Course2-Week2-神经网络的训练方法
文章目录
- Course2-Week2-神经网络的训练方法
- 1. 神经网络的编译和训练
- 1.1 TensorFlow实现
- 1.2 损失函数和代价函数的数学公式
- 2. 其他的激活函数
- 2.1 Sigmoid激活函数的替代方案
- 2.2 如何选择激活函数
- 2.3 为什么需要激活函数
- 3. 多分类问题和Softmax函数
- 3.1 多分类问题
- 3.2 逻辑回归的推广:Softmax回归
- 3.3 Softmax神经网络的代码实现
- 3.4 多标签问题
- 4. 更加高级的神经网络概念
- 4.1 梯度下降法的改进:Adam算法
- 4.2 其他类型的神经网络层
- 4.3 神经网络代码实例——手写数字识别
- 5. 反向传播(选修)
- 5.1 计算图和导数
- 5.2 神经网络中的反向传播
- 笔记主要参考B站视频“(强推|双字)2022吴恩达机器学习Deeplearning.ai课程”。
- 该课程在Course上的页面:Machine Learning 专项课程
- 课程资料:“UP主提供资料(Github)”、或者“我的下载(百度网盘)”。
- 本篇笔记对应课程 Course2-Week2(下图中深紫色)。

1. 神经网络的编译和训练
1.1 TensorFlow实现
上周演示了如何定义一个神经网络并使用其进行“推理”,本周就来学习剩余的的“编译”和“训练”:
- 编译
compile():输入参数有“损失函数loss”、“优化器optimizer”、“评估指标metrics”。主要考虑前两项。
- “损失函数
loss”:决定了神经网络的代价函数。在“训练”的某次迭代结束后,利用输出层的输出结果与真实目标值之间的差异计算神经网络的代价。进而可以通过反向传播更新参数。- “优化器
optimizer”:则是“梯度下降法”的升级版,可以选择性能更强大、收敛速度更快的迭代算法。- “评估指标
metrics”:和“训练”本身没有关系,和损失函数没有关系。只是在“训练”的单次迭代结束后,衡量一下所有训练集的推理结果与真实值之间的差异。loss也有此作用,但是不直观;metrics可以选择更加直观的指标,比如metrics='accuracy'可以计算“推理正确的训练样本”的百分比。# compile()函数所有的可选选项及其示例 model.compile(loss=tf.keras.losses.BinaryCrossentropy(),optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),metrics='accuracy' )参考Keras官网说明文档:The
compile()method: specifying a loss, metrics, and an optimizer。
- 训练
fit():有非常多的指标可以设置,但我们现在仅关心“数据集”、“迭代次数epchos”即可(下面代码示例的前三项)。注意每次迭代都会使用到所有的训练集样本,若样本太多,程序会自动将数据分批。并且,运行fit()函数后,会自动打印输出训练过程。# fit()函数所有的可选选项及其示例(ChatGPT) model.fit(x=None, # 输入数据y=None, # 标签epochs=1, # 训练轮数batch_size=None, # 指定进行梯度下降时每个批次包含的样本数verbose=1, # 控制训练过程中的日志输出,0:不输出日志,1:输出进度条记录,2:每个epoch输出一行记录callbacks=None, # 在训练过程中调用的回调函数列表validation_split=0.0, # 用于验证的训练数据的比例validation_data=None, # 用于验证的数据,可以是输入数据和标签的元组shuffle=True, # 是否在每个epoch之前随机打乱输入数据class_weight=None, # 类别权重sample_weight=None, # 样本权重initial_epoch=0, # 开始训练的epoch值steps_per_epoch=None, # 每个epoch包含的步数,当为None时,将自动计算validation_steps=None, # 在每个epoch结束时执行验证的步数,当为None时,将自动计算validation_batch_size=None, # 用于验证的批次大小validation_freq=1, # 仅在`validation_data` 的某些训练轮上进行验证max_queue_size=10, # 生成器队列的最大尺寸workers=1, # 使用的生成器工作进程数use_multiprocessing=False, # 是否使用多进程生成器**kwargs ) # 运行fit()函数后,会自动打印输出训练过程,下面为单次迭代的输出示例 Epoch 1/40 157/157 [==============================] - 1s 1ms/step - loss: 1.5179 - accuracy: 0.5406参考Keras官网说明文档:Training & evaluation using
tf.dataDatasets。若没跳转到相应位置就按照标题翻翻。
熟悉了上面的选项之后,回到简化的“手写数字识别”问题,其训练代码如下,主要看“编译model.compile()”和“训练model.fit()”:

- 定义神经网络。定义神经网络的层数、每层神经元数量、激活函数。和之前相同。
- 编译神经网络。关键在于确定损失函数,由于是二元分类问题所以选取了“二元交叉熵损失函数”。
- 训练神经网络。
X,Y为训练集、epochs为迭代次数,也就是“梯度下降法”的迭代次数,每次迭代都会使用全部训练集的数据。
1.2 损失函数和代价函数的数学公式

