摘 要
微博已成为时下非常热门的社交媒体平台,是一个庞大的关于信息分享和话题交流的平台,在人们线上社交活动中发挥着不可替代的作用,由于网络信息鱼龙混杂,所以本文通过了解微博的热度机制进而研究微博热度和预测微博的热门程度,本文研究内容对于监控预测微博舆情有重要的借鉴意义。
本文主要以新浪微博作为研究对象,首先进行爬取工具的选取,随后通过分析信息传播特征,从微博的用户、内容与传播三个方面提炼影响微博热度的主要因素,并提取关键指标建立热度体系评价指标,运用因子分析法建立微博热度评估模型,得到各微博信息维度表达式以及热度计算公式,对数据进行整理分析,最终对其结果进行排序和对比,发现模型比较符合实际情况,表明本模型具有较高的准确性。
随后又提出了基于 PSO优化 BP 神经网络的话题热门程度预测模型。构建出话题热门程度的时间序列模型作为预测模型的输入,依照优化后的预测模型,完成了对话题热门程度值的预测。实验结果表明基于 PSO 优化 BP 神经网络的话题热门程度预测模型能够很好的模拟话题热门程度的变化趋势,对现实具有一定的指导意义。
关键词:微博;因子分析;热度评价模型;BP神经网络预测模型
Abstract
Weibo has become a very popular social media platform, today is a big topic about information sharing and exchange platform, in people online play an irreplaceable role in social activities, the good and evil people mixed up because of the network information, so this article through understanding the heat mechanism and further study of weibo microblogging heat and predict microblogging popularity, this article research content for monitoring the microblogging public opinion has important significance.
Based on sina weibo, this article crawl tools selection at first, then through analyzing the characteristic of information dissemination and spread from weibo users, content and three aspects of refining the main factors affecting heat weibo, and extract the key indicators to establish the heat system of evaluation index, heat weibo evaluation model is established by using factor analysis method, get the microblog information dimension expression and heat calculation formula of sorts through the data analysis, sorting, and finally the results, found model more in line with the actual situation, show that the model has higher accuracy.
Then, a pso-based BP neural network optimization model is proposed to predict the degree of hot topics. The time series model of topic popularity is constructed as the input of the prediction model. According to the optimized prediction model, the prediction of topic popularity is completed. The experimental results show that the PSO optimized BP neural network model can well simulate the change trend of the hot topic degree, which has certain guiding significance to the reality.
