Evidently 是一个面向数据科学家和机器学习工程师的开源 Python 库。它有助于评估、测试和监控从验证到生产的数据和 ML 模型。它适用于表格、文本数据和嵌入。
简介
Evidently 是一个开源的 Python 工具,旨在帮助构建对机器学习模型的监控,以确保它们的质量和在生产环境运行的稳定性。
它可以用于模型生命周期的多个阶段:作为 notebook 中检查模型的仪表板,作为 pipeline 的一部分,或者作为部署后的监控。
Evidently 特别关注模型漂移,同时也提供了模型质量检查、数据质量检查和目标漂变监测等功能。此外,它还提供了多种内置的指标、可视化图形和测试,可以轻松地放入报告、仪表板或测试驱动的 pipeline 中。
功能
Evidently采用了由 3 个组件组成的模块化方法:报告、测试套件和监控仪表板。
它们涵盖不同的使用场景:从临时分析到自动化管道测试和持续监控。
1. 测试套件:批量模型检查
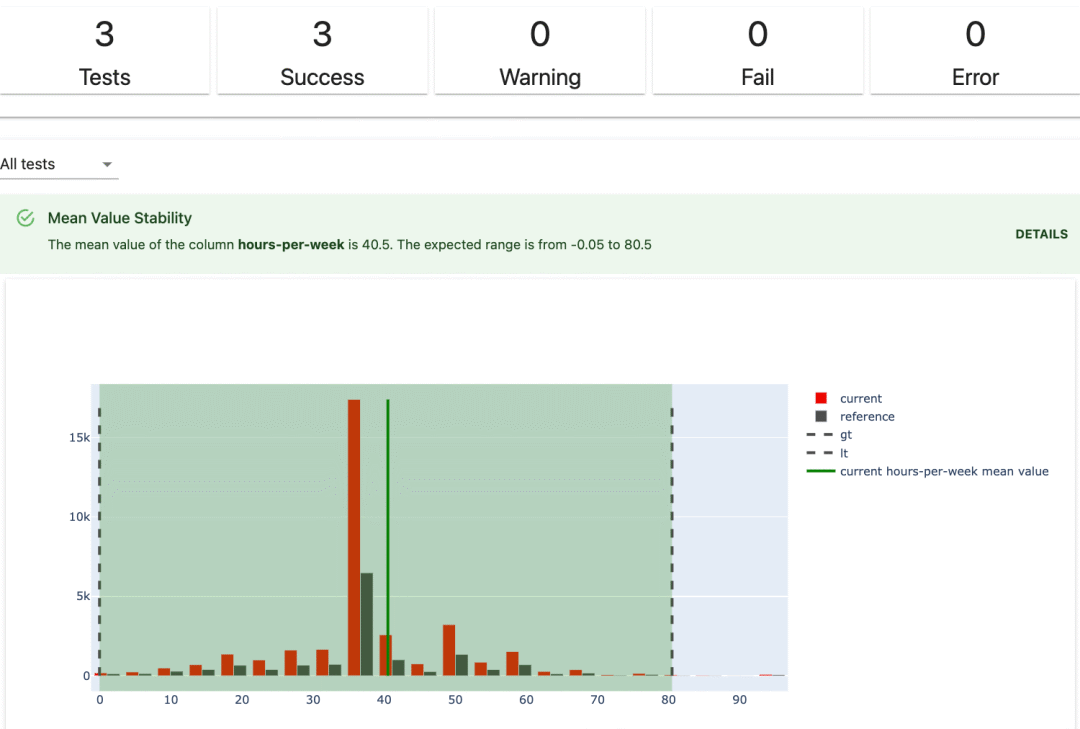
测试执行结构化数据和机器学习模型质量检查,可以手动设置条件,也可以让 Evidently 根据参考数据集生成条件,返回明确的通过或失败结果。可以从 50 多个测试创建测试套件或运行预设之一。例如,测试数据稳定性或回归性能。
输入:一个或两个数据集,如 pandas.DataFrames 或 csv。
获取输出:在 Jupyter Notebook 或 Colab 中,导出 HTML、JSON 或 Python 字典。
主要用例:基于测试的机器学习监控,以将测试作为机器学习管道中的一个步骤来运行。例如,当收到一批新的数据、标签或生成预测时。可以根据结果构建条件工作流程,例如触发警报、重新训练或获取报告。
2. 报告:交互式可视化
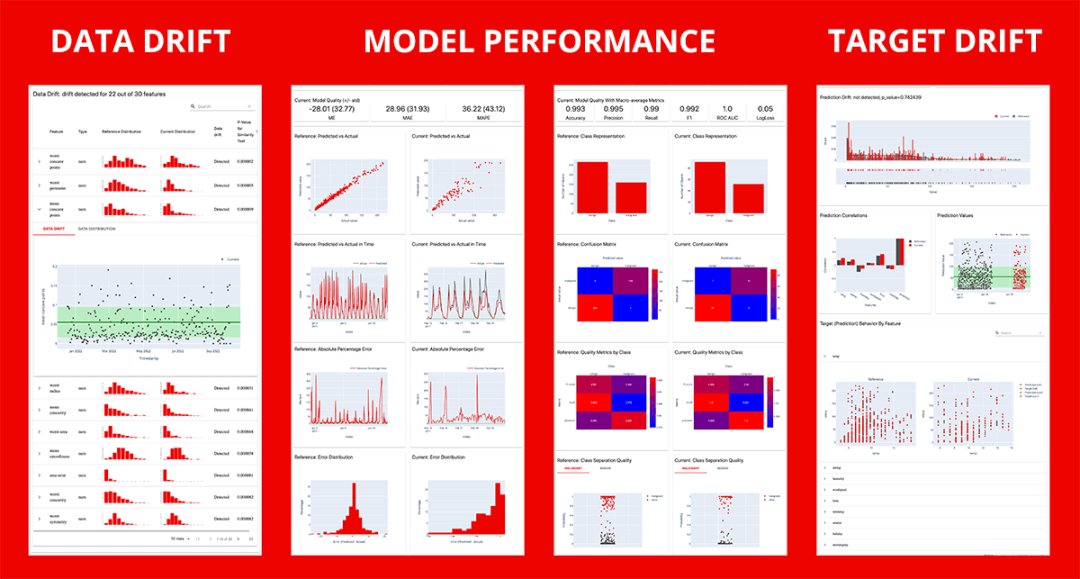
计算各种指标并提供丰富的交互式可视化报告,可以根据各个指标创建自定义报告,或运行涵盖模型或数据性能特定方面的预设。例如,数据质量或分类性能。
输入:一个或两个数据集,如 pandas.DataFrames 或 csv。
如何获取输出:在 Jupyter Notebook 或 Colab 中,导出 HTML 文件、JSON 或 Python 字典。
主要用例:分析和探索,有助于直观地评估数据或模型性能。例如,在探索性数据分析期间、对训练集进行模型评估、调试模型质量衰减时或比较多个模型时。
3. 机器学习监控仪表板
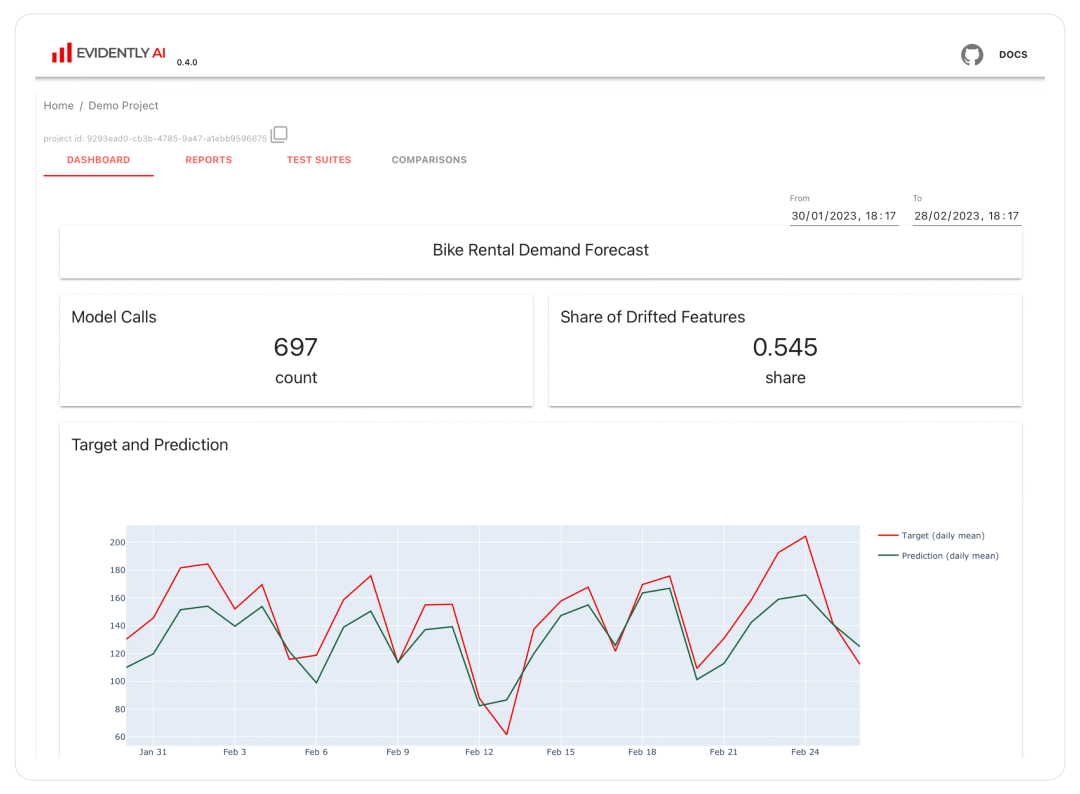
