一、自监督学习(Self-supervised Learning)
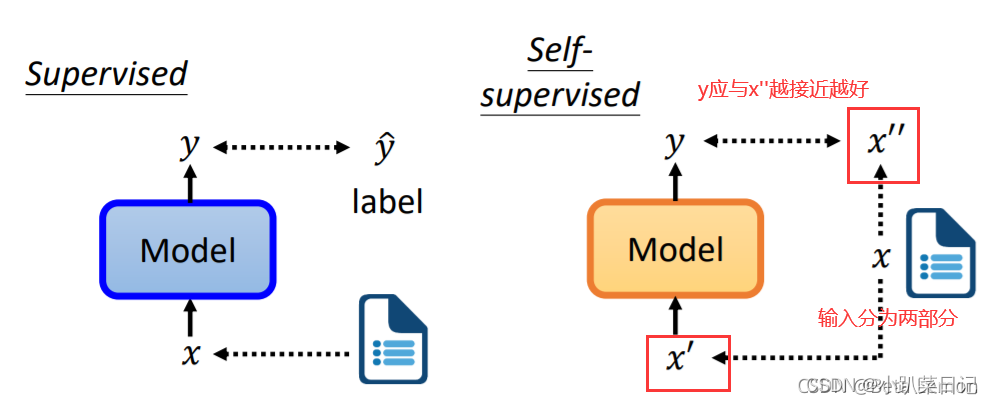
在监督学习中,模型的输入为x,若期望输出是y,则在训练的时候需要给模型的期望输出y以判断其误差——有输入和输出标签才能训练监督学习的模型。
自监督学习在没有标注的训练集中,把训练集分为两部分,一个作为输入,另一个作为模型的标签。自监督学习是一种无监督学习的方法。
二、Contextualized Word Embedding

