一、需求分析
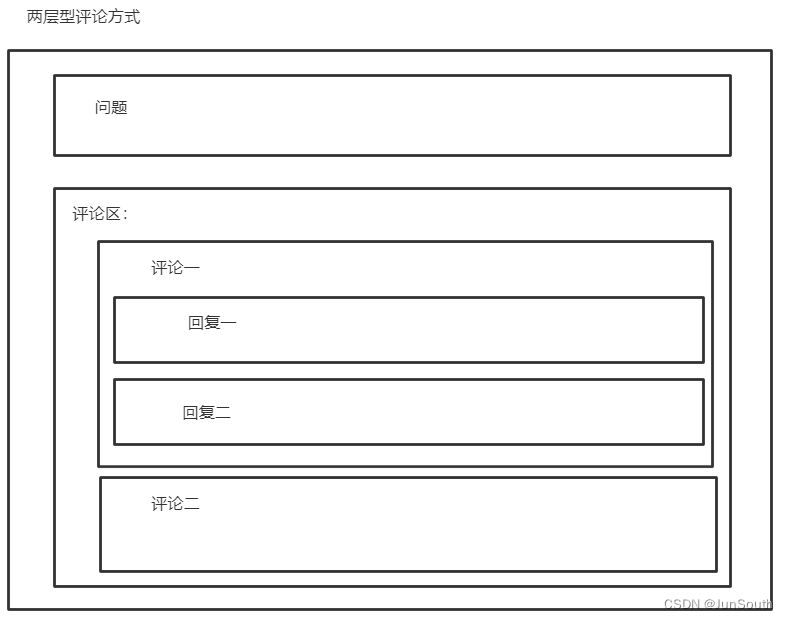
1.1、常见行为
1.敏感词过滤
2.新增评论(作品下、评论下)
3.删除评论(作品作者、上级评论者、本级作者)
4.上级评论删除关联下级评论
5.逻辑状态变更(上线、下线、废弃...)
6.上逻辑状态变更关联下级评论
7.评论通知(作品作者、上级评论作者)
8.点赞通知
9.评论回复(下级品论者)
10.评论的已读未读
11.评论的媒体文件处理(包情包、图片)
12.评论赞、踩
13.一级评论查询(分页、倒排)
14.上级评论关联下级评论(分页、倒排)
15.评论数量统计
16.可见范围(自己、上级、粉丝)
17.操作范围(允许他人评、点、踩)
18.评论置顶(权重排序)
19.作者点赞显示
1.2、数据特性
1.评论层级设计(两、三层)
2.数据量大如何存储、查询
3.赞、踩的高并发
二、使用案例
2.1、评论功能设计
2.1.1、表结构设计(暂用Mysql)
CREATE TABLE `cms_comments` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',`work_id` bigint DEFAULT NULL COMMENT '作品ID',`work_user_id` bigint DEFAULT NULL COMMENT '作品作者ID',`work_user_like` tinyint NOT NULL DEFAULT '1' COMMENT '作者点赞(1不赞,2点赞)',`comment_user_id` bigint DEFAULT NULL COMMENT '评论人ID',`comment_time` timestamp NULL DEFAULT NULL COMMENT '评论时间',`parent_id` bigint DEFAULT NULL COMMENT '上级ID(一级评论为作品ID)',`reply_user_id` bigint DEFAULT NULL COMMENT '被回复用户ID(三级时用)',`read_status` tinyint NOT NULL DEFAULT '1' COMMENT '阅读状态(1未阅读、2已阅读、3其它)',`level` tinyint NOT NULL DEFAULT '1' COMMENT '级别(1一级;2二级;3三级)',`state` char(2) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT '01' COMMENT '评论状态(01草稿、02待审核、03未通过、04已上线、05已下线、06删除)',`comment_content` varchar(150) DEFAULT NULL COMMENT '评论内容',`top_status` tinyint NOT NULL DEFAULT '1' COMMENT '置顶状态(1不置顶,2置顶)',`like_number` bigint DEFAULT '0' COMMENT '点赞数',`remark_number` bigint DEFAULT '0' COMMENT '评论数',PRIMARY KEY (`id`),KEY `work_id` (`work_id`) USING BTREE,KEY `work_user_id` (`work_user_id`) USING BTREE,KEY `comment_time` (`comment_time`),KEY `reply_user_id` (`reply_user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='内容评论表—JunSouth';2.1.2、接口设计
0.评论信息的敏感词过滤、审核。
1.新增评论信息(作品信息、上级信息、用户信息、级别、评论内容);附带功能:通知作品作者、上级作者、增加评论数量。
2.通过作品信息查询一级评论(分页、倒排、上线状态)。
3.通过一级评论信息查询二、三级评论(分页、倒排、上线状态)。
4.通过用户信息查询一级评论。
5.通过用户信息查询二、三级评论。
6.通知一级评论作者、二级评论作者回复信息。
7.通过作品信息下架一级、二级、三级评论。
8.通过一级评论信息下架一级、二级、三级评论。
9.通过二级评论信息下架二级、三级评论。
10.通过用户信息下架用户评论。
11.通过ID数组维护评论逻辑状态(管理端)。
12.通过ID数组物理删除评论信息(管理端)。
13.一级评论点赞(批量一次处理)。
14.一级评论数量统计(批量一次处理)。
15.作者队点赞。
16.一级评论置顶。
2.2、点赞、评论数功能设计
2.2.1、需求分析
1.无评论点赞细节应用,只统计单条评论的点赞数量 、评论数量
2.查频率高、写高并发
3.回显实时性要求高
4.传输数据量小
5.数据是单体小,整体范围大、量多
6.数据有冷热之分
7.数据价值低
2.2.2、接口设计
1.只记录评论赞的总数。
2.用户操作完后前端,调点赞接口,返回点赞结果。
3.后端通过评论ID为Key 操作Redis的Hyperloglog(基数),在此key的基础上+1,并返回结果,此Key的结果。
4.每隔1h,Redis的评论点赞数据同步到DB。
private final RedisTemplate redisTemplate;@PostMapping("/test001")
public R test001(@RequestBody Comment comment){String key = "commentId:"+comment.getId();Long userId = comment.getUserId();// 赛值redisTemplate.opsForHyperLogLog().add(key, userId);// 获取数量Long size = redisTemplate.opsForHyperLogLog().size(key);System.out.println("size(): "+size);return R.ok("Success",size);
}2.3、数据量过大—处理
低价值数据,且不涉及修改,和金额处理,可采用MongoDB数据库。
1.内置了 MapReduce 引擎,数据分片,水平扩展性好,便于做集群。
2.通过 Journal日志(预写日志)、Oplog日志(操作记录)保证数据可靠。
3.支持主键索引、单字段索引、组合索引等,基本与Mysql一致。
4.查询功能与 SQL 相似。
5.支持字段扩展。
-库缺少需要的入口点的原因与解决方案)

优化算法之梯度下降法(批量BGD、随机SGD、小批量))
进阶 RHEL 7 安装单机 Oracle 19C NON-CDB 数据库)









)




)