上一节介绍了“编译”和“训练”的实现代码,那“编译”中所配置的“二元交叉熵损失函数”到底是什么呢?其实,其定义和“逻辑回归”中的损失函数相同。在统计学中,损失函数形式是“交叉熵”(如下式),而“二元”只是强调输出为二元分类,所以称之为“二元交叉熵损失函数”。下面是“手写数字识别”神经网络的损失函数和代价函数:
Loss Function: L ( f ( x ⃗ ) , y ) = − y l o g ( f ( x ⃗ ) ) − ( 1 − y ) l o g ( 1 − f ( x ⃗ ) ) Cost Function: { J ( W , B ) = 1 m ∑ i = 1 m L ( f ( x ⃗ ) , y ) , W = [ W [ 1 ] , W [ 2 ] , W [ 3 ] ] , B = [ b ⃗ [ 1 ] , b ⃗ [ 2 ] , b ⃗ [ 3 ] ] . \begin{aligned} \text{Loss Function:} & \; L(f(\vec{x}),y) = -ylog(f(\vec{x})) - (1-y)log(1-f(\vec{x})) \\ \text{Cost Function:} & \; \left\{\begin{aligned} & J(\bold{W},\bold{B}) = \frac{1}{m}\sum_{i=1}^{m}L(f(\vec{x}),y), \\ & \bold{W}=[\bold{W}^{[1]}, \bold{W}^{[2]}, \bold{W}^{[3]}], \\ & \bold{B}=[\vec{\bold{b}}^{[1]}, \vec{\bold{b}}^{[2]}, \vec{\bold{b}}^{[3]}]. \end{aligned}\right. \end{aligned} Loss Function:Cost Function:L(f(x),y)=−ylog(f(x))−(1−y)log(1−f(x))⎩ ⎨ ⎧J(W,B)=m1i=1∑mL(f(x),y),W=[W[1],W[2],W[3]],B=[b[1],b[2],b[3]].
假设神经网络输入为20x20图片,于是输入特征 x ⃗ \vec{x} x 长度为400。
- L ( f ( x ⃗ ) , y ) L(f(\vec{x}),y) L(f(x),y):单个样本的损失函数,其中的 ( x ⃗ , y ) (\vec{x},y) (x,y) 是训练集中的单个样本。注意只有输出层才计算损失函数。
- W [ 1 ] \bold{W}^{[1]} W[1]: 400 × 25 400×25 400×25 的二维矩阵。同理, W [ 2 ] \bold{W}^{[2]} W[2] 维度为 25 × 15 25×15 25×15、 W [ 3 ] \bold{W}^{[3]} W[3] 维度为 15 × 1 15×1 15×1。
- b ⃗ [ 1 ] \vec{\bold{b}}^{[1]} b[1]:长度 25 25 25 的向量。同理, b ⃗ [ 2 ] \vec{\bold{b}}^{[2]} b[2] 长度为 15 15 15、 b ⃗ [ 3 ] \vec{\bold{b}}^{[3]} b[3]长度为 1 1 1。
- W \bold{W} W:三个二维矩阵的列表,也就是表示神经网络的全部 w w w 参数。
- B \bold{B} B:三个向量的列表,也就是表示神经网络的全部 b b b 参数。
- J ( W , B ) J(\bold{W},\bold{B}) J(W,B):所有样本的损失平均值,也就是代价函数。
在代码中,Keras库最初是独立的数学函数库,后来被TensorFlow收录,所以TensorFlow使用Keras库来定义损失函数。这也是最初的代码中,从keras导入损失函数的原因。当然记住所有的损失函数名称并不现实,需要的时候问问ChatGPT就行。当然上述是对“分类问题”的代码,如果想编译“回归问题”,可以采用下面的代码(注意修改损失函数):
# 回归问题中,使用“平方差损失函数”编译模型
from tensorflow.keras.losses import MeanSquareError
model.compile(loss = MeanSquareError())
当前,最后还有一点就是怎么求解代价函数的偏导。显然“训练”的过程就是最小化代价函数,若使用“梯度下降”,那么每一次迭代,就要求计算代价函数对每一层每个神经元的每个参数的偏导。这工作量想想就惊人!更别说神经网络很难求出显式的偏导表达式。所以实际上,神经网络的“训练”使用“反向传播(back propogation)”来进行迭代,可以大大节省计算量。TensorFlow将上述“反向传播”寻找最低点的过程全部封装在model.fit()函数中,并迭代设定好的次数epochs,“5.反向传播”一节将进行介绍其数学原理。
现在知道如何训练一个基本的神经网络,也被称为“多层感知器”。下面几节将继续介绍一些改进,使神经网络的性能更好。
本节 Quiz:
Here is some code that you saw in the lecture:
model.compile(loss=BinaryCrossentropy()). For which type of task would you use the binary cross entropy loss function?
×BinaryCrossentropy()should not be used for any task.
× A classification task that has 3 or more classes (categories).
√ Binary classification (classification with exactly 2 classes).
× Regression tasks (tasks that predict a number).Which line of code updates the network parameters in order to reduce the cost?
model= Sequential([Dense(units=25, activation='sigmoid),Dense(units=15, activation=' sigmoid"),Dense(units=1 , activation='sigmoid')]) model.compile(loss=BinaryCrossentropy()) model.fit(X, y, epochs=100) √
2. 其他的激活函数
再继续介绍“编译”和“训练”之前,我们来继续看看其他的“激活函数”。这可以首先帮助我们优化整个神经网络。
2.1 Sigmoid激活函数的替代方案
由于前面介绍了“逻辑回归”,于是我们将每个神经元都看成一个小的逻辑回归单元,所以目前一直使用Sigmiod函数作为隐藏层和输出层所有神经元的激活函数。但Sigmoid函数显然也有其局限性。比如下面的“需求预测”问题,我们最开始假设隐藏层输出的有“心理预期价格”、“认可度”、“产品质量”,但实际上这些指标并不一定都为0~1之间的小数字,比如“认可度”可以有“不认可”、“一般认可”、“极度认可”、“完全传播开来”等。于是我们不妨将“认可度”的范围扩展为到所有“非负数”,也就是从0到非常大的数字。也就是ReLU函数(Rectified Linear Unit, 修正线性单元):
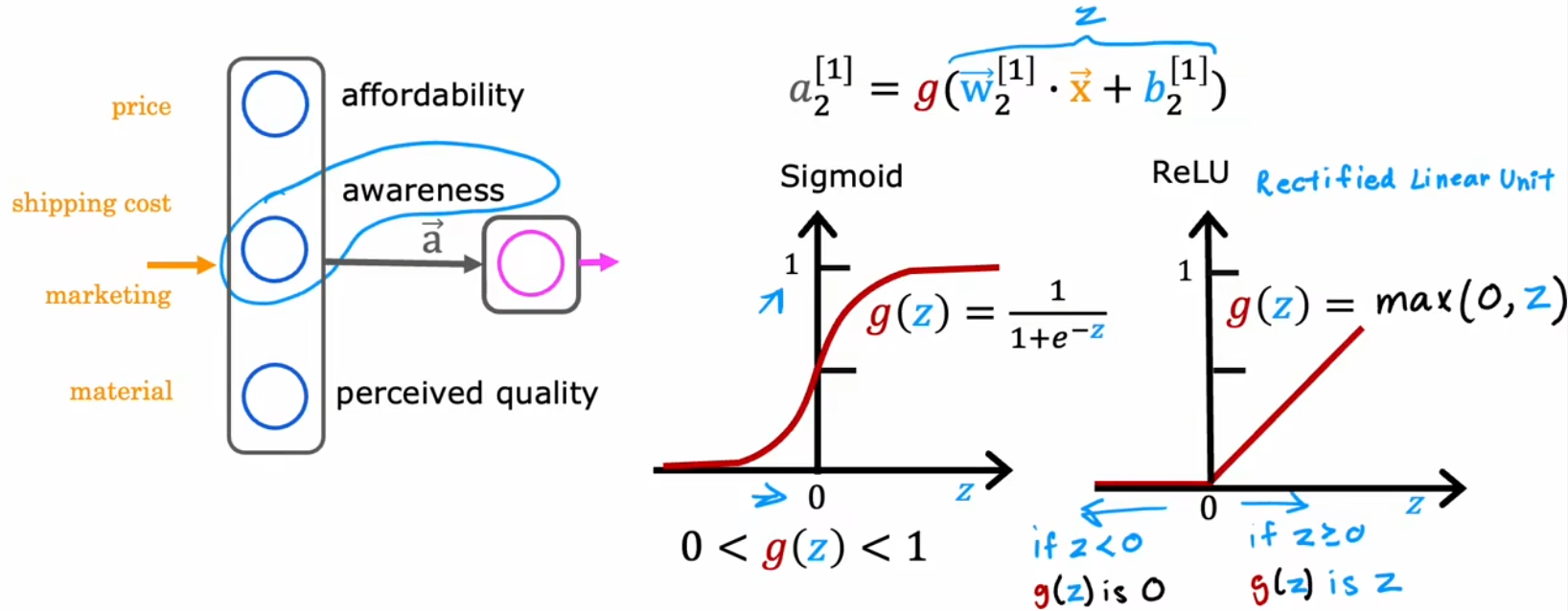
于是,这启示我们,激活函数的形状应该和输出范围有关,下面就是三种常见的激活函数:

- 线性激活函数: g ( z ) = z g(z)=z g(z)=z,人们也会称之为“没有使用任何激活函数”。
- Sigmoid函数: g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1,常见于“二元分类问题”。
- ReLU函数: g ( z ) = max ( 0 , z ) g(z)=\max(0,z) g(z)=max(0,z),经常作为默认激活函数。
- Softmax函数:“第三节”讨论多分类问题时进行介绍。
合理使用上述激活函数可以进一步提升神经网络性能,进而构建各种各样的强大的神经网络。
2.2 如何选择激活函数
那该如何选择激活函数呢?首先我们从输出层开始。输出层的激活函数通常取决于“目标值”,比如二元分类问题就使用Sigmoid函数、如果预测股票涨跌的回归问题就使用线性激活函数(因为有正有负)、如果是“预测房价”这样的回归问题就使用ReLU函数(因为房价非负)。而对于隐藏层来说,若无特殊原因,所有隐藏层的神经元都应选择ReLU函数。最早人们都默认使用Sigmoid函数,但是现在逐渐演变成默认使用ReLU函数,主要有以下几个原因:
- ReLU函数形式更简单、计算更快。
- ReLU仅在负数域平坦,而Sigmoid函数在正负两侧都平坦。而平坦的区域越大,会导致代价函数平坦的区域越大,“梯度下降”等算法训练模型的速度就越慢。
总结:“输出层”按照“目标值”取值范围选取,“隐藏层”默认全部采用ReLU函数(如下图)。