您可以自行托管机器学习监控仪表板,以随着时间的推移可视化指标和测试结果。此功能位于报告和测试套件之上,必须将它们的输出存储为 Evidently JSON snapshots,作为 Evidently Monitoring UI 的数据源。
输入:snapshots,记录到对象存储中。
输出:可作为网络应用程序使用的自托管仪表板。
主要用例:当需要实时仪表板来查看一段时间内的所有模型和指标时,持续监控。
安装&使用
pip install evidently
pip install jupyter
# 安装 jupyter Nbextion
pip install jupyter_contrib_nbextensions
# 在 jupyter 扩展中安装并启用 evidently
jupyter nbextension install --sys-prefix --symlink --overwrite --py evidently
jupyter nbextension enable evidently --py --sys-prefix
大部分情况下,需要在Jupyter notebook中使用。
使用步骤很简单,一般分三步:1、导入模块 2、处理数据 3、获取报告
举个例子,先导入所需模块
import pandas as pd
import numpy as npfrom sklearn.datasets import fetch_california_housingfrom evidently import ColumnMappingfrom evidently.report import Report
from evidently.metrics.base_metric import generate_column_metrics
from evidently.metric_preset import DataDriftPreset, TargetDriftPreset, DataQualityPreset, RegressionPreset
from evidently.metrics import *from evidently.test_suite import TestSuite
from evidently.tests.base_test import generate_column_tests
from evidently.test_preset import DataStabilityTestPreset, NoTargetPerformanceTestPreset
from evidently.tests import *
导入和处理数据