从上下文中学习word embedding,同样一个词在不同的上下文中会学到不同的word embedding
三、ELMO
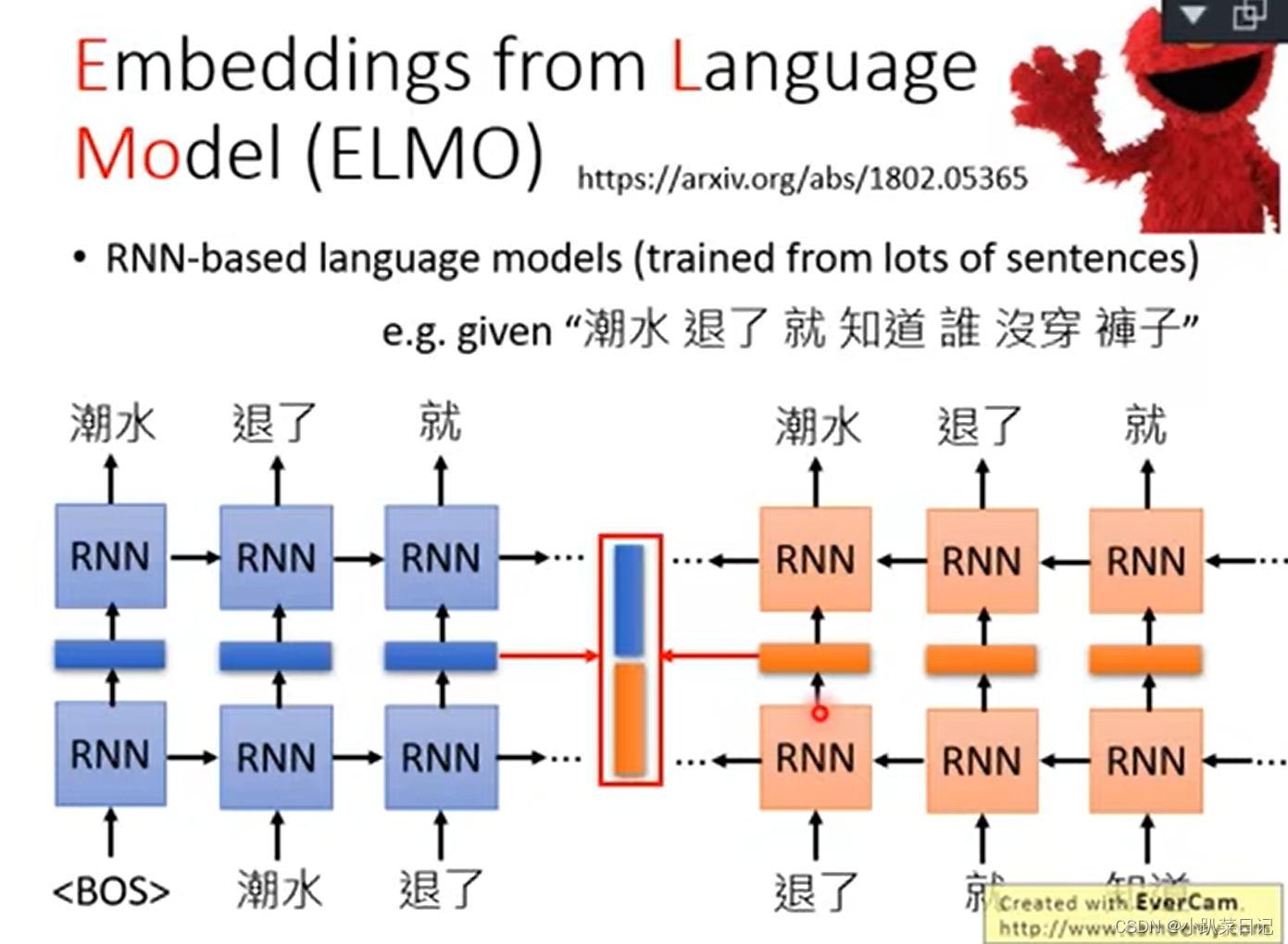
以双向RNN为基础,最初输入的词汇的token,通过学习得到embedding,中间hidden layer的就是输入词汇的embedding。图中的蓝色块是正向学到的embedding,黄色块是逆向得到的embedding,将二者接起来