对于大多数情况、大多数应用来说,上述介绍的几个激活函数已经够用了。当然还有其他激活函数,比如Tanh函数、Leaky ReLU函数、Swish函数等。每隔几年,研究人员都会提出新的激活函数,这些激活函数在某些方面的性能确实会更好。想了解的话可以自行查阅。
2.3 为什么需要激活函数
既然ReLU函数比Sigmoid函数计算更快,那能不能默认使用更简洁的“线性激活函数”呢?换句话说,能不能不使用激活函数呢?显然是不行的。由于“线性函数的线性组合还是线性函数”,若只使用线性激活函数,整个神经网络就会退化成“线性回归”,所以 尽量不在隐藏层使用线性激活函数。使用其他的非线性函数,比如ReLU函数,只要有足够多的神经元,通过调整参数就可以拟合出任意的曲线,进而实现神经网络想要的拟合效果。
下面是ChatGPT给出的激活函数的几个作用:
- 引入非线性:激活函数引入了非线性变换,使神经网络能够学习和表示复杂的非线性关系。如果没有激活函数,神经网络将仅能够表示线性映射,限制了其表达能力。
- 特征映射:激活函数能够将输入映射到另一种表示形式,使得网络能够学习到数据中的更高阶的特征。不同的激活函数对输入数据的映射方式不同,因此选择合适的激活函数有助于提取关键特征。
- 输出范围控制:激活函数可以控制神经元的输出范围。例如,Sigmoid 函数将输入映射到 (0, 1) 范围,适用于二分类问题,而 Tanh 函数将输入映射到 (-1, 1) 范围。这有助于输出符合任务要求的范围。
- 处理梯度消失问题:激活函数的选择也与梯度消失问题有关。某些激活函数(如 Sigmoid 和 Tanh)在输入较大或较小时,梯度可能趋于零,导致梯度消失问题。ReLU 和其变种等激活函数对于缓解这个问题有一定帮助。
- 稀疏激活:一些激活函数能够产生稀疏激活,即只有部分神经元被激活。这有助于网络学习到数据的稀疏表示,提高模型的泛化能力。
本节 Quiz:
Which of the following activation functions is the most common choice for the hidden layers of a neural network?
× Most hidden layers do not use any activation function.
√ ReLU (rectified linear unit)
× Sigmoid
× LinearFor the task of predicting housing prices, which activation functions could you choose for the output layer? Choose the 2 options that apply.
√ Linear
√ ReLU
× SigmoidA neural network with many layers but no activation function (in the hidden layers) is not effective; that’s why we should instead use the linear activation function in every hidden layer.
√ False
× True
3. 多分类问题和Softmax函数
本节来进一步优化“编译compile()”的“损失函数loss”设置。在第一节中,由于“手写数字识别”已经被我们简化成只识别数字1和数字0,所以使用了“二元交叉熵损失函数loss=BinaryCrossentropy()”,那如果要识别全部的数字0~数字9,又该如何设置损失函数呢?下面就来介绍。
3.1 多分类问题
显然,要识别全部的数字0~数字9,就需要将二元分类问题进行推广。于是,分类输出的目标值有多个可能的问题,便称为“多分类问题(multiclass classfication problem)”。比如“手写数字识别”要分类10个数字、“肿瘤检测”要分类多种恶化类型、流水线产品检测不同类型的缺陷等。
注:聚类是无监督学习,神经网络自行分类;多分类问题是有监督学习,只不过是类别多了。

对于多分类问题,显然希望决策边界如上右图所示。于是下节介绍由二元分类的“逻辑回归算法”推广得到的“Softmax回归算法”,可以解决上述“多分类问题”,并将其应用到神经网络中。
3.2 逻辑回归的推广:Softmax回归
下面是Softmax函数的定义,也就是 g ( z ) g(z) g(z) 的定义:

- j j j 为单层神经网络内的神经元索引; k k k 也为神经元索引,但其主要目的是将本层内所有神经元求和。
- a j a_j aj:当前层第 j j j 个神经元的输出。
注1:尽管参数不完全一致,但 N = 2 N=2 N=2 时,“Softmax回归”会退化成“逻辑回归”。
注2:Softmax回归使用指数,不仅可以保证概率非负,同时也可以扩大不同值之间的差异。
注3:多分类问题所有可能输出的概率之和为1。
于是类似于“逻辑回归”的“二元交叉熵(Binary Crossen tropy)损失函数”,“Softmax回归”的损失函数为“稀疏分类交叉熵(Sparse Categorical Crossen tropy)”。同样也是,推理结果越接近真实结果,损失越小:

3.3 Softmax神经网络的代码实现
显然,要创建解决多分类问题的神经网络,只需要更改输出层激活函数为“Softmax函数”、损失函数为“稀疏分类交叉熵”即可,代码如下:

注意到,Softmax层,也被称为“Softmax激活函数”,和之前的激活函数都不同。因为Softmax函数的输出 a j a_j aj 不只取决于当前的输入 z j z_j zj,而是取决于所有的输入 z 1 , . . . , z N z_1,...,z_N z1,...,zN。所以Softmax层并不能逐个计算神经元的输出,而是需要“同时计算”该层所有神经元的输出。
虽然上述代码规定好了损失函数,但实际上并不采用上述代码。因为采用上面的代码,会要求TensorFlow保留损失函数计算的中间结果 a j , j = 1 , . . , N . a_j,j=1,..,N. aj,j=1,..,N.。但实际上,多计算一个变量就会引入更多的舍入误差,尤其是“Sigmoid函数 1 1 + e − z \frac{1}{1+e^{-z}} 1+e−z1”、“Softmax函数 e z j ∑ k = 1 N e z k \frac{e^{z_j}}{\sum_{k=1}^N e^{z_k}} ∑k=1Nezkezj”的计算结果中,其总会有些值非常小,进而使得计算精度不足导致 舍入误差。为了消除这部分的舍入误差,我们可以令TensorFlow不要再计算中间结果 z z z,而是直接将 z z z 的表达式代入到损失函数中。这样TensorFlow会先化简损失函数表达式(重排列),再进行计算,从而减少一步的舍入误差:


logits就是表示 z z z,from_logits=True表示直接使用 z z z 计算代价函数。- 尽管上述代码可能会使得代码含义没那么清楚,但是可以使TensorFlow的数值舍入误差减小。
3.4 多标签问题
最后,“多分类问题(multi-classfication problem)”和“多标签问题(multi-label problem)”非常容易混淆,本小节就是来区分一下这两个定义。“多标签分类”是一个输入,多个不同类型的分类。所以,“多标签问题”可以看成是多个“二元分类”的组合。比如下面的“多标签问题”就是由3个不同的“二元分类”组成的:

直观上,我们可能会想到针对不同的标签分类,创建各自独立的的神经网络,比如上图就创建三个独立的神经网络,但显然这看起来不聪明,所以实际上会创建一个神经网络同时解决这三个二元分类。创建网络时只要注意将最后的输出层调整为三个Sigmoid神经元即可。
下面来介绍更加高级的神经网络概念,包括比“梯度下降”更好的迭代算法。
本节 Quiz:
For a multiclass classification task that has 4 possible outputs, the sum of all the activations adds up to 1. For a multiclass classification task that has 3 possible outputs, the sum of all the activations should add up to …
× It willvary, depending on the input x.
× Less than 1.
× More than 1.
√ 1.For multiclass classification, the cross entropy loss is used for training the model. If there are 4 possible classes for the output, and for a particular training example, the true class of the example is class 3 (y=3), then what does the cross entropy loss simplify to? [Hint: This loss should get smaller when a 3 a_3 a3 gets larger.]
× − l o g ( a 1 ) − l o g ( a 2 ) − l o g ( a 3 ) − l o g ( a 4 ) 4 \frac{-log(a_1)-log(a_2)-log(a_3)-log(a_4)}{4} 4−log(a1)−log(a2)−log(a3)−log(a4)
√ − l o g ( a 3 ) -log(a_3) −log(a3)
× z 3 z 1 + z 2 + z 3 + z 4 \frac{z_3}{z_1 + z_2 + z_3 + z_4} z1+z2+z3+z4z3
× z 3 z_3 z3For multiclass classification, the recommended way to implement softmax regression is to set
from_logits=Truein the loss function, and also to define the model’s output layer with…
√ a “linear” activation
× a “softmax” activation
4. 更加高级的神经网络概念
4.1 梯度下降法的改进:Adam算法
“梯度下降”广泛应用于机器学习算法中,如线性回归、逻辑回归、神经网络早期实现等,但是还有其他性能更好的最下滑代价函数的算法。比如“Adam算法(Adaptive Moment estimation, 自适应矩估计)”就可以自动调整“梯度下降”学习率 α \alpha α 的大小,从而加快“梯度下降”的收敛速度。下面是其算法逻辑和代码示例:
- “Adam算法”并不只使用同一个学习率 α \alpha α,而是 针对每个参数都定义一个 α j \alpha_j αj。
- 如果参数一直向同一个方向前进,就逐步增大该参数的学习率;若每次方向都不一样(振荡),就逐步减小学习率。
- “Adam算法”还需要一个参数来控制每个参数的学习率的增大或减小的速度——全局学习率(下面设置为 1 0 − 3 10^{-3} 10−3)。

