本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure Databricks】系列。
接上文 【Azure 架构师学习笔记】- Azure Databricks (2) -集群
前言
在对Databricks有了初步了解之后,如果要深入使用则需要对其进行更深层次的了解。
Databricks
ADB 是一个统一的数据和分析平台。它的主要用户是数据工程师,数据科学家和数据分析师。它是一个托管平台,可以让用户更加专注于数据的使用,而不用操心集群,库,依赖项,升级等与数据不相关的工作。
ADB 在这里特指Azure上的Databricks。它是托管在Azure上的Databricks,可以跟其他Azure 服务一样通过portal创建。意味着它已经原生化地集成到Azure,包括AAD, 其他数据工具等。要注意Databricks是一家公司的产品,Azure更多像是二房东。
Databricks的愿景是Lakehouse, 集中管理数据,使其成为"single source of truth"。 在过去, 数据仓库是主流,然而不适合时代的发展,比如数据架构的预设,很难应对非结构化数据的处理和分析。后来出现的data lakes如Hadoop, 虽然解决或缓解了一部分的问题,但是对于性能和可靠性,又成了一个新的问题。Lakehouse的出现就是为了整合这两类数据平台的优缺点。
Databricks其中一个核心特点是所有底层技术都是开源得,如Spark, Delta, ML Flow等。Databricks 把这些技术集成到一个统一平台并改进以便于企业开箱即用。
Databricks架构
Databricks作为一个统一得平台,不过在大型企业中,它不可能成为唯一的工具去实现所有的工作。所以需要其他工具进行协助,比如在Azure, ADB 用于ETL 和机器学习, Synapse用于进行BI的常规工作。另外也可以通过Power BI触发ADB在Storage Account上进行查询。

