一、延时队列的应用
1.1 什么是延时队列?
顾名思义:首先它要具有队列的特性,再给它附加一个延迟消费队列消息的功能,也就是说可以指定队列中的消息在哪个时间点被消费。
延时队列在项目中的应用还是比较多的,尤其像电商类平台:
- 下订单成功后,在30分钟内没有支付,自动取消订单
- 外卖平台发送订餐通知,下单成功后60s给用户推送短信。
- 如果订单一直处于某一个未完结状态时,及时处理关单,并退还库存
- 淘宝新建商户一个月内还没上传商品信息,将冻结商铺等
- 用户登录之后5分钟给用户做分类推送;
- 用户多少天未登录给用户做召回推送;
- 关闭空闲连接。服务器中,有很多客户端的连接,空闲一段时间之后需要关闭之。
- 清理过期数据业务上。比如缓存中的对象,超过了空闲时间,需要从缓存中移出。
- 任务超时处理。在网络协议滑动窗口请求应答式交互时,处理超时未响应的请求。
- 新创建店铺,N天内没有上传商品,系统如何知道该信息,并发送激活短信?
1.2 延迟队列和定时任务的区别
- 定时任务有明确的触发时间,延时任务没有
- 定时任务有执行周期,而延时任务在某事件触发后一段时间内执行,没有执行周期
- 定时任务一般执行的是批处理操作是多个任务,而延时任务一般是单个任务
业界目前也有很多实现方案,单机版的方案就不说了,现在也没有哪个公司还是单机版的服务,今天我们一一探讨各种方案的大致实现。
二、延时队列的实现
个人一直秉承的观点:工作上能用JDK自带API实现的功能,就不要轻易自己重复造轮子,或者引入三方中间件。一方面自己封装很容易出问题(大佬除外),再加上调试验证产生许多不必要的工作量;另一方面一旦接入三方的中间件就会让系统复杂度成倍的增加,维护成本也大大的增加。
2.1 定时轮询(quartz,数据库等)
通过一个线程定时的去扫描数据库,通过下订单时间来判断是否有超时的订单,然后进行update或delete等操作
对于未支付的订单,需要进行定期扫描,判断其产生时间有没有超过固定的时间,如果超过则取消订单。这样做很不好,因为:
- 扫描数据库,每次扫描整个表非常耗时,因为一直在阻塞,很耗费资源
- 所谓的定期扫描,扫描时间的粒度太小,就会造成资源浪费,扫描的粒度太大就会造成订单没有及时删除
(1)实现
基于主流的定时任务,定时扫描:
常见的定时任务主要有:quartz、xxl-job、spring系列的task、linux自带的 corntab和加工后的 JcronTab等
下面为方便起见,使用spring task实现主要思路
public class JobDelayQueueDemo {// 下单时间Date submitOrder = null;// 取消订单时间:下单30分钟后 检测如果未支付,则自动取消订单,生成订单60s后,给客户发短信Date executeTime = null;/*** Step2: 定时扫描数据库** 每隔五秒*/@Scheduled(cron = "0/5 * * * * ? ")public void process(){System.out.println("我是定时任务!\n 我来看一下延迟时间够了没有!!" );/*** 检测当前时间 是否是取消订单时间* 当前时间 - 执行时间 如果误差小于 2s则取消订单*/if (System.currentTimeMillis() - executeTime.getTime() < 2000) {System.out.println("取消订单逻辑处理");/*** 取消订单逻辑* 此处省略1000万行代码*/System.out.println("发送短信提醒客户,订单已取消");}}/*** Step1: 提交订单,存入数据库*/public void submitOrder(){/*** 下单时间,如果当前时间超过下单时间30分钟未支付 则发送短信提醒将自动取消订单*/submitOrder = DateTools.string2DateTime("2020-07-22 13:00:00");/*** 取消订单时间:下单30分钟后 检测如果未支付,则自动取消订单,生成订单60s后,给客户发短信*/executeTime = DateUtils.addMinutes(submitOrder,30);/*** 存入数据库* 此处省略 100000万行代码*/}
}
下面为方便起见,使用spring quartz 实现主要思路:
public class QuartzDelayQueueDemo implements Job {// 下单时间Date submitOrder = null;// 取消订单时间:下单30分钟后 检测如果未支付,则自动取消订单,生成订单60s后,给客户发短信Date executeTime = null;public static void main(String[] args) throws SchedulerException {// 创建任务JobDetail jobDetail = JobBuilder.newJob(QuartzDelayQueueDemo.class).withIdentity("job1", "group1").build();// 创建触发器 每3秒钟执行一次Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "group3").withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(3).repeatForever()).build();Scheduler scheduler = new StdSchedulerFactory().getScheduler();// 将任务及其触发器放入调度器scheduler.scheduleJob(jobDetail, trigger);// 调度器开始调度任务scheduler.start();}@Overridepublic void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {System.out.println("我是定时任务!\n 我来看一下延迟时间够了没有!!");/*** 检测当前时间 是否是取消订单时间* 当前时间 - 执行时间 如果误差小于 2s则取消订单*/if (System.currentTimeMillis() - executeTime.getTime() < 2000) {System.out.println("取消订单逻辑处理");/*** 取消订单逻辑* 此处省略1000万行代码*/System.out.println("发送短信提醒客户,订单已取消");}}
}
源码地址: 快速访问
(2)优缺点
优点 :简单易行,支持集群操作
缺点 :
- 对服务器内存消耗大
- 存在延迟,比如你每隔3分钟扫描一次,那最坏的延迟时间就是3分钟
- 假设你的订单有几千万条,每隔几分钟这样扫描一次,数据库损耗极大
- 数据量过大时会消耗太多的IO资源,效率太低
2.2 DelayQueue 延时队列(JDK)
JDK 中提供了一组实现延迟队列的API,位于Java.util.concurrent包下DelayQueue。
DelayQueue是一个BlockingQueue(无界阻塞)队列,它本质就是封装了一个PriorityQueue(优先队列),PriorityQueue内部使用完全二叉堆(不知道的自行了解哈)来实现队列元素排序,我们在向DelayQueue队列中添加元素时,会给元素一个Delay(延迟时间)作为排序条件,队列中最小的元素会优先放在队首。队列中的元素只有到了Delay时间才允许从队列中取出。队列中可以放基本数据类型或自定义实体类,在存放基本数据类型时,优先队列中元素默认升序排列,自定义实体类就需要我们根据类属性值比较计算了。
先简单实现一下看看效果,添加三个order入队DelayQueue,分别设置订单在当前时间的5秒、10秒、15秒后取消。
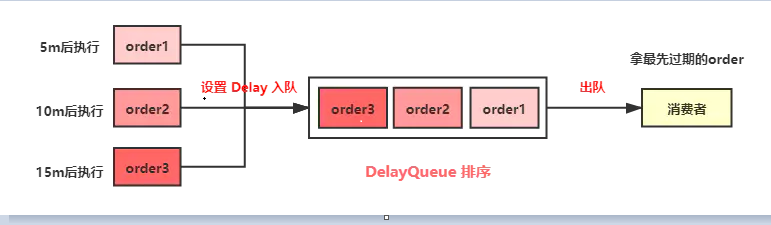
要实现DelayQueue延时队列,队中元素要implements Delayed 接口,这个接口里只有一个getDelay方法,用于设置延期时间。Order类中compareTo方法负责对队列中的元素进行排序。
其中:
- poll():获取并移除队列的超时元素,没有则返回空
- take():获取并移除队列的超时元素,如果没有则wait当前线程,直到有元素满足超时条件,返回结果。
(1)实现
- BlockingQueue+PriorityQueue(堆排序)+Delayed
- DelayQueue中存放的对象需要实现compareTo()方法和getDelay()方法
- getDelay方法返回该元素距离失效还剩余的时间,当<=0时元素就失效了,就可以从队列中获取到
public class DelayOrder implements Delayed {/*** 延迟时间*/@JsonFormat(locale = "zh", timezone = "GMT+8", pattern = "yyyy-MM-dd HH:mm:ss")private long time;/*** 订单号*/String orderNumber = null;public DelayOrder(String orderNumber, long time, TimeUnit unit) {this.orderNumber = orderNumber;this.time = System.currentTimeMillis() + (time > 0 ? unit.toMillis(time) : 0);}/*** 返回距离你自定义的超时时间还有多少* @param unit* @return*/@Overridepublic long getDelay(TimeUnit unit) {return time - System.currentTimeMillis();}/*** https://www.runoob.com/java/java-string-compareto.html* @param o* @return*/@Overridepublic int compareTo(Delayed o) {DelayOrder Order = (DelayOrder) o;long diff = this.time - Order.time;if (diff <= 0) {return -1;} else {return 1;}}void print() {System.out.println(orderNumber + "编号的订单准备删除,删除时间:"+ DateTools.getLong2YyyyMmDdHhMmSs(System.currentTimeMillis()));}}
DelayQueue的put方法是线程安全的,因为put方法内部使用了ReentrantLock锁进行线程同步。
DelayQueue还提供了两种出队的方法 poll() 和 take()
poll()为非阻塞获取,没有到期的元素直接返回null;take()阻塞方式获取,没有到期的元素线程将会等待。
public class DelayQueueDemo {public static void main(String[] args) throws InterruptedException {DelayOrder orderNumber1 = new DelayOrder("orderNumber1", 5, TimeUnit.SECONDS);DelayOrder orderNumber2 = new DelayOrder("orderNumber2", 10, TimeUnit.SECONDS);DelayOrder orderNumber3 = new DelayOrder("orderNumber3", 15, TimeUnit.SECONDS);DelayQueue<DelayOrder> delayOrders = new DelayQueue<>();delayOrders.put(orderNumber1);delayOrders.put(orderNumber2);delayOrders.put(orderNumber3);System.out.println("订单延迟队列开始时间:" + LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));while (delayOrders.size() != 0){/*** 取队列头部元素是否过去* poll():获取并移除队列的超时元素,没有则返回空* take():获取并移除队列的超时元素,如果没有则wait当前线程,直到有元素满足超时条件,返回结果。*/
// DelayOrder task = delayOrders.poll();DelayOrder task1 = delayOrders.take();if (task1 != null) {System.out.format("订单:{%s}被取消, 取消时间:{%s}\n", task1.orderNumber, LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));}
// Thread.sleep(1000);}}
}
上边只是简单的实现入队与出队的操作,实际开发中会有专门的线程,负责消息的入队与消费。
执行后看到结果如下,Order1、Order2、Order3 分别在 5秒、10秒、15秒后被执行,至此就用DelayQueue实现了延时队列。
订单延迟队列开始时间:2020-12-14 13:20:48
订单:{orderNumber1}被取消, 取消时间:{2020-12-14 13:20:53}
订单:{orderNumber2}被取消, 取消时间:{2020-12-14 13:20:58}
订单:{orderNumber3}被取消, 取消时间:{2020-12-14 13:21:03}
(2)优缺点
优点 :效率高,任务触发时间延迟低
缺点:
- 服务器重启后,数据全部消失,怕宕机
- 集群扩展相当麻烦
- 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现OOM异常
- 代码复杂度较高,分布式需要额外实现(无法指定绝对的日期或时间)
(3)实现原理