有兴趣可以试着调大全局学习率learning_rate,看看Adam算法能否学的更快。
4.2 其他类型的神经网络层
“心电图监测”问题:根据心电图(electrocardiogram, EKG/ECG)判断是否有心脏病。
- 输入特征:长度为100的心电图信号。
- 输出:有心脏病的概率。
目前为止学习到的所有神经网络都是“密集层类型(dense layer type)”,也就是层内的每一个神经元都会得到上一层的所有输入特征。虽然“密集层类型”的神经网络功能很强大,但是其计算量很大。于是,Yann LeCun 最早提出“卷积层(convolution layer)”,并将其应用到计算机视觉领域。“卷积层”中,每个神经元只关心输入图像的某个区域。如下左图中,对于输入图像,每个神经元只关心某个小区域(按照颜色对应)。“卷积层”的优点如下:
- 加快计算。
- 需要的训练集可以更小,并且也不容易“过拟合”。(Week3会更加详细的介绍“过拟合”)

如果神经网络有很多“卷积层”,就会称之为“卷积神经网络”(如上右图)。上右图便给出了“心电图监测”问题(本小节开始的说明)的卷积神经网络示意图。显然,改变每个神经元查看的窗口大小,每一个有多少神经元,有效的选择这些参数,可以构建比“密集层类型”更加有效的神经网络。
除了“卷积层”之外,当然还有其他的神经网络层类型,将不同类型的“层”结合在一起,组成更加强大的神经网络:
- 全连接层(Fully Connected Layer):全连接层是最简单的神经网络层,其中每个神经元与上一层的所有神经元相连接。
- 卷积层(Convolutional Layer):卷积层用于处理图像和其他二维数据,通过卷积操作提取图像的局部特征。
- 池化层(Pooling Layer):池化层通常与卷积层结合使用,用于减小特征图的空间尺寸,提高计算效率,并减少参数量。
- 循环神经网络层(Recurrent Neural Network Layer):RNN层用于处理序列数据,具有记忆性,能够捕捉时间上的依赖关系。
- 长短时记忆网络层(Long Short-Term Memory Layer,LSTM):LSTM是一种特殊的循环神经网络层,具有更强大的记忆性,适用于处理长序列依赖关系。
- ……
4.3 神经网络代码实例——手写数字识别