Spark
前面提到很多Spark,这是一个开源的,分布式的,基于内存的处理引擎。由于其速度比传统的Hadoop 工具快得多,它越来越受到大数据,机器学习工具的青睐。
在Databricks中,Spark是执行负载和查询的核心引擎,并且Databricks也是创建在原生的Spark之上。
Delta
Delta是一种特定的开源文件格式,用来解决传统数据湖文件格式的限制。在底层上Delta是由Parquet这种针对大数据优化的列存储结构,并添加了元数据和事务日志。它跟Parquet和ORC 的主要区别在于:
- ACID 事务
- 可以进行upserts操作。
- 可以进行索引化。
- 结合了流式和批处理特性,但是不需要使用复杂的Lambda架构。
SQL Analytics
Databricks提供了一个区域供用户进行基于Data Lake的SQL 的编写,即时输出简单的图形,还有基于SQL 的警告。
何时使用Databricks
- 当你的数据湖出现了性能问题,或者变得“混浊”时, 可以使用Delta对数据湖进行现代化改造。
- 机器学习:Databricks的其中一个强项就是机器学习。
- 大数据集成:从成本和性能来说,大数据的ETL 过程是Databricks的其中一个优势。
不适合用Databricks
- 即时查询:Spark是一个分布式引擎,其架构不适合进行即时查询的操作。
- 少量数据:对于GB或以下级别的数据,Databricks并不能发挥优势,反而成本很大。
- 低代码开发:相比于ADF 这类ETL 工具,ADB 主要使用代码进行操作,如果需要低代码的拖拉拽方式,那Databricks并不适合。
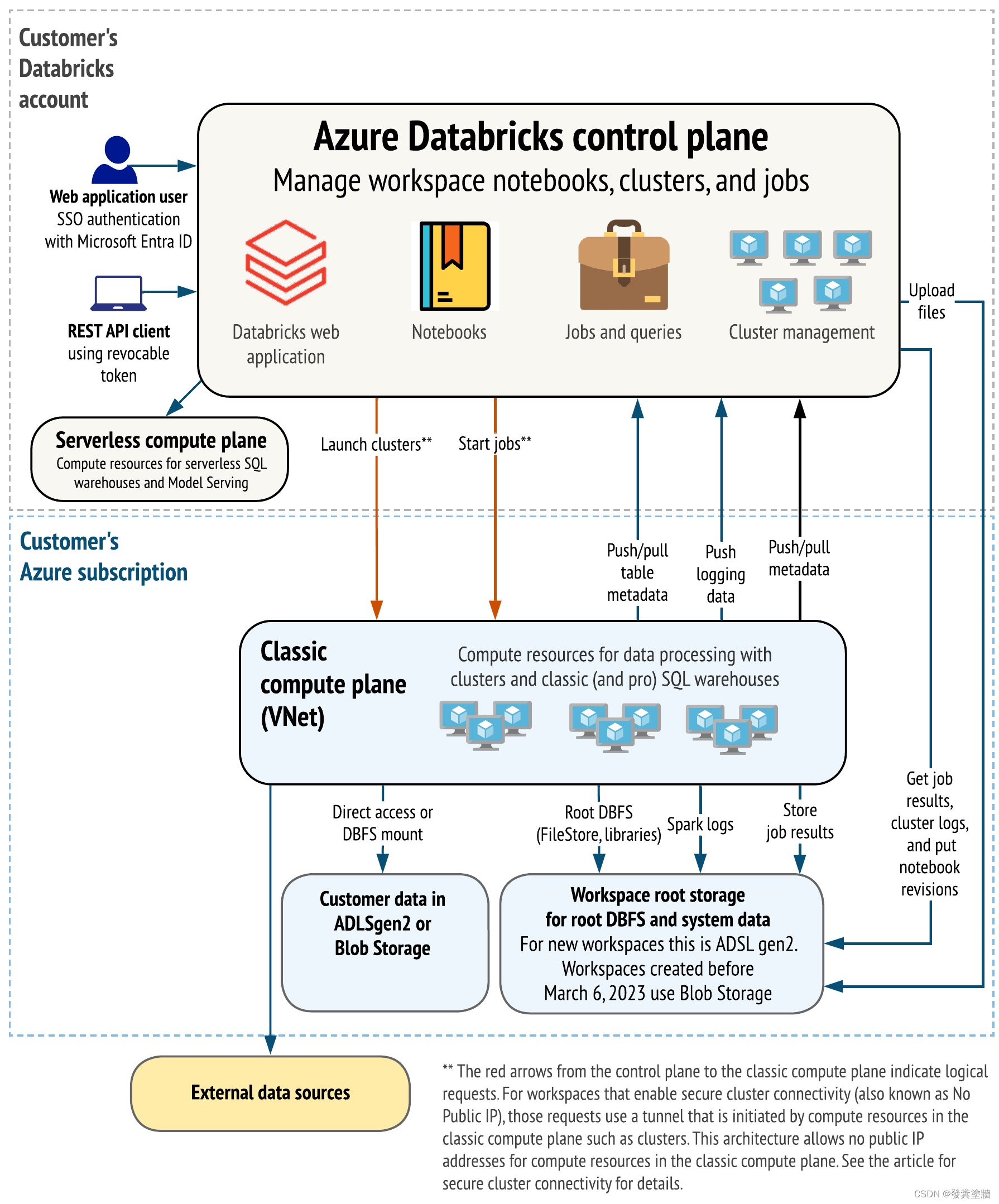
ADB 架构
跟绝大部分Azure资源类似,ADB 也分为Control Plane和Compute Plane(其他资源称为Data Plane)。
Control Plane控制着底层资源和服务,如Notebook, ADB 账号, workspace配置,存储加密等。
Compute plane是用于处理数据。
ADB 由于并不是微软自己开发的产品,微软对其只能进行集成和优化,比如ADB 需要data lake进行存储,需要特定网络访问集群等,这些都需要进行额外的配置,如托管VNet。
下面是来自微软的架构图:
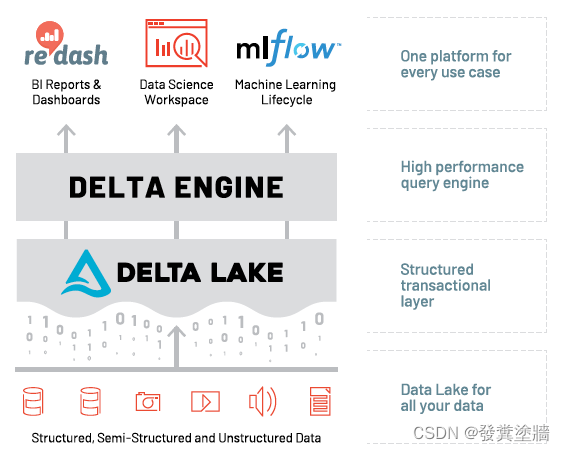
下图则从其他网站上复制,更加简化,适合入门者理解。配上了以下的简单描述:
- Delta Lake:存储层,帮助Data Lake更加可靠。它集成了流式计算和批处理,并且带有ACID 特性。完全兼容Apache Spark并可以运行在你现有的数据湖上。
- Delta Engine:对Delta Lake进行了优化处理的查询引擎。
- 其他内置工具使其能成为统一的数据处理平台。





)









)
)