Keywords:weibo;factor analysis;heat evaluation model;BP neural network;prediction model
目 录
摘 要 I
Abstract 1
第1章 绪 论 1
1.1 选题背景及意义 1
1.1.1 选题背景 1
1.1.2 研究意义 1
1.2 国内外研究现状 2
1.2.1 热度评价研究现状 2
1.2.2热门话题预测现状分析 3
1.3 研究内容 3
1.4 组织结构 4
第2章 预备知识 5
2.1爬取工具的选取 5
2.2 热度评价研究 5
2.2.1媒体与用户关注度 5
2.2.2媒体影响力 6
2.2.3 内容的丰富程度 6
2.2.4话题的时效性 7
2.3 热门预测算法 7
2.3.1预测依据 7
2.3.2 基于PSO算法的BP神经网络 7
2.4 本章小结 8
第3章 热度评价模型的建立 9
3.1微博登录与信息爬取 9
3.2建立热度评价模型 10
3.3通过热度排序对模型进行检验 15
3.4本章小结 16
第4章 预测模型的建立 17
4.1 热门微博判断指标 17
4.2 结合PSO算法的BP 神经网络的热门预测模型 18
4.2.1 算法原理 18
4.2.2 模型的实验环境与数据获取 19
4.2.3 预测模型的参数设置 19
4.2.4 预测结果与分析 20
4.3 本章小结 22
结 论 23
参考文献 24
第1章 绪 论
1.1 选题背景及意义
1.1.1 选题背景
微博,简称微型博客,2009 年由新浪客户端开始发行使用,它主要是基于关注机制,通过广播式的信息扩散向大众发表实时信息。2018年12月31日,微博官方公布2018年第四季度财务审计报告,报告说明,在激烈的行业竞争中,微博用户数仍然持续飞涨,用户活跃度进一步提升。2018年微博客户端线上活跃用户大约增加了7000万左右,12月总用户已经达到4.62亿,平均每日活跃用户突破2亿。显而易见,微博已成为时下非常热门的社交媒体平台,是一个庞大的关于信息分享和话题交流的平台,用户可以通过注册登录,完善更新个人信息,在这个平台中用户可以参与热门话题的讨论,了解时下发生的事件,还可以即时分享自己的所做所想,其中推送次数多,浏览次数高,互动次数多的微博会被推送为热门微博,且微博更注重信息的时效性、言论自由性以及传播广泛性,所有用户可以第一时间了解并参与到时事讨论中去,所以微博在舆情预警以及政务与社会信息传播方面的影响力日益增大。
在微博平台中,任何用户都可以自由发布内容,还可以对其他用户发送的内容发表自己的评论并转发,另外由于近些年视频信息传播愈发火热,图像处理技术也变得更加成熟,传播信息鱼龙混杂,可靠程度有待考量,于是了解微博的热度机制并对微博热度进行评估与预测,对于监控预测微博舆情,推动传播真实有效信息,营造活跃健康的社交平台具有重要作用。
1.1.2 研究意义
在微博信息热度评估中,曝光度高、阅读数量或者互动数较高的内容信息比较容易成为热门微博,平台中包括“热搜排行榜”和“热门话题”等对每位用户进行推送,还会根据热度大小对热门微博的内容进行排序。本文在分析了影响热门微博传播的一些因素之后,拟建立热度评价模型与热门微博预测模型,通过计算热门微博的热度与热门程度的变化趋势,来对话题热度的监控与预测,从而可以更加有效的缩小平台的负面信息与虚假信息的传播范围,使大众浏览到更多真实可靠的时政信息。
本文结合微博信息内容和用户行为,主要运用因子分析法建立微博热度评估模型,对微博热度进行量化处理,随后利用 BP 神经网络学习建立了热门微博预测模型,来判断微博内容能否成为热点微博,并判断热门程度的变化趋势。本文研究在促进真实的时政信息传播,研究平台商品营销推送以及推动政府对舆情监测与预警等方面,提供了可以借鉴的理论与实践依据。
1.2 国内外研究现状
1.2.1 热度评价研究现状