内部结构
- 可重入锁
- 用于根据delay时间排序的优先级队列
- 用于优化阻塞通知的线程元素leader
- 用于实现阻塞和通知的Condition对象
delayed和PriorityQueue
在理解delayQueue原理之前我们需要先了解两个东西,delayed和PriorityQueue.
- delayed是一个具有过期时间的元素
- PriorityQueue是一个根据队列里元素某些属性排列先后的顺序队列
delayQueue其实就是在每次往优先级队列中添加元素,然后以元素的delay/过期值作为排序的因素,以此来达到先过期的元素会拍在队首,每次从队列里取出来都是最先要过期的元素
offer()方法
- 执行加锁操作
- 把元素添加到优先级队列中
- 查看元素是否为队首
- 如果是队首的话,设置leader为空,唤醒所有等待的队列
- 释放锁
public boolean offer(E e) {final ReentrantLock lock = this.lock;lock.lock();try {q.offer(e);if (q.peek() == e) {leader = null;available.signal();}return true;} finally {lock.unlock();}}
take() 方法
- 执行加锁操作
- 取出优先级队列元素q的队首
- 如果元素q的队首/队列为空,阻塞请求
- 如果元素q的队首(first)不为空,获得这个元素的delay时间值
- 如果first的延迟delay时间值为0的话,说明该元素已经到了可以使用的时间,调用poll方法弹出该元素,跳出方法
- 如果first的延迟delay时间值不为0的话,释放元素first的引用,避免内存泄露
- 判断leader元素是否为空,不为空的话阻塞当前线程
- 如果leader元素为空的话,把当前线程赋值给leader元素,然后阻塞delay的时间,即等待队首到达可以出队的时间,在finally块中释放leader元素的引用
- 循环执行从1~8的步骤
- 如果leader为空并且优先级队列不为空的情况下(判断还有没有其他后续节点),调用signal通知其他的线程
- 执行解锁操作
/*** Retrieves and removes the head of this queue, waiting if necessary* until an element with an expired delay is available on this queue.** @return the head of this queue* @throws InterruptedException {@inheritDoc}*/public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {for (;;) {E first = q.peek();if (first == null)available.await();else {long delay = first.getDelay(NANOSECONDS);if (delay <= 0)return q.poll();first = null; // don't retain ref while waitingif (leader != null)available.await();else {Thread thisThread = Thread.currentThread();leader = thisThread;try {available.awaitNanos(delay);} finally {if (leader == thisThread)leader = null;}}}}} finally {if (leader == null && q.peek() != null)available.signal();lock.unlock();}}
get点
整个代码的过程中并没有使用上太难理解的地方,但是有几个比较难以理解他为什么这么做的地方
leader元素的使用
大家可能看到在我们的DelayQueue中有一个Thread类型的元素leader,那么他是做什么的呢,有什么用呢?
让我们先看一下元素注解上的doc描述:
Thread designated to wait for the element at the head of the queue.
This variant of the Leader-Follower pattern serves to minimize unnecessary timed waiting.
when a thread becomes the leader, it waits only for the next delay to elapse, but other threads await indefinitely.
The leader thread must signal some other thread before returning from take() or poll(…), unless some other thread becomes leader in the interim.
Whenever the head of the queue is replaced with an element with an earlier expiration time, the leader field is invalidated by being reset to null, and some waiting thread, but not necessarily the current leader, is signalled.
So waiting threads must be prepared to acquire and lose leadership while waiting.
上面主要的意思就是说用leader来减少不必要的等待时间,那么这里我们的DelayQueue是怎么利用leader来做到这一点的呢:
这里我们想象着我们有个多个消费者线程用take方法去取,内部先加锁,然后每个线程都去peek第一个节点.
- 如果leader不为空说明已经有线程在取了,设置当前线程等待
if (leader != null)available.await();
- 如果为空说明没有其他线程去取这个节点,设置leader并等待delay延时到期,直到poll后结束循环
else {Thread thisThread = Thread.currentThread();leader = thisThread;try {available.awaitNanos(delay);} finally {if (leader == thisThread)leader = null;}
}
take方法中为什么释放first元素
first = null; // don't retain ref while waiting
我们可以看到doug lea后面写的注释,那么这段代码有什么用呢?
想想假设现在延迟队列里面有三个对象(take() 方法中)
- 线程A进来获取first,然后进入 else 的else ,设置了leader为当前线程A
- 线程B进来获取first,进入else的阻塞操作,然后无限期等待
- 这时在JDK 1.7下面他是持有first引用的
- 如果线程A阻塞完毕,获取对象成功,出队,这个对象理应被GC回收,但是他还被线程B持有着,GC链可达,所以不能回收这个first.
- 假设还有线程C 、D、E… 持有对象1引用,那么无限期的不能回收该对象1引用了,那么就会造成内存泄露.
相关文章
- DelayQueue 阻塞队列
2.3 ScheduledExecutorService(JDk 线程池)
JUC 提供了相关的类以支持对 延时任务 和 周期任务 的支持,功能类似于 java.util.Timer,但官方推荐使用功能更为强大全面的
ScheduledThreadPoolExecutor,因为后者支持多任务作业,即线程池;
(1)实现
public void ScheduledExecutorServiceTest() throws InterruptedException {ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);System.out.println("创建5秒延迟的任务,时间:"+ DateTools.getLong2YyyyMmDdHhMmSs(System.currentTimeMillis()));ScheduledFuture<?> schedule = scheduledExecutorService.schedule(() -> doTask("5s"), 5, TimeUnit.SECONDS);Thread.sleep(4900);schedule.cancel(false);System.err.println("取消5秒延迟的任务,时间:" + DateTools.getLong2YyyyMmDdHhMmSs(System.currentTimeMillis()));System.out.println("创建3秒延迟的任务,时间" + DateTools.getLong2YyyyMmDdHhMmSs(System.currentTimeMillis()));ScheduledFuture<?> schedule2 = scheduledExecutorService.schedule(new Runnable() {@Overridepublic void run() {doTask("3s");}}, 3, TimeUnit.SECONDS);Thread.sleep(4000);}
执行结果:
创建5秒延迟的任务,时间:2020-12-14 13:49:17
取消5秒延迟的任务,时间:2020-12-14 13:49:22
创建3秒延迟的任务,时间2020-12-14 13:49:22
3s 任务执行,时间: 2020-12-14 13:49:25
2.4 Timer与TimerTask(JDK)
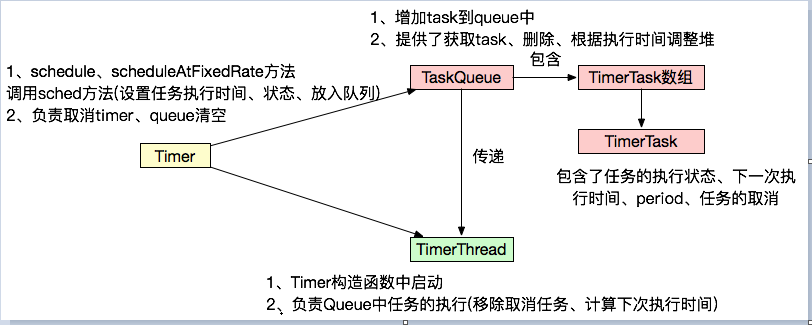
- TaskQueue中的排序是对TimerTask中的下一次执行时间进行堆排序,每次去取数组第一个。
- 而delayQueue是对queue中的元素的getDelay()结果进行排序
Timer是一种定时器工具,用来在一个后台线程计划执行指定任务。它可以计划执行一个任务一次或反复多次。 主要方法:

(1)实现
public class TimerDemo {public static void main(String[] args) {Timer timer = new Timer();// 实例化Timer类timer.schedule(new TimerTask() {public void run() {System.out.println("退出,时间:"+ DateTools.getLong2YyyyMmDdHhMmSs(System.currentTimeMillis()));this.cancel();}}, 5000); // 5sSystem.out.println("本程序存在5秒后自动退出,时间:"+ DateTools.getLong2YyyyMmDdHhMmSs(System.currentTimeMillis()));}
}
(2)优缺点
缺点:
- Timers没有持久化机制.
- Timers不灵活 (只可以设置开始时间和重复间隔,不是基于时间、日期、天等(秒、分、时)的)
- Timers 不能利用线程池,一个timer一个线程
- Timers没有真正的管理计划
(3)任务对比
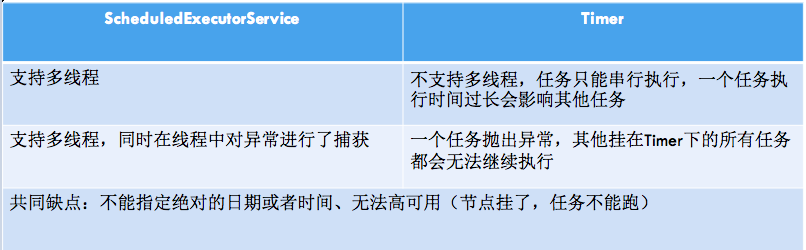
还有: DelayQueue 延时队列(JDK),无法指定绝对的日期或时间,无法高可用(节点挂了任务不能跑)
2.5 Redis 延迟队列
Redis 实现延迟队列有两种方式:
- Redis sorted set
- Redis 过期回调
(1)Redis sorted set
Redis的数据结构Zset,同样可以实现延迟队列的效果,主要利用它的score属性,redis通过score来为集合中的成员进行从小到大的排序。

