来使用标签,允许我们通过标签替代位置来检索数据。
我们使用 loc 浏览前五行数据:

这个例子与 reviews.iloc[0:5, :] 看起来没有什么区别,是因为我们的行标签匹配了位置值。我们可以看到行标签在表格的左边,也可以看出来它们通过 DataFrame 索引属性访问。我们展示数据的行索引:

索引并不一定与位置匹配,比如下面的代码:
- 获取数据的 10 ~ 20 行,并赋值为 some_reviews
- 浏览 some_reviews 的前 5 行

可以看见,在 some_reviews 中,行索引从 10 到 20,因此,loc 标签检索的数字必须是从 10 到 20。
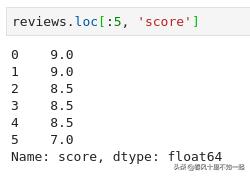
正如前面提到的,列标签可以很容易的找到数据,我们使用 loc 方法通过列标签替代位置索引检索数据:
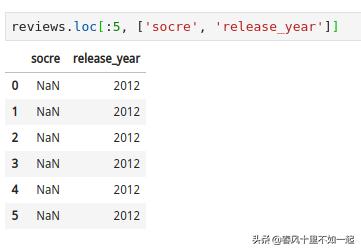
我们也可以一次通过列表形式指定多个列标签:
上半部分小结
上半部分的文章,我们主要了解了 Pandas 如何加载数据,以及 Pandas 通过位置或者标签检索数据的方便快捷的特性。我们将在后面的文章继续学习 Pandas,学习它更多的特性。
















)