关于网络信息的热度评估研究,Xi Maoetal利用图形化法模拟新闻来源,寻找确定了热门话题与新闻内容之间的相应联系,并考虑的新闻的时效性,利用衰退函数进行多次迭代,对于不同的新闻类型,设置不同的速率参数,最终得出内容热度的计算公式[1]。不少学者曾经基于微博传播主体角度展开热度研究,包括对微博运营策略以及用户之间的联系等方面进行探讨[2]。关于微博内容热度的研究,Teutle和Golder分别对微博的关注机制以及用户之间的扩散式联系做了分析,发现微博热度与用户间的互动程度和内容推送对象有关[3-4]。郑斐然等人研究得到了一种可以在万千微博主题信息中提炼新闻主题内容的方法,主要原理是通过提取内容中与新闻有关的关键字,结合词组出现的频率,对内容进行聚类分析,从而挖掘指定话题[5-6]。张鲁民等人提出了对突发事件实现舆情监控的一种方法,通过建立情感符号模型,通过初始聚类扩散群集算法对事件进行检测与监控[7]。Phuvipadawat 等人基于微博的内容性质,创造了在推特中的突发事件监测、内容合并及信息跟踪等算法[8]。Weng等人提出 Twitter Rank算法,原理是基于博主的粉丝数量与发博率对目标用户进行影响力分析,在此基础上挖取了推特平台上与热门内容有关的若干用户[9]。Pal 等人在给定数据的基础上,综合考虑了微博的转发数、点赞数、评论数、被提及数等衡量内容的热度[10]。
衡量微博热度,研究重心应该放在微博内容与用户行为两个方面,其中用户不仅指发布者,还指该用户所面向的粉丝群体。尽管平台会根据内部的排序机制对所有微博按大小进行排序,包括首页热搜以及指定话题搜索排名等,但缺点是其并不知道其排序时热度的计算原理以及热度差距产生的原因,基于此,本文运用因子分析法建立了微博热度评估模型,得出热度的计算公式,将热度进行量化,并得出了新的排序结果与原排序进行对比。
1.2.2热门话题预测现状分析
对于各类热门话题的预测,学术界一般主要采取以下两种预测方法,第一种是指比较典型的线性预测方法,但仅仅适合对平稳曲线进行预测,不适合预测多种类型的热门话题。第二种是指基于非线性理论建立预测模型,该种分析方法更具系统性与智能性,如支持向量机,可以对数据进行广义线性分类,大致实现非线性拟合,不足之处是会经常陷入局部最优,无法得到全局最优解[11-12]。Suh等人选取了话题类型、粉丝人数等属性,基于主成分分析法提炼了影响用户互动行为的主要因素,并建立了精确度较高的因子图模型,对用户行为进行了合理预测[13-14]。刘功申等人通过定量计算用户对微博的影响,对已有算法进行优化,可以凭借微博发出者的用户属性预测该微博是否会被大量转发,进而给出舆情预警[15]。张敬基于话题热度,提出微博热度预测算法,结合多维度数据建立回归预测模型,实现对话题热度的预测[17]。F.D.Sahneh,C.Scoglio根据传染模型的多层网络传播原理建立预测模型,预测话题的未来走向,并详细地阐述了信息扩散时的传播规律以及信息的相互作用。因为BP神经网络在面对比较错综复杂的问题上,收敛速度慢,处理时间长,而且很容易收敛到局部最优值,不能达到全局最优[18]。
对于上述问题,许多研究者提出了相关改进方法。颜文俊等基于遗传算法优化 BP 神经网络的预测模型,利用光伏输出等原理,提高了算法的收敛速度,进而提高了预测的效率与精度,但并未改进结果局部最优这一缺陷[19]。
丁硕与巫庆辉通过对比多种经典的优化算法的渐近函数,分析各改进算法对不同数据规模的分析效果,发现每种算法都有适用范围,在各自适用范围内逼近效果接近良好。周爱武等通过利用最优样本集相关原理,改进了原始算法,缩短了算法的运行时间,迭代次数也大大降低,但算法自身仍然有局限性[20]。
1.3 研究内容
研究基于微博客户端,运用爬虫软件python中的Selenium 爬取工具,采集5个话题热门微博的相关数据,就内容、用户、传播三个角度运用因子分析法建立微博热度评估模型,并验证模型准确性。随后利用 BP 神经网络研究基于PSO算法的热门微博预测算法,最后通过实例验证热点话题预测结果的可靠性。
1.4 组织结构
本文共包括四章,下面介绍每章的主要内容:
第一章 绪论 本章简要从微博热度评价与热门程度预测的选题背景、研究意义进行了简要阐述,对话题热度评价与预测的国内外研究现状以及课题研究内容与流程进行了概括。
第二章 预备知识 本部分阐述了研究开始前需要了解的预备知识,包括爬取工具的选取,热度评价与热门预测等方面的理论知识,奠定了全文的理论基础。
第三章 热度评价模型的建立,本章基于爬取的热门微博数据,运用因子分析法提取重要因素建立热度体系评级指标,就内容、用户、传播三个角度运用因子分析法建立微博热度评估模型,基于该模型对内容热度进行排序对比,实行热度评估模型的验证。
第四章 本章建立了结合PSO算法,基于BP神经网络的热门微博预测模型,首先分析热门话题的表现形式,运用算法原理,将进行预测的微博信息作为模型的输入,来完成对微博热门程度与趋势的预测,最终进行了实际检验。