通过zadd命令向队列delayqueue 中添加元素,并设置score值表示元素过期的时间;
向delayqueue 添加三个order1、order2、order3,分别是10秒、20秒、30秒后过期。
zadd delayqueue 3 order3
消费端轮询队列delayqueue, 将元素排序后取最小时间与当前时间比对,如小于当前时间代表已经过期移除key。
public class RedisZsetDelayQueue {private static String DELAY_QUEUE = "delay_queue";public static void main(String[] args) {RedisZsetDelayQueue redisDelay = new RedisZsetDelayQueue();redisDelay.pushOrderQueue();redisDelay.pollOrderQueue();redisDelay.deleteZSet();}/*** 消息入队*/public void pushOrderQueue() {Jedis jedis = JedisClient.JedisClient();Calendar cal1 = Calendar.getInstance();cal1.add(Calendar.SECOND, 10);int order1 = (int) (cal1.getTimeInMillis() / 1000); // 10s 后的时间戳Calendar cal2 = Calendar.getInstance();cal2.add(Calendar.SECOND, 20);int order2 = (int) (cal2.getTimeInMillis() / 1000);Calendar cal3 = Calendar.getInstance();cal3.add(Calendar.SECOND, 30);int order3 = (int) (cal3.getTimeInMillis() / 1000);/*** String key, double score, String member* key = DELAY_QUEUE* order1 = 权重* member = order1*/jedis.zadd(DELAY_QUEUE, order1, "order1");jedis.zadd(DELAY_QUEUE, order2, "order2");jedis.zadd(DELAY_QUEUE, order3, "order3");System.out.println(DateTools.getLong2YyyyMmDdHhMmSs(System.currentTimeMillis()) + " add finished.");}/*** 删除队列*/public void deleteZSet() {Jedis jedis = JedisClient.JedisClient();jedis.del(DELAY_QUEUE);}/*** 消费消息*/public void pollOrderQueue() {Jedis jedis = JedisClient.JedisClient();while (true) {Set<Tuple> set = jedis.zrangeWithScores(DELAY_QUEUE, 0, 0);String value = ((Tuple) set.toArray()[0]).getElement();int score = (int) ((Tuple) set.toArray()[0]).getScore();Calendar cal = Calendar.getInstance();int nowSecond = (int) (cal.getTimeInMillis() / 1000);if (nowSecond >= score) {// 移除有序集合中的一个或多个成员jedis.zrem(DELAY_QUEUE, value);System.out.println(DateTools.getLong2YyyyMmDdHhMmSs(System.currentTimeMillis()) + " removed key:" + value);}// 获取有序集合的成员数if (jedis.zcard(DELAY_QUEUE) <= 0) {System.out.println(DateTools.getLong2YyyyMmDdHhMmSs(System.currentTimeMillis()) + " zset empty ");return;}try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
运行结果:
2020-12-14 16:49:52 add finished.
2020-12-14 16:50:02 removed key:order1
2020-12-14 16:50:12 removed key:order2
2020-12-14 16:50:22 removed key:order3
2020-12-14 16:50:22 zset empty
(2)Redis 的过期回调
Redis 的key过期回调事件,也能达到延迟队列的效果,简单来说我们开启监听key是否过期的事件,一旦key过期会触发一个callback事件。
修改redis.conf文件开启notify-keyspace-events Ex
在线文档:https://redis.io/topics/notifications
notify-keyspace-events Ex
############################# Event notification ############################### Redis can notify Pub/Sub clients about events happening in the key space.
# This feature is documented at http://redis.io/topics/notifications
#
# For instance if keyspace events notification is enabled, and a client
# performs a DEL operation on key "foo" stored in the Database 0, two
# messages will be published via Pub/Sub:
#
# PUBLISH __keyspace@0__:foo del
# PUBLISH __keyevent@0__:del foo
#
# It is possible to select the events that Redis will notify among a set
# of classes. Every class is identified by a single character:
# 下面是监听时,参数配置:
# K Keyspace events, published with __keyspace@<db>__ prefix.
# E Keyevent events, published with __keyevent@<db>__ prefix.
# g Generic commands (non-type specific) like DEL, EXPIRE, RENAME, ... 基本命令
# $ String commands
# l List commands
# s Set commands
# h Hash commands
# z Sorted set commands
# x Expired events (events generated every time a key expires)
# e Evicted events (events generated when a key is evicted for maxmemory) 驱逐,赶出 OOM的时候监听
# A Alias for g$lshzxe, so that the "AKE" string means all the events.
#
# The "notify-keyspace-events" takes as argument a string that is composed
# of zero or multiple characters. The empty string means that notifications
# are disabled.
#
# Example: to enable list and generic events, from the point of view of the
# event name, use:
#
# notify-keyspace-events Elg
#
# Example 2: to get the stream of the expired keys subscribing to channel
# name __keyevent@0__:expired use:
#
# notify-keyspace-events Ex ### 参数为 “Ex”。x 代表了过期事件
#
# By default all notifications are disabled because most users don't need
# this feature and the feature has some overhead. Note that if you don't
# specify at least one of K or E, no events will be delivered.
notify-keyspace-events "EX"
Redis监听配置,注入Bean RedisMessageListenerContainer
@Configuration
public class RedisListenerConfig {@BeanRedisMessageListenerContainer container(RedisConnectionFactory connectionFactory) {RedisMessageListenerContainer container = new RedisMessageListenerContainer();container.setConnectionFactory(connectionFactory);return container;}
}
编写Redis过期回调监听方法,必须继承KeyExpirationEventMessageListener ,有点类似于MQ的消息监听。
@Component
public class RedisKeyExpirationListener extends KeyExpirationEventMessageListener {public RedisKeyExpirationListener(RedisMessageListenerContainer listenerContainer) {super(listenerContainer);}@Overridepublic void onMessage(Message message, byte[] pattern) {String expiredKey = message.toString();System.out.println("监听到key:" + expiredKey + "已过期");}
}
到这代码就编写完成,非常的简单,接下来测试一下效果,在redis-cli客户端添加一个key 并给定3s的过期时间。
set wxw 123 ex 3
在控制台成功监听到了这个过期的key。
监听到过期的key为:wxw
开启过期事件监听后运行结果:

相关文章
- Redis Zset操作在线文档
(3)优缺点
优点:
- 由于使用Redis作为消息通道,消息都存储在Redis中。如果发送程序或者任务处理程序挂了,重启之后,还有重新处理数据的可能性。
- 做集群扩展相当方便
- 时间准确度高
缺点:
- 需要额外进行redis维护
2.6 RabbitMQ 延迟队列
利用 RabbitMQ 做延时队列是比较常见的一种方式,而实际上RabbitMQ 自身并没有直接支持提供延迟队列功能,而是通过 RabbitMQ 消息队列的 TTL和 DXL这两个属性间接实现的。
先来认识一下 TTL和 DXL两个概念:
-
TTL顾名思义:指的是消息的存活时间,RabbitMQ可以通过x-message-tt参数来设置指定Queue(队列)和Message(消息)上消息的存活时间,它的值是一个非负整数,单位为微秒。RabbitMQ可以从两种维度设置消息过期时间,分别是队列和消息本身- 设置队列过期时间,那么队列中所有消息都具有相同的过期时间。
- 设置消息过期时间,对队列中的某一条消息设置过期时间,每条消息
TTL都可以不同。
如果同时设置队列和队列中消息的
TTL,则TTL值以两者中较小的值为准。而队列中的消息存在队列中的时间,一旦超过TTL过期时间则成为Dead Letter(死信)。 -
Dead Letter Exchanges(DLX):DLX即死信交换机,绑定在死信交换机上的即死信队列。RabbitMQ的Queue(队列)可以配置两个参数x-dead-letter-exchange和x-dead-letter-routing-key(可选),一旦队列内出现了Dead Letter(死信),则按照这两个参数可以将消息重新路由到另一个Exchange(交换机),让消息重新被消费。x-dead-letter-exchange:队列中出现Dead Letter后将Dead Letter重新路由转发到指定exchange(交换机)。x-dead-letter-routing-key:指定routing-key发送,一般为要指定转发的队列。
队列出现Dead Letter的情况有:
- 消息或者队列的
TTL过期 - 队列达到最大长度
- 消息被消费端拒绝(basic.reject or basic.nack)
案例分析
下边结合一张图看看如何实现超30分钟未支付,则关闭该订单的功能
我们在下单成功时,开启一个延迟消息队列order.delay.queue ,并设置x-message-tt消息存活时间为30分钟,当到达30分钟后订单消息A0001成为了Dead Letter(死信),延迟队列检测到有死信,通过配置x-dead-letter-exchange,将死信重新转发到能正常消费的关闭订单的消息队列,消费端直接监听关闭订单消息队列后检查数据库支付状态,如果未支付,则关闭该订单。

(1)实现
发送消息时指定消息延迟的时间
public void send(String delayTimes) {amqpTemplate.convertAndSend("order.pay.exchange", "order.pay.queue","大家好我是延迟数据", message -> {// 设置延迟毫秒值message.getMessageProperties().setExpiration(String.valueOf(delayTimes));return message;});}
}设置延迟队列出现死信后的转发规则
/*** 延时队列*/@Bean(name = "order.delay.queue")public Queue getMessageQueue() {return QueueBuilder.durable(RabbitConstant.DEAD_LETTER_QUEUE)// 配置到期后转发的交换机.withArgument("x-dead-letter-exchange", "order.close.exchange")// 配置到期后转发的路由键.withArgument("x-dead-letter-routing-key", "order.close.queue").build();}源码地址:GitHub快速访问
(2)优缺点
- 优点: 高效,可以利用rabbitmq的分布式特性轻易的进行横向扩展,消息支持持久化增加了可靠性。
- 缺点:本身的易用度要依赖于rabbitMq的运维.因为要引用rabbitMq,所以复杂度和成本变高
2.7 时间轮(Netty|Kafka|RocketMQ)
前边几种延时队列的实现方法相对简单,比较容易理解,时间轮算法就稍微有点抽象了。kafka、netty都有基于时间轮算法实现延时队列,下边主要实践Netty的延时队列讲一下时间轮是什么原理。
先来看一张时间轮的原理图,解读一下时间轮的几个基本概念