如果是deep RNN,每层的embedding都留着,以不同的权重阿尔法1、阿尔法2等将每层的embedding和原始token相加得到最终的embedding
阿尔法1、阿尔法2的大小如何确定:在执行不同的下游任务时,与下游任务的参数一起训练。那么不同的下游任务训练出的阿尔法1、阿尔法2也不同

四、BERT
bert先在未标记的文本语料库上训练pre-training(自监督学习),但 它本身没有什么用,BERT 只能做填空题, 然后在少量的标记数据上做fine-tuning,把它用在其他下游的任务里面
bert pre-training两种方法(在未标记的文本语料库上训练的)
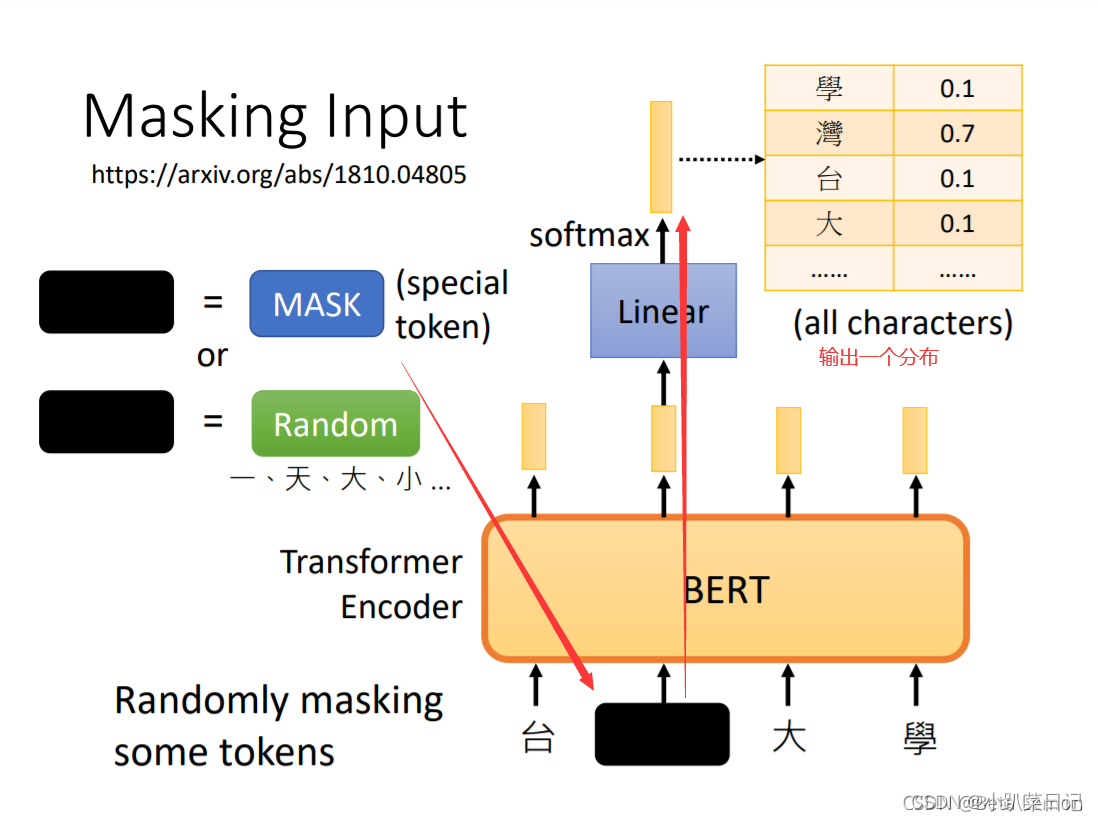
第一种方法masking input:mask掉(换成某种特殊的token [MASK])或替换15%的词 输出对该单词的预测
BERT并不知道我们遮盖住的文字,因此BERT的目标就是最小化输出 y和期望值 y ’的误差,损失函数使用交叉熵。

第二种方法next sentence prediction:同时利用第一种办法的mask 输出这两个句子是否相接

bert fune-tuning四种例子(在有标记的数据上训练):
该部分bert参数是由 bert pre-training中参数初始化的
fune-tuning过程中linear classifier参数从头学,bert参数微调即可
1:句子分类(情感分析) 输入一个句子 输出句子类别