第2章 预备知识
在进行实际操作之前,首先对涉及到的基础理论知识进行简单介绍。
2.1爬取工具的选取
微博相较于其他网站,涉及功能比较齐全,所以对微博页面内容进行爬取并非易事,除此之外其反爬虫技术更为先进,一半的爬虫工具无法快速获取到目标信息,但总的来说其数据格式比较统一,综上我们基于微博网站的运行机制,借助python中的技术与手段,可以快捷地爬取到微博中的指定内容及相关数据。
网络爬虫原理是基于爬虫语句对目标网站的信息进行获取,而近年来反爬虫技术发展迅速,由此获取网站信息也变得没那么容易。。在爬取数据时往往会遇到各种各样的拦截,比如常见的“403 Forbidden"错误,它表示服务器已经识别出爬虫并拒绝处理用户的请求。而Selenium Python API技术,是以一种非常直观的方式来访问浏览器的技术,包括定位元素、自动操作键盘鼠标提交页面表单、抓取所需信息。Selenium的爬虫原理是先识别所需爬取内容的HTML源码,通过其所提供的方法定位到所需信息的结点位置,并获取其文本内容。本文利用python中的pip工具来安装selenium和对应的浏览器驱动,以便进行后续的数据爬取。
2.2 热度评价研究
分析微博热门话题热度之前,需要了解影响热度的若干因素,如下:
2.2.1媒体与用户关注度
这里的媒体包括新闻媒体、娱乐媒体等,是首发信息的来源媒体,诸如央视新闻、新浪媒体等。某个话题报道信息的数量是影响媒体关注度的关键因素,发布该话题信息的数目越多,可以反映各大媒体对话题的关注度越高,于是会引起更多媒体的重视,在传播范围变广之后,大众的阅读量也会明显增多,话题成为热门话题的几率就大大增加。网络时代之前,人们基本通过报纸、期刊杂志、电视或收音机等方式了解当下热门时事,获取时政信息。而网络时代的到来,传统媒体为了避免淘汰,进入了新媒体时代,转型建立了自己的互联网平台,在新媒体时代,热门信息的报道并非全是首发,很大程度上是参考并转发了其余的媒体时事报道。所以,某话题的报道频率越高,各媒体的转发频率越高,就越能说明媒体的关注程度,就越可能成为热门。
用户关注度也是衡量话题热度的关键因素。用户关注度中的用户,是指各类时事报道的阅读者。一条微博信息包括了用户阅读量,转发数,评论数等数据,可以反映用户对该信息或者该话题的关注程度,还可以间接反映话题在用户中的影响范围与程度。
某位用户在浏览某条信息之后,若觉得有趣或者有所想,还可能会被转载到微信和Facebook等其他社交平台上,该信息又会在其他网络平台上传播。除此之外,传播时事信息不仅可以通过线上传播,还可以通过生活中的人际关系进行扩散。例如,用户A在网站W1中阅读了一篇报道,认为非常新奇有趣,分享或讲述给朋友B,而B可能又会将该条信息讲述给她其他朋友。上述是指话题的二次传播,通过这种非线性的网络式传播,某个话题可以被大众知晓,知晓的人数越多,点击量也会越来越大,话题会有比较大的几率评为热门话题。用户的评论与转发从侧面可以反映出大众对某话题的兴趣程度,有利于社交平台预测其进行多次传播的几率,进而衡量话题热度。
2.2.2媒体影响力
媒体影响力是决定微博热度的第二个要素,一般来说,自媒体指每个独立且普遍的信息传播者,他们以各种类型的线上方式,向粉丝用户推送时下信息或推广商品的信息。同一事件相关的微博内容会有很多自媒体平台进行转发评论,但是不同的自媒体其传播范围与影响力都不尽相同。一般来说,微博信息的传播呈树状传递,一些加v用户的微博发出后通过粉丝的阅读和互动不断扩大影响力,而且粉丝数量越多,传播范围就会越广,阅读量与互动数也会越高,会比较容易成为热点话题。
一般来说,媒体是指通过现代和电子手段向大多数人或特定的个人传递规范性和非规范性信息的私人、公共、普遍和独立的传播者。同一事件相关的微博内容会在不同的自媒体用户之间复制传播,但不同个体媒体的传播能力和影响程度不同。
2.2.3 内容的丰富程度
在微博平台上,用户发布信息几乎没有限制,很多用户发布的内容比较随意,有的是对日常生活的记录,有的是倾诉悲喜遭遇,有的是对时事的思考评论。根据互联网上的随机调查报告显示,42.52%的“加V用户”会发布新锐观点、时事评论等,37.47%会在微博上分享日常,13.69%的“加V用户”会经常发布一些专业领域的知识,而仅仅只是转发不加以任何评论的用户较少,只有7.69%,并且越是可以表达自己思想的微博用户,越会引起人们的评论转发与关注。
2.2.4话题的时效性