wheel:时间轮,图中的圆盘可以看作是钟表的刻度。比如一圈round长度为24秒,刻度数为8,那么每一个刻度表示3秒。那么时间精度就是3秒。时间长度 / 刻度数值越大,精度越大。
当添加一个定时、延时任务A,假如会延迟25秒后才会执行,可时间轮一圈round 的长度才24秒,那么此时会根据时间轮长度和刻度得到一个圈数 round和对应的指针位置 index,也是就任务A会绕一圈指向0格子上,此时时间轮会记录该任务的round和 index信息。当round=0,index=0 ,指针指向0格子 任务A并不会执行,因为 round=0不满足要求。
所以每一个格子代表的是一些时间,比如1秒和25秒 都会指向0格子上,而任务则放在每个格子对应的链表中,这点和HashMap的数据有些类似。
Netty构建延时队列主要用HashedWheelTimer,HashedWheelTimer底层数据结构依然是使用DelayedQueue,只是采用时间轮的算法来实现。
下面我们用Netty 简单实现延时队列,HashedWheelTimer构造函数比较多,解释一下各参数的含义。
-
ThreadFactory:表示用于生成工作线程,一般采用线程池; -
tickDuration和unit:每格的时间间隔,默认100ms; -
ticksPerWheel:一圈下来有几格,默认512,而如果传入数值的不是2的N次方,则会调整为大于等于该参数的一个2的N次方数值,有利于优化hash值的计算。
public HashedWheelTimer(ThreadFactory threadFactory, long tickDuration, TimeUnit unit, int ticksPerWheel) {this(threadFactory, tickDuration, unit, ticksPerWheel, true);}-
TimerTask:一个定时任务的实现接口,其中run方法包装了定时任务的逻辑。 -
Timeout:一个定时任务提交到Timer之后返回的句柄,通过这个句柄外部可以取消这个定时任务,并对定时任务的状态进行一些基本的判断。 -
Timer:是HashedWheelTimer实现的父接口,仅定义了如何提交定时任务和如何停止整个定时机制。
(1)Netty 实现
public class NettyDelayQueue {public static void main(String[] args) {final Timer timer = new HashedWheelTimer(Executors.defaultThreadFactory(), 5, TimeUnit.SECONDS, 2);TimerTask task1 = new TimerTask() {public void run(Timeout timeout) throws Exception {System.out.println("order1 5s 后执行 ");timer.newTimeout(this, 5, TimeUnit.SECONDS);//结束时候再次注册}};timer.newTimeout(task1, 5, TimeUnit.SECONDS);TimerTask task2 = new TimerTask() {public void run(Timeout timeout) throws Exception {System.out.println("order2 10s 后执行");timer.newTimeout(this, 10, TimeUnit.SECONDS);//结束时候再注册}};timer.newTimeout(task2, 10, TimeUnit.SECONDS);//该任务仅仅运行一次timer.newTimeout(new TimerTask() {public void run(Timeout timeout) throws Exception {System.out.println("order3 15s 后执行一次");}}, 15, TimeUnit.SECONDS);}
}从执行的结果看,order3、order3延时任务只执行了一次,而order2、order1为定时任务,按照不同的周期重复执行。
运行结果:
order1 5s 后执行
order2 10s 后执行
order3 15s 后执行一次
order1 5s 后执行
order2 10s 后执行
(2)Kafka 实现
实现思路:
- 基于延迟主题和 DelayQueue 实现延迟队列
- 基于单层文件时间轮实现延迟队列
(1)基于延迟主题和 DelayQueue 实现延迟队列
在发送延时消息的时候并不是先投递到要发送的真实主题(real_topic)中,而是先投递到一些 Kafka 内部的主题(delay_topic)中,这些内部主题对用户不可见,然后通过一个自定义的服务拉取这些内部主题中的消息,并将满足条件的消息再投递到要发送的真实的主题中,消费者所订阅的还是真实的主题。
如果采用这种方案,那么一般是按照不同的延时等级来划分的,比如设定5s、10s、30s、1min、2min、5min、10min、20min、30min、45min、1hour、2hour这些按延时时间递增的延时等级,延时的消息按照延时时间投递到不同等级的主题中,投递到同一主题中的消息的延时时间会被强转为与此主题延时等级一致的延时时间,这样延时误差控制在两个延时等级的时间差范围之内(比如延时时间为17s的消息投递到30s的延时主题中,之后按照延时时间为30s进行计算,延时误差为13s)。虽然有一定的延时误差,但是误差可控,并且这样只需增加少许的主题就能实现延时队列的功能。
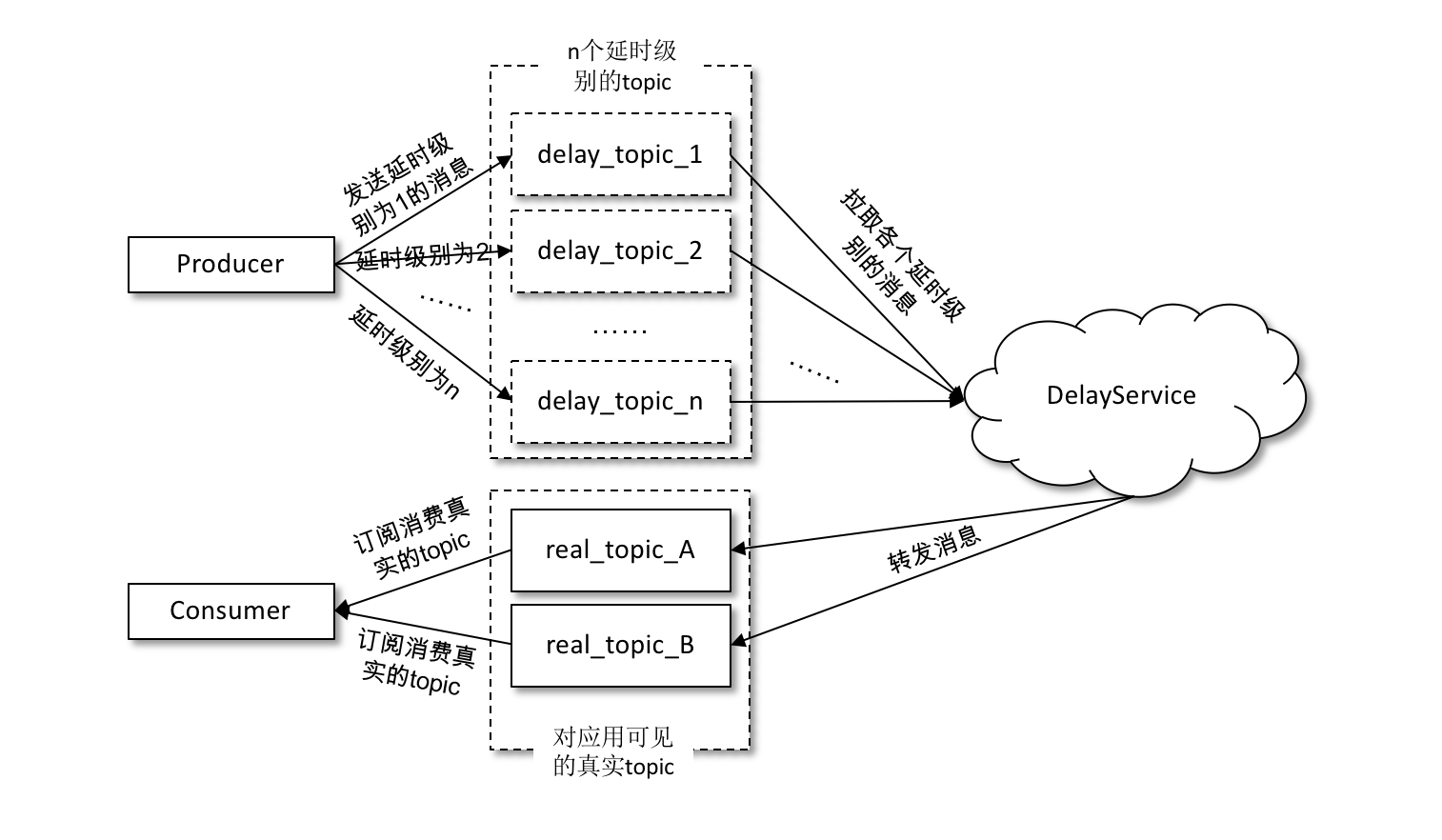
发送到内部主题(delay*topic**)中的消息会被一个独立的 DelayService 进程消费,这个 DelayService 进程和 Kafka broker 进程以一对一的配比进行同机部署(参考下图),以保证服务的可用性