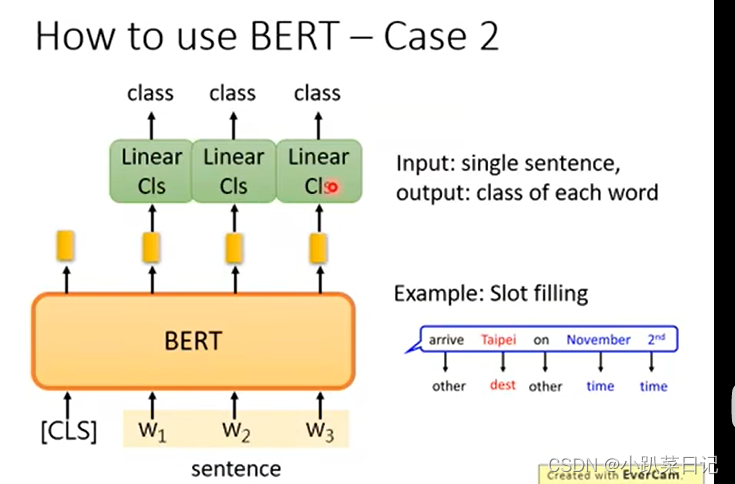
2. 对每个单词分类(词性标注(POS tagging)) 输入一个句子 输出每个单词类别
3.前提假设(自然语言推理(NLI)) 输入两个句子 输出该前提是否支持假设
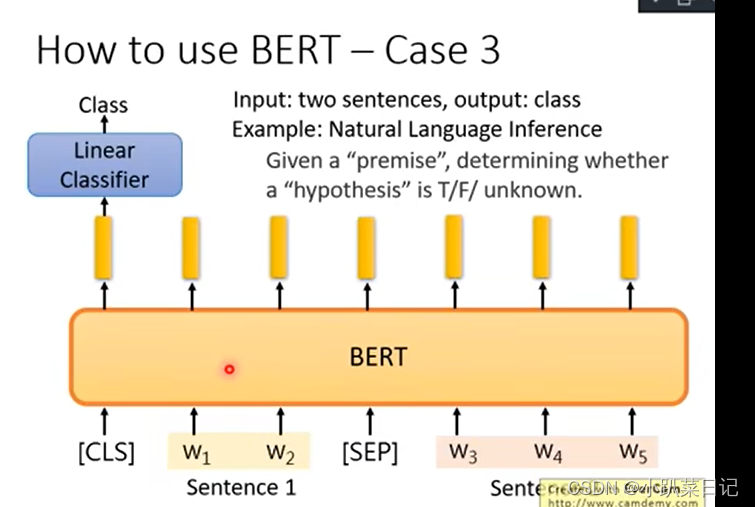
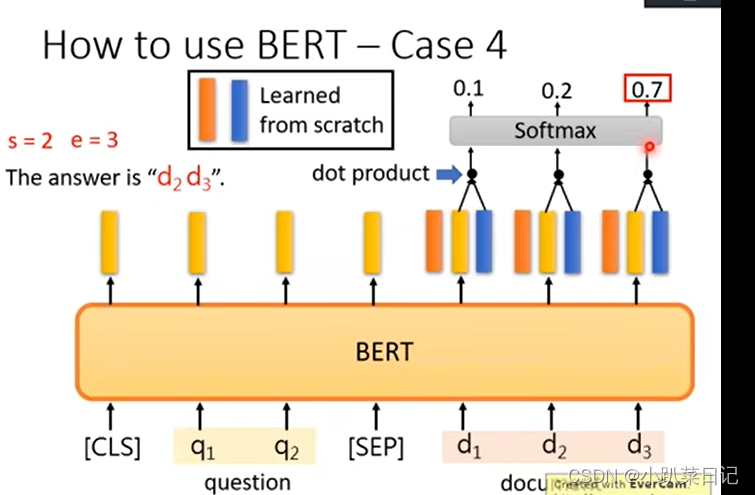
4.回答问题(基于信息抽取的问答系统(QA))输入文章和问题 输出答案


其他内容
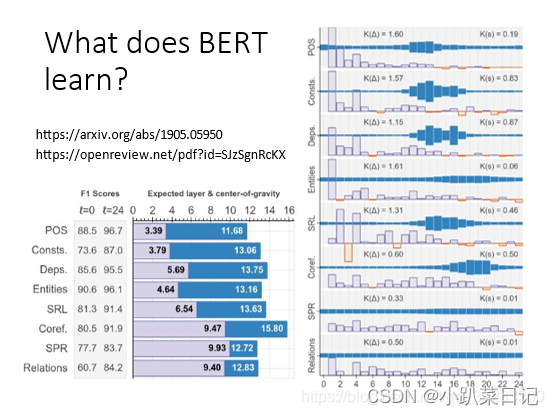
What does BERT learn?
分析一下BERT每一层究竟学到了什么。假设BERT有24层,文献上的意思是,第一层是分析词性,第二层是分析语法,第三层是词汇之间的关系,以此类推。文献的做法是将每一层做weight sum,任务不同,比如词性和语法任务,那么每一层的权值也不同,根据权值来判断这一层主要是贡献什么。接近input的层就做简单的任务,而接近output的层就做困难的任务。下图右侧中蓝色的条越长,证明该层对总任务贡献更大
参考:
李宏毅《深度学习》 - BERT_李宏毅 bert ppt_Beta Lemon的博客-CSDN博客
李宏毅机器学习--self-supervised:BERT、GPT、Auto-encoder-CSDN博客
ELMO,BERT和GPT的原理和应用总结(李宏毅视频课整理和总结)-CSDN博客




:对数组数据的拆分和分组合并)




和np.any()的常见用法(干货!!!))





 - 重复打印)