话题的热度衡量依据是各类媒体报道数量与用户关注程度,若某话题被评为热门话题,该话题下必定有许多关于该话题的内容信息。一般情况下,热门话题里面所讨论的事件都是最近的或者时下发生的事件,用户或者表达自己的立场或者发表自己的见解。因此最新发布的新信息的热度比之前发布的信息的热度要高,随着描述的事件慢慢过时,人们对事件的讨论的热度会逐渐下降。
热点话题是收集大量已发表的信息,热点话题是收集的每一篇新闻报道的热点之和。一般来说,热门话题下的用户描述当前事件并报告最近的事件
2.3 热门预测算法
2.3.1预测依据
新浪微博近年来已经成为被人们广泛使用的社交媒体平台,话题经过形成与不断传播,最终可成为热门话题。对于平台上的每一条微博信息都包括以下七个部分:用户ID、发送时间、内容(包括图片与视频)、评论数、转发数和点赞数以及阅读量。微博,粉丝与发布者的互动行为(包括主观性评论、转发与点赞)都可以反映用户对该话题的兴趣程度。这些互动行为对预测微博传播趋势有重要意义,它可以衡量某条微博的热门程度。因此,新浪微博为了提高用户的阅读效率,使用户快速获取到热门信息,按照一定标准对所有热门微博按规律进行排序,该标准是综合考虑微博的所有内容信息得到的,包括热搜榜与热门话题等,根据其是否在排行榜或热搜话题内,所有微博可以分为非热门微博与热门微博。
显而易见,要判断某条微博是否热门,就要分析微博的所有信息特征,所以可以依据信息增益原理,按照微博所有信息特征衡量其热门程度,预测微博能否成为热门,或者判断热门微博的变化趋势。
2.3.2 基于PSO算法的BP神经网络
上世纪八十年代, McCelland与Rumelhart提出BP神经网络这一概念,该算法拥有非线性映射能力等优势,只要在输入层输入信号,经过隐含层处理,由输出节点产出输出信号,若输出信号并未达到预期期望,就会通过转入误差,调整权值,将误差分摊给每个隐含单元,及时进行参数修正重新计算结果,直到得到期望的输出结果。BP神经网络可以求解复杂非线性函数的全局最优值,算法本身采用局部搜索优化策略,缺点是算法容易陷入局部最优。而粒子群优化算法(简称PSO)具有良好的局部开采能力,通过改变粒子学习模式,提高迭代速度,快速更新粒子的位置,从而确立可使全局最优的粒子,且操作简单,收敛速度快,获取结果效果与精度俱佳。可以将BP神经网络嵌入到PSO算法中去,提升局部搜索能力,实现与BP神经算法的优势互补,最终完成BP神经网络预测模型的构建。
2.4 本章小结
本文首先对全文涉及到的基础理论知识进行了简单介绍。对于爬取工具的选取,本文选择运用Selenium Python API技术爬取热门微博,还分析了影响话题热门程度的一些因素,对预测方法的依据与实现方法也做了基本阐述。
第3章 热度评价模型的建立
3.1微博登录与信息爬取
通过使用pathon中的Selenium 自动化工具,在 Firefox 浏览器通过定位审查元素,通过无头模式找到用户名,密码的HTML源码,调用selenium来定位按钮节点,最后进行登录。
核心代码为:>>> # coding= utf - 8
from selenium import webdriver
……
elem_sub =driver.find_element_by_xpath(“//input[@class=‘W_btn_a btn_34px’]”)
elem_sub.click()
print u’登录成功’
登录微博后,访问微博搜索页面,通过下面核心代码来搜索指定热门微博内容,本研究主要搜索包括新闻、体育、娱乐、情感、学习五种热门话题,每个话题爬取2条热门微博的相关信息。
核心代码为:>>>def Searchweibo (topic):
driver. get( “http://s. weibo. com/”)
……
elem_ topic. send_ keys( Keys. RETURN)
……
print u’ 爬取结束\n’
找到热门微博之后要进行信息爬取,数据爬取之前首先要确定所要获取的信息,包括用户名、内容、发布时间、转发量、评论数和点赞数,都可以用来分析微博的热门情况以及用户画像等。根据查阅相关文献,只需使用正则表达式和字符串操作就可以获取到所需字段内容,核心代码如下:
info=driver. find_ elements_by_xpath(‘’//div[@ class =‘WB_cardwrap S_bg2 clearfix’]”)
……
content = value. Text
图3-1 爬取结果
由爬取结果图3-1,我们可以直接获得新闻类热门话题第一条的发布内容、发布时间,转发量、评论数、点赞数等数据信息。
3.2建立热度评价模型