针对不同延时级别的主题,在 DelayService 的内部都会有单独的线程来进行消息的拉取,以及单独的 DelayQueue(这里用的是 JUC 中 DelayQueue)进行消息的暂存。与此同时,在 DelayService 内部还会有专门的消息发送线程来获取 DelayQueue 的消息并转发到真实的主题中。从消费、暂存再到转发,线程之间都是一一对应的关系。如下图所示,DelayService 的设计应当尽量保持简单,避免锁机制产生的隐患。

为了保障内部 DelayQueue 不会因为未处理的消息过多而导致内存的占用过大,DelayService 会对主题中的每个分区进行计数,当达到一定的阈值之后,就会暂停拉取该分区中的消息。
因为一个主题中一般不止一个分区,分区之间的消息并不会按照投递时间进行排序,DelayQueue的作用是将消息按照再次投递时间进行有序排序,这样下游的消息发送线程就能够按照先后顺序获取最先满足投递条件的消息。
缺点
- 为了DelayQueue排序,将消息放到一个分区,这样是简化了设计,但是丢失了动态的扩展性,无法提升单个分区的性能
- 有一定的延时误差,无法做到秒级别的精确延时(消息在拉取一批消息后,如果这批消息未达到延迟时间,那么将重新写入主题重新消费,但是当消费严重滞后(消息堆积)时,重新写入主题到再消费,可能需要已经过了指定时间)
(2)基于单层文件时间轮实现延迟队列