data = fetch_california_housing(as_frame=True)
housing_data = data.framehousing_data.rename(columns={'MedHouseVal': 'target'}, inplace=True)
housing_data['prediction'] = housing_data['target'].values + np.random.normal(0, 5, housing_data.shape[0])reference = housing_data.sample(n=5000, replace=False)
current = housing_data.sample(n=5000, replace=False)
获取报告
report = Report(metrics=[DataDriftPreset(),
])report.run(reference_data=reference, current_data=current)
report
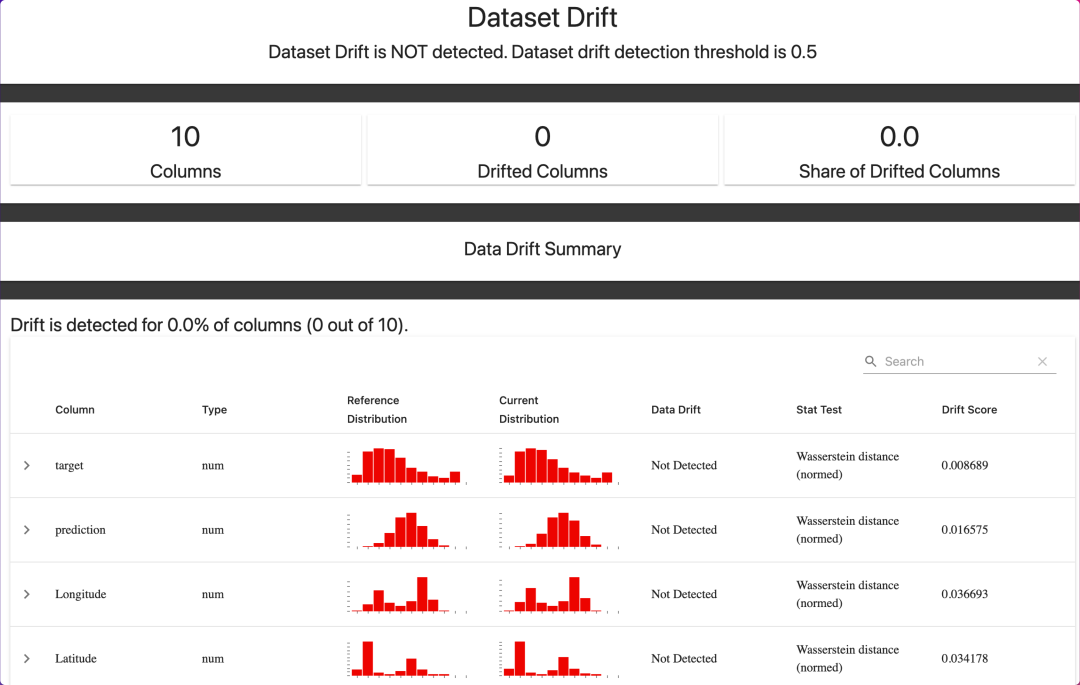
官方提供了很多获取报告的代码模板:https://docs.evidentlyai.com/presets/all-presets
evidently 功能十分强大,这里展示的只是其能力的冰山一角。了解更多,可以参考以下链接:
官网:https://www.evidentlyai.com/
文档:https://docs.evidentlyai.com/
开源地址:https://github.com/evidentlyai/evidently
材料获取
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
资料干货、资料分享、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88194,备注:来自CSDN + 资料
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复: 资料
1、数据分析实战宝典

2、100个超强算法模型
我们打造了《100个超强算法模型》,特点:从0到1轻松学习,原理、代码、案例应有尽有,所有的算法模型都是按照这样的节奏进行表述,所以是一套完完整整的案例库。
很多初学者是有这么一个痛点,就是案例,案例的完整性直接影响同学的兴致。因此,我整理了 100个最常见的算法模型,在你的学习路上助推一把!

)





)
)