本文基于抓取的五种类型热门微博的数据,从用户、内容与传播三个角度,提炼了建立热度评价模型的7个参考指标,根据原始数据进行相关性分析,建立基于因子分析法的热度评价模型,得出热度值的计算公式,并对计算结果进行整理分析,对各类热门微博结果按热度值大小进行排序和对比,分析模型的准确性。
表3-1 微博热度评价模型参考指标
微博热度评价体系
热度影响因素 考量因素 指标含义
内容热度影响力
图片充实度 微博图片数量
字数充实度 微博文字数量与100相比
发布时长 从发出到记录数据之间的时间间隔
发布者热度影响力 粉丝数量 记录数据时的粉丝数量
互动数 近30天发布的内容产生互动行为数据统计指标
发博率 发博数量和活跃天数的比值
传播热度影响力 转发数 某条微博的转发数量
评论数 某条微博的评论数量
点赞数 某条微博的点赞数量
由表3-1,本文首先围绕内容热度影响力、发布者热度影响力、传播热度影响力三个维度结合爬取微博的原始数据信息,提出了包括阅读量、转发数、点赞数、评论数、博主粉丝数、发博次数、发布时长、文字与图片数量等参考因素。
考虑到转发数、评论数、点赞数这三个原始数据数值较大,不利于数据的处理与分析,本文拟通过互动数与重度传播率来反映微博传播热度,互动数综合考察了点赞数、被转发数、被评论数和博文曝光数等信息,可以直接反映发博带来的网友互动与传播情况,此外重度传播率主要结合转发评论数与阅读量,其数值含义为转发并评论数/阅读量,可以有效地考量传播热度。
由此,我们确立了七个因子指标,针对内容热度,选取的参考指标为文字充实度、图片充实度以及传播时长;针对发布者热度,选取的参考指标为粉丝数与发博率;针对传播热度,选取的参考指标为重度传播率与互动数。
下面进行数据预处理,根据获得相对应的各个微博因子数据,初步建立微博热度评价体系。从2019年4月21日在新浪微博平台用python分别爬取了关于新闻、体育、学习、情感、娱乐五个热门话题的前五条微博,并将参考指标进行处理加工,由此初步形成了比较完善的微博热度体系的的评级体系,如下3-2为七个因子指标的记录与处理结果:
表3-2 五种话题类型的热门微博指标数据
话题类型 热门微博 粉丝数(万) 传播时长(h) 文字充实度 图片充实度 发博率 重度传播率 互动数(万)
新闻 1 8396 2.5 1.12 4 52.5 0.07 53.73
新闻 2 6433 2.1 0.78 9 44.8 0.08 41.06
新闻 3 4554 2.3 0.96 3 38.5 0.07 26.29
新闻 4 5212 1.9 0.72 1 34.8 0.06 12.80
新闻 5 3615 1.9 0.81 2 32.6 0.05 10.05
体育 1 2064 9.6 1.04 9 64.2. 0.04 11.94
体育 2 2025 8.4 0.98 9 54.2 0.03 8.46
体育 3 1036 7.2 1.23 3 44.3 0.04 6.74
体育 4 546 7.8 0.72 2 32.2 0.02 6.19
体育 5 315 5.2 0.89 1 21.7 0.02 5.39
学习 1 1690 20.5 0.38 9 24.1 0.01 13.22
学习 2 176 13.8 0.49 9 26.8 0.02 11.54
续表3-2 五种话题类型的热门微博指标数据
话题类型 热门微博 粉丝数(万) 传播时长(h) 文字充实度 图片充实度 发博率 重度传播率 互动数(万)
学习 3 146 14.8 0.51 9 20.5 0.01 9.23
学习 4 142 8.9 0.14 9 14.6 0.00 10.48
学习 5 46 6.7 0.24 9 12.9 0.00 7.24
情感 1 2916 18.2 0.63 3 25.3 0.04 26.93
情感 2 1145 19.7 0.28 1 25.6 0.02 24.72
情感 3 666 13.8 1.24 3 18.3 0.03 18.84
情感 4 226 12.4 1.08 2 17.6 0.01 20.27
情感 5 124 15.4 0.44 1 21.7 0.01 14.62
娱乐 1 2668 8.2 0.8 1 42.4 0.07 46.39
娱乐 2 732 7.3 0.35 4 38.6 0.05 37.21
娱乐 3 574 7.5 0.48 2 32.5 0.03 36.42
娱乐 4 396 5.2 0.64 9 34.1 0.03 24.73
娱乐 5 217 4.3 0.96 9 28.5 0.02 17.55