单层时间轮:延时消息也不再是缓存在 内存中, 而是暂存至文件中 时间轮中每个时间格代表一个延时时间, 并且每个时间 也对应一个文件,整体上可 作单层文件时间轮
每个时间格代表 秒,若要支持 小时(也就是 60=7200 )之内的延时时间的消息, 那么整个单层时间轮的时间格数就需要 7200 个,与此对应的也就需要 72 00 件,听上去似 乎需要庞大的系统开销,就单单文件句柄的使用也会耗费很多的系统资源 其实不然,我们并 不需要维持所有文件的文件句柄,只需要加载距离时间轮表盘指针( currentTime )相近位置的部分文件即可,其余都可以用类似“懒加载”的机制来维持:若与时间格对应的文件不存在则 可以新建,若与时间格对应的文件未加载则可以重新加载,整体上造成的时延相比于延时等级 方案而言微乎其微。随着表盘指针的转动,其相邻的文件也会变得不同, 整体上在内存中只需 要维持少量的文件句柄就可以让系统运转起来。
疑问点
-
为什么不采用多层时间轮?
采用多层时间轮,设计到时间轮降级,那么会有频繁的文件在磁盘写入和删除,很影响性能
-
采用时间轮可以解决的问题
- 可以解决延时进度的问题
- 可以解决内存暴涨的问题,(方案一:通过给DelayQueue 设置阈值解决暴涨问题的)
- 可靠性问题(多副本机制保证)
可靠性
生产者同样将消息写入多个备份(单层文件时间轮〉,待时间轮转动而触发某些时间格过期时就可以将时间格 对应的文件内容(也就是延时消息〉转发到真实主题中,并且删除相应的文件。与此同时,还 会有 个后台服务专门用来清理其他时间轮中相应的时间格
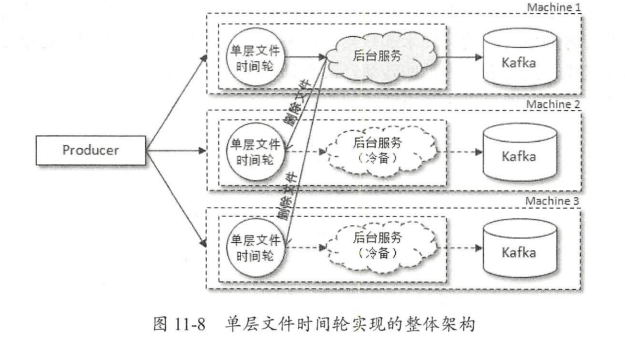
总体上而言,对于延时队列的封装 现,如果要求延时精度不是那么高,则建议使用延时 等级的实现方案,毕竟实现起来简单明了。反之,如果要求高精度或自定义延时时间,那么可以选择单层文件时间轮的方案。
(3)RocketMQ 实现
相关文章 :
- 阿里 RocketQM 定时消息和延迟消息
相关文章:
- 六种延迟队列实现方式 || 源码
- 延迟任务—队列实现
- 博客园——延迟队列
写作一点也不比上班干活轻松,查证资料反复验证demo的可行性,搭建各种RabbitMQ、Redis环境,只想说我太难了!
三、延迟队列总结
目前开源的延迟消息,也就pulsar比较可靠,其次是rocketmq,但rocket只支持18个等级的固定刻度,pulsar也是近几天内的任意时间,长时间不行。其他的,rabbit不适合大量堆积,redis key多的时候会严重滞后(惰性删除),而且没有ack。sorted set,在field超过一定量时预计5000左右会产生性能问题,需要做二次分片。jdk的delayqueue,性能就不提了,只能做短时、量少的延迟消息,而且还没有ack,可能存在丢失,如果要写入数据库,也很麻烦。内存时间轮性能好点,但也没法ack,而且消费阻塞会引起问题(单线程)
目前最佳实践就是组合以上的几种,定时任务+pulsar/rocket本身时间轮等,多重组合,可以实现海量,超长时间的延迟消息
3.1 Apache Pulsar 云原生分布式消息流平台
Apache Pulsar也是基于死信队列实现延迟消息的。Pulsar 作为下一代云原生分布式消息流平台,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐以及低延时的高可扩展流数据存储特性,内置诸多其他系统商业版本才有的特性,是云原生时代解决实时消息流数据传输、存储和计算的最佳解决方案。

Apache Pulsar 提供了统一的消费模型,支持 Stream(如 Kafka)和 Queue(如 RabbitMQ)两种消费模型, 支持 exclusive、failover 和 shared 三种消费模式。同时,Pulsar 提供和 Kafka 兼容的 API,以及 Kafka-On-Pulsar(KoP) 组件来兼容 Kafka 的应用程序,KoP 在 Pulsar Broker 中解析 Kafka 协议,用户不用改动客户端的任何 Kafka 代码就能直接使用 Pulsar。
目前,Apache Pulsar 已经应用部署在国内外众多大型互联网公司和传统行业公司,案例分布在人工智能、金融、电信运营商、直播与短视频、物联网、零售与电子商务、在线教育等多个行业,如美国有线电视网络巨头Comcast、Yahoo!、腾讯、中国电信、中国移动、BIGO、VIPKID 等。
- 官网地址:http://pulsar.apache.org/
3.2 有赞延迟队列
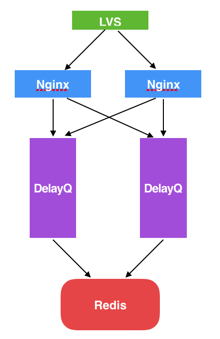
(1)整体结构
整个延迟队列由4个部分组成:
- Job Pool用来存放所有Job的元信息。
- Delay Bucket是一组以时间为维度的有序队列,用来存放所有需要延迟的/已经被reserve的Job(这里只存放Job Id)。
- Timer负责实时扫描各个Bucket,并将delay时间大于等于当前时间的Job放入到对应的Ready Queue。
- Ready Queue存放处于Ready状态的Job(这里只存放Job Id),以供消费程序消费。
如下图表述:

(2)网络拓扑
(3)生命周期
- 用户对某个商品下单,系统创建订单成功,同时往延迟队列里put一个job。job结构为:{‘topic’:‘orderclose’, ‘id’:'ordercloseorderNoXXX’, ‘delay’:1800 ,’TTR’:60 , ‘body’:’XXXXXXX’}
- 延迟队列收到该job后,先往job pool中存入job信息,然后根据delay计算出绝对执行时间,并以轮询(round-robbin)的方式将job id放入某个bucket。
- timer每时每刻都在轮询各个bucket,当1800秒(30分钟)过后,检查到上面的job的执行时间到了,取得job id从job pool中获取元信息。如果这时该job处于deleted状态,则pass,继续做轮询;如果job处于非deleted状态,首先再次确认元信息中delay是否大于等于当前时间,如果满足则根据topic将job id放入对应的ready queue,然后从bucket中移除;如果不满足则重新计算delay时间,再次放入bucket,并将之前的job id从bucket中移除。
- 消费端轮询对应的topic的ready queue(这里仍然要判断该job的合理性),获取job后做自己的业务逻辑。与此同时,服务端将已经被消费端获取的job按照其设定的TTR,重新计算执行时间,并将其放入bucket。
- 消费端处理完业务后向服务端响应finish,服务端根据job id删除对应的元信息。
(4)缺点和不足
- timer是通过独立线程的无限循环来实现,在没有ready job的时候会对CPU造成一定的浪费。
- 消费端在reserve job的时候,采用的是http短轮询的方式,且每次只能取的一个job。如果ready job较多的时候会加大网络I/O的消耗。
- 数据存储使用的redis,消息在持久化上受限于redis的特性。
- scale-out的时候依赖第三方(nginx)。
相关文档
- 有赞延迟队列设计
3.3 分布式任务调度 SchedulerX
分布式任务调度 SchedulerX 2.0 是阿里巴巴基于 Akka 架构自研的新一代分布式任务调度平台。您可以使用 SchedulerX 2.0 编排定时任务、工作流任务、进行分布式任务调度。
- 官方文档:SchedulerX
- 阿里分布式任务调度平台(目前公测期免费)地址:快速访问



)


)




)




)


