规范化:
规范化是用于数据库设计的一系列原理和技术,它可以减少表中数据的冗余,增加数据完整性和一致性。通常有很多范式。
第一范式(1NF):
常用的三种范式:
表中的字段都是不可再分割的原子属性,同时表需要有一个主键
例如:

再实际开发中对业务需求的理解,对数据表做相应的设计。
第二范式(2NF):
首先需要满足第一范式,非主键字段必须完全依赖于主键字段,不能只依赖于主键的一部分。
例:
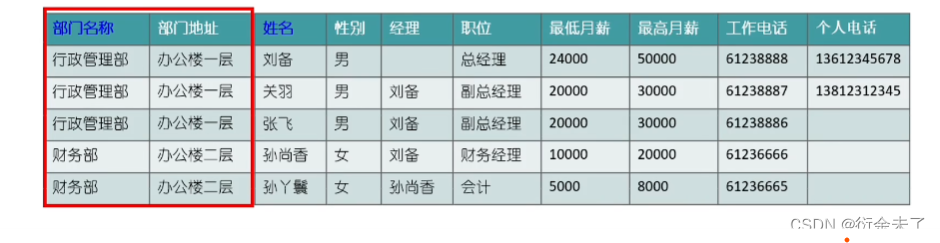
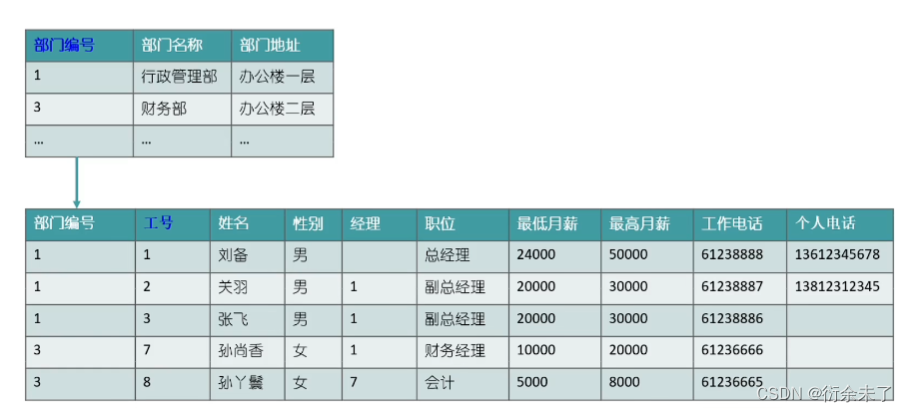
在上表中有俩个主键,复合主键,中部门地址只需要依赖部门名称即可,不需要依赖姓名,没有完全依赖全部主键,这种情况我们可以给部门单独分为部门表。避免冗余。
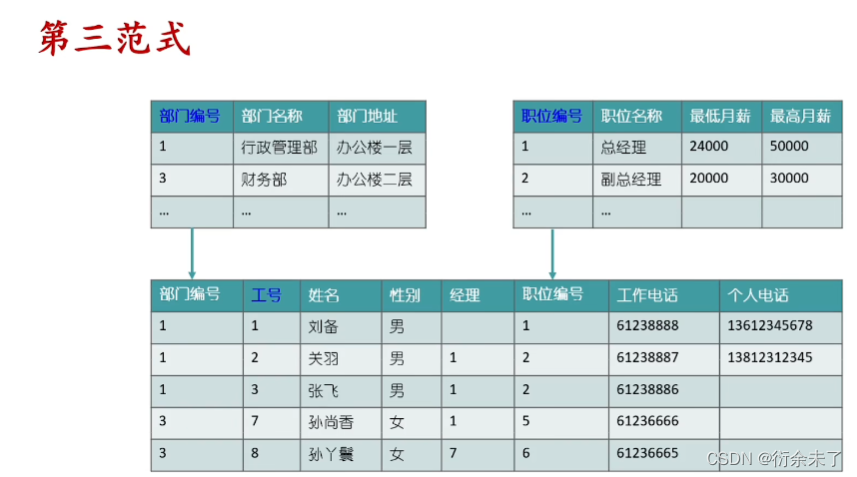
第三范式(3NF):
首先需要满足第二范式,非主键字段不能依赖于其他非主键字段。

上表中我们想知道各个职位相关的薪资,职位和薪资存在依赖关系,无法和工号直接产生依赖关系。一个表存在传递依赖,不符合第三范式。继续拆分一个职位表。
反规范化:
为了提高查询性能可以降低规范化的级别,也就是反规范化(Denormalization)。
常用的反规范化技术包括:
- 增加冗余字段
- 增加计算列
- 将小表合大表

)

)




)





)
![[c]零钱兑换](http://pic.xiahunao.cn/[c]零钱兑换)


 高级篇 20 -- SNOOPer 使用介绍】)