由表3-2,我们计算得到了了25条热门微博七个因子指标的具体数据,对五种话题类型的五条热门微博按照出现的次序进行计算,基于以上七个指标的详细数据,开始进行因子分析。
进行因子分析之前首先要确定变量间的相关性,因此需要先进行KMO 与Bartlett的检验。其中KMO检验统计量是通过比较变量间简单相关系数和偏相关系数来反映变量间的相关性,其取值越接近1越说明变量相关性较强。当KMO>0.9时说明表示非常适合进行因子分析,0.7<KMO<0.9则说明比较适合进行因子分析,KMO<0.6则说明相关性较弱,因子分析法失效。
Bartlett球状检验原理为判断相关阵中变量的独立性,若变量相互独立,就无法在变量中提取公因子,也就无法利用因子分析法建立模型。其数值越大,且伴随概率<0.01时,就说明数据集适合使用因子分析法建立模型。
首先在SPSS软件中选择分析工具栏中的降维选项进行KMO 与Bartlett的检验,检验结果如表3-3
表3-3 KMO 和巴特利特检验
KMO 取样适切性量数 0.824
巴特利特球形度检验 近似卡方 532.972
自由度 21
显著性 0.003
由SPSS检验结果得到KMO值为0.824,Bartlett检验统计量的观测值为532.974,显示p值<0.05,说明各变量间具有相关性,可以说明因子分析适合用于建立模型。下表3-4为方差解释结果,图3-2为碎石图:
表3-4 方差解释结果
成分 初始特征值 提取载荷平方和
总计 方差百分比 累积 % 总计 方差百分比 累积 %
1 3.654 52.203 52.203 3.654 52.203 52.203
2 1.616 23.079 75.282 1.616 23.079 75.282
3 .791 11.304 86.586 .791 11.304 86.586
4 .480 6.852 93.438
5 .312 4.455 97.893
6 .094 1.345 99.238
7 .053 .762 100.000
提取方法:主成分分析法。
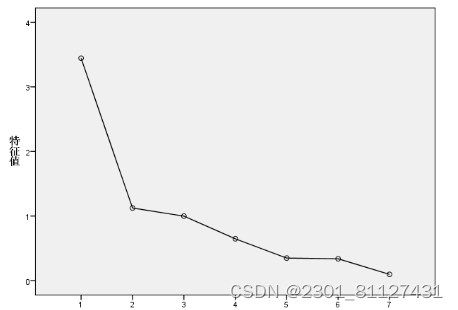
图3-2 碎石图
本文按照累计方差百分比不少于80%和特征值不少于1为标准,提取了3个公因子,由表3-4可以得到3个公因子可以累计解释信息的86.586%,各因子分别解释信息的52.203%,23.079%和11.304%。根据碎石图,前面三个因子特征值均不小于1,所以提取了三个因子,即微博信息维度F1、F2、F3,分别代表微博内容信息,微博博主信息,微博传播信息。
我们已经得到三个维度的权重,再根据各个维度的数据,就可以通过以下公式计算热度:
(3-1)
如公式(3-1),I表示提取因子的数量, 代表第 i 个因子其相关数据,则代表第i 个因子所占的权重。
为计算热度指数,我们需要根据成分得分矩阵分析每一公因子的成分构成。下表3-5为成分得分系数矩阵结果
表3-5 成分得分系数矩阵
成分 1 2 3
粉丝数(万) .257 .046 -.100
互动数(万) .164 -.392 .166
发博率 .087 .443 .738
文字充实度 .195 .280 .110
图片充实度 -.232 .223 .038
传播时长(h) -.138 -.343 .807
重度传播率 .250 -.146 .134
提取方法:主成分分析法。
表3-5中通过比较每行的相关系数,可以直观看出公因子与哪些指标的相关性较高。表中展示了7个指标的成分系数得分,分别代表三个微博信息维度、、。本文中代表第一微博信息维度,指代博主信息,包括粉丝数量、互动数量、发博率;代表第二微博信息维度,指代微博内容信息,包括文字与图片充实度; 代表第三微博信息维度,用于指代微博传播信息,包括传播时长、重度传播率等。于是我们得到各微博信息维度的计算公式:
第一微博信息维度:
(3-2)
第二微博信息维度:
(3-3)
第三微博信息维度:
(3-4)
最后根据三个公因子的方差贡献率和各个公因子指标体系维度的表达式,根据公式(3-1),得到微博热度的计算公式(3-5):
(3-5)
3.3通过热度排序对模型进行检验
由上式(3-5)可以得到每条热门微博的综合热度结果,此外本文根据热度大小对五种类型热门话题的5条微博进行了重新排名,如下表3-6。
表3-6 热门微博热度计算结果与重新排名
话题类型 热度初始排名 新排名 F1 F2 F3 F
新闻 1 1 4321.32 29.72 -0.28 1256.78
新闻 2 3 3654.07 30.53 -0.26 1130.56