- 本节来自于“C2_W2_Assignment.ipynb”中的“Exercise 2”。
- 训练集来自:MNIST handwritten digit dataset (http://yann.lecun.com/exdb/mnist/),可以直接打开课程资料(本文开头说明),也可以使用百度网盘单独下载“2-2data.rar(6.18MB)”。
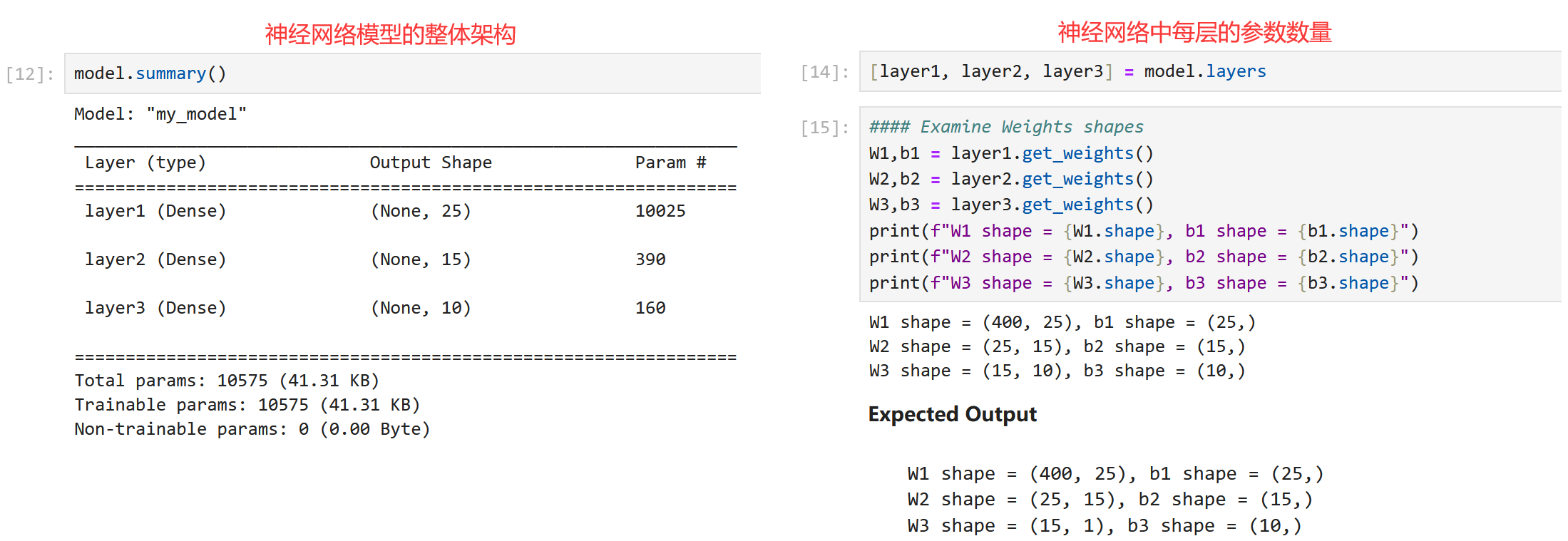
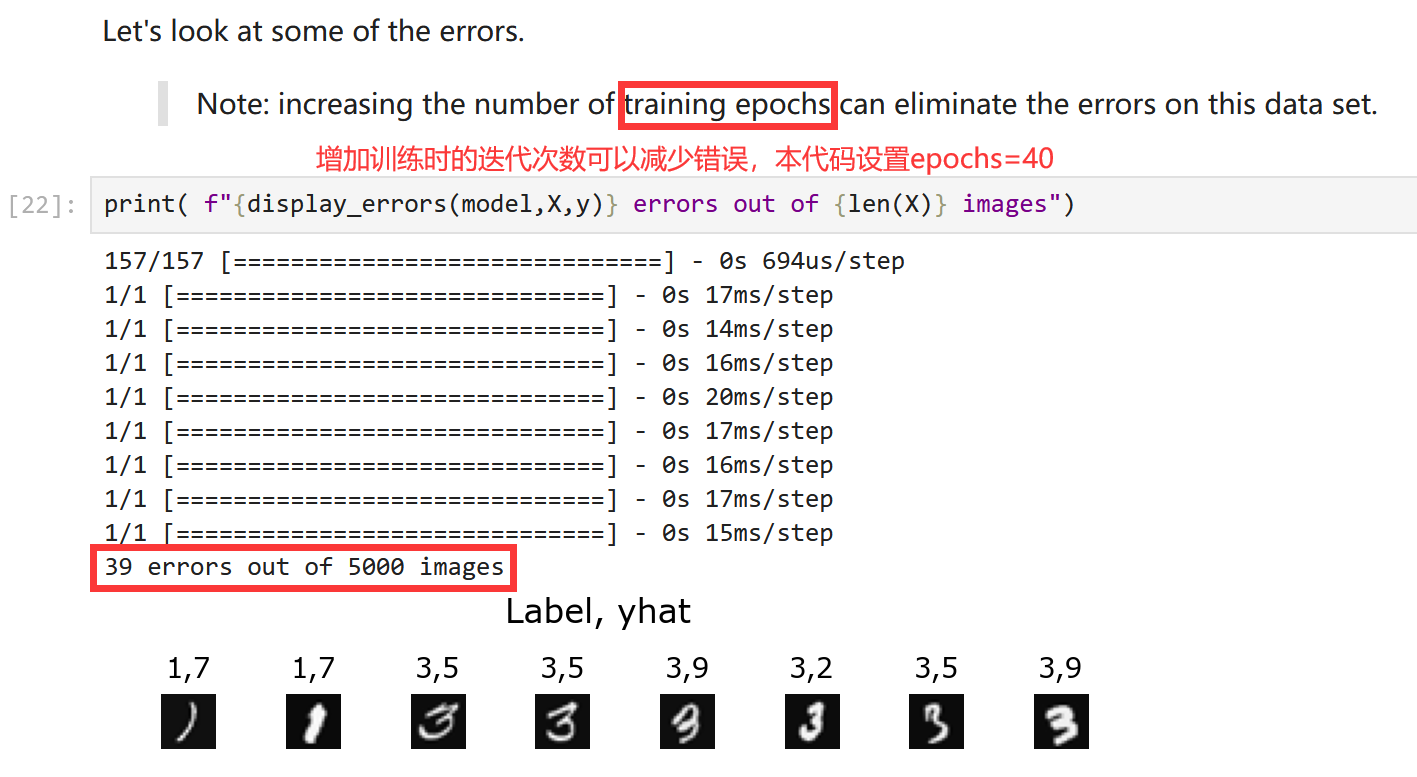
到本节为止,本周与代码有关的部分就介绍完了。现在根据本周实验,给出完整的“手写数字识别”代码,并在后面给出了神经网络参数及预测结果。代码的整体逻辑是,使用训练集进行训练;训练完毕后,再从训练集中挑出一些图片,看看训练后的神经网络能否正确预测。所以最后的“训练错误汇总”是因为迭代次数过少导致:
# 导入头文件
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.activations import linear, relu, sigmoid
import matplotlib.pyplot as plt
plt.style.use('./deeplearning.mplstyle')
import logging
logging.getLogger("tensorflow").setLevel(logging.ERROR)
tf.autograph.set_verbosity(0)# 加载训练集:5000张手写体图片,每张图片大小20x20
X = np.load("data/X.npy") # 5000x400
y = np.load("data/y.npy") # 5000x1# 定义神经网络
model = Sequential([tf.keras.Input(shape=(400,)), # 输入特征的长度Dense(units=25, activation='relu', name='layer1'),Dense(units=15, activation='relu', name='layer2'),Dense(units=10, activation='linear', name='layer3'),], name = "my_model"
)# 编译模型
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),optimizer=tf.keras.optimizers.Adam(learning_rate=0.001)
)# 训练模型
history = model.fit(X, y, epochs=40)# 预测结果
image_new = X[1015]
prediction = model.predict(image_new.reshape(1,400)) # prediction
yhat = np.argmax(prediction)
prediction_p = tf.nn.softmax(prediction)
print(f" Largest Prediction index: {yhat}")
print(f"The Probability of Largest index: {prediction_p[0,yhat]:0.2f}")

本节 Quiz:
The Adam optimizer is the recommended optimizer for finding the optimal parameters of the model. How do you use the Adam optimizer in TensorFlow?
× The Adam optimizer works only with Softmax outputs. So if a neural network has a Softmax output layer, TensorFlow will automatically pick the Adam optimizer.
× The call tomodel.compile()uses the Adam optimizer by default.
× The call tomodel.compile()will automatically pick the best optimizer, whether it is gradient descent, Adam or something else. So there’s no need to pick an optimizer manually.
√ When callingmodel.compile(), setoptimizer=tf.keras.optimizers.Adam(learning_rate=1e-3).The lecture covered a different layer type where each single neuron of the layer does not look at all the values of the input vector that is fed into that layer. What is this name of the layer type discussed in lecture?
× Image layer.
√ Convolutional layer.
× 1D layer or 2D layer (depending on the input dimension).
× A fully connected layer.
5. 反向传播(选修)
本节介绍TensorFlow如何使用“反向传播”,计算神经网络的代价函数对所有参数的偏导。
“反向传播”是“自动微分(auto-diff)算法”的一种。
5.1 计算图和导数
显然,由于神经网络可以创建的相当庞大,所以很难显式的写出偏导表达式。此时,我们求解代价函数偏导的思路就转成,求解代价函数在该点切线的斜率,也就是使用很小的步长来近似当前点的切线斜率。但是神经网络通常又有很多层,于是对于每个神经元的每个参数都通过这种方式,直接迭代一次神经网络求解对一个参数的偏导,显然也不现实。于是,我们先通过“计算图(Computation Graph)”来研究一下神经网络的计算流程,找找灵感,比如下面对于单神经元网络的代价函数计算:

J ( w , b ) = 1 2 ( ( w x + b ) − y ) 2 ∂ J ∂ w = ∂ d ∂ w ∂ J ∂ d = ∂ a ∂ w ∂ d ∂ a ∂ J ∂ d = ∂ c ∂ w ∂ a ∂ c ∂ d ∂ a ∂ J ∂ d \begin{aligned} J(w,b) &= \frac{1}{2}((wx+b)-y)^2\\ \frac{\partial J}{\partial w} &= \frac{\partial d}{\partial w} \frac{\partial J}{\partial d} = \frac{\partial a}{\partial w} \frac{\partial d}{\partial a} \frac{\partial J}{\partial d} = \frac{\partial c}{\partial w} \frac{\partial a}{\partial c} \frac{\partial d}{\partial a} \frac{\partial J}{\partial d} \end{aligned} J(w,b)∂w∂J=21((wx+b)−y)2=∂w∂d∂d∂J=∂w∂a∂a∂d∂d∂J=∂w∂c∂c∂a∂a∂d∂d∂J
也就是,将整体的计算过程拆成一步一步的,就组成了“计算图”。从左到右,求解当前点的代价函数大小很简单。但注意到,如果我们想要求解代价函数的表达式时,还可以根据上述“计算图”写出求导的“链式法则(chain rule)”!!而且“链式法则”的顺序正好是从右向左的!!由于越靠右的节点也会被更多的参数共用,于是反向传播一次,便可以把依次把路径上的每一个参数的偏导都求解出来。而不是针对每个参数,都额外增加一点,通过从左到右计算代价函数的变化率来求得相应参数的偏导。于是,若“计算图”总共有 N N N 个节点、 P P P 个输入参数,要计算所有函数偏导:
- 反向传播:只需大约 N + P N+P N+P 个步骤。
- 针对每个参数求切线斜率:大约 N × P N×P N×P 个步骤。
总结:在“计算图”中使用“链式法则”可以大大加快神经网络的训练速度!!
总结:反向传播就是从左到右计算代价函数,然后从右向左计算所有参数的偏导。
5.2 神经网络中的反向传播
本节就来将上一节的想法应用到大型神经网络中。显然可以如下图所示,先“前向传播”计算神经网络中所有神经元的取值,然后一次“反向传播”遍历走完所有节点,即可计算出神经网络的代价函数对每个神经元的每个参数的偏导。显然,此时“计算图”实际上就相当于神经网络:


覆盖优化 - 附代码)
)





)
)




)