新闻 3 2 3261.54 31.47 -0.52 1148.12
新闻 4 4 2407.71 32.24 -0.34 1081.36
新闻 5 5 2864.82 34.35 -0.17 930.25
体育 1 1 2181.38 25.85 -0.69 706.89
体育 2 2 1774.56 26.74 -1.01 657.15
体育 3 3 1861.38 15.96 -1.33 604.74
体育 4 5 1447.44 24.41 -1.05 521.71
体育 5 4 1328.67 28.52 -1.24 538.94
学习 1 1 1291.25 38.63 -0.57 273.85
学习 2 2 1147.62 37.12 -0.61 246.36
学习 3 3 1233.44 38.45 -0.42 241.47
学习 4 4 1225.51 35.56 -0.58 196.26
学习 5 5 905.89 23.78 -0.65 183.84
情感 1 1 2071.89 22.15 -0.43 736.93
情感 2 2 1671.45 21.59 -0.59 646.77
情感 3 4 1215.32 21.75 -0.66 471.23
情感 4 3 971.71 17.53 -0.24 496.75
情感 5 5 815.28 21.97 -0.38 351.88
娱乐 1 1 3770.06 28.64 -0.72 1075.56
娱乐 2 2 2966.65 23.31 -0.56 864.19
娱乐 3 3 2770.32 33.17 -0.65 775.22
娱乐 4 4 1466.47 37.28 -0.47 624.57
娱乐 5 5 1770.59 25.39 -0.53 563.95
从表3-6得出本文基于新浪微博热门按顺序截取的五类热门话题,又经过热度计算得出了五类话题热门微博的真实热度排序,经过对比,发现与截取的微博热度排序大致相同。从信息维度来看,新闻类与娱乐类微博第一信息维度F值较大,即博主影响力较大,导致计算得出的热度值较高,与实际情况也是相符的。新闻类、学习类、娱乐类第二信息维度F值较大,说明这几类热门微博内容表示都比较充实。总体热度值比较结果为,新闻类>娱乐类>体育类>情感类>学习类,与实际情况基本相符,由此可以看出建立的模型可以比较准确的反映微博真实热度问题。
3.4本章小结
本章基于爬取的热门微博数据,通过分析信息传播特征,提炼影响微博热度的主要因素,并提取重要因素建立热度体系评级指标,运用因子分析法提取重要因素建立热度体系评级指标,就内容、用户、传播三个角度运用因子分析法建立微博热度评估模型,得到各微博信息维度表达式以及热度计算公式,对数据进行整理分析,最终对其结果进行排序和对比,发现模型比较符合实际情况,表明本模型具有较高的准确性。
第4章 预测模型的建立
4.1 热门微博判断指标
形成热门话题需要用户对此类事件进行大量转发与评论,且内容观点需要集中。由此可以根据微博的内容和博主特征对微博的传播特征来预测转发数,评论数,以及点赞数,进而判别其能否成为热门微博。
由于微博内容和博主特征的复杂性,以及对于微博传播影响的非线性和不确定性, BP 神经网络算法拥有非线性映射能力等优势,只要在输入层输入信号,经过隐含层处理,就可以在输出节点产出输出信号,应用范围十分广泛。其拓扑结构包括输入层、隐层和输出层,本文拟采用典型的三层 BP 网络结构,如图4-1。
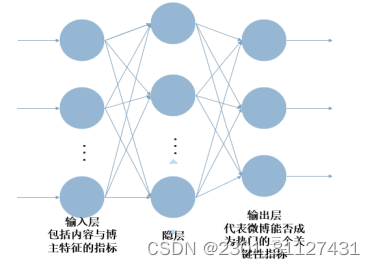
图4-1 进行预测的拓扑结构
对于微博的点赞行为,其可以反映用户对话题的关注程度和对内容的认可程度,而转发行为可以说明此条微博的传播范围,评论行为则可以反映用户对话题的参与度,这些用户行为都可以说明此条微博的热门程度。因此,本文选取热门微博的平均讨论数量、平均转发量、平均评论数、平均点赞数来衡量微博热门程度。各指标通过以下公式进行计算:
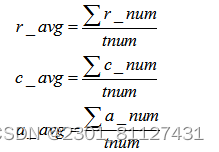
(4-1)
其中分别为转发量,评论数,点赞数,由选取的各项指标综合构建出反映内容热度的度量公式,公式如下:
(4-2)
根据式(4-2)我们得到了内容热门的度量值,随后将该度量值根据时间先后存储在时间序列中,代表在第i 个时间间隔内的热门度量值,序列 中的,与前个观测值的关系诶非线性映射,如公式(4-3):
(4-3)
4.2 结合PSO算法的BP 神经网络的热门预测模型
BP 神经网络算法目的是求解全局最优值,但BP神经网络算法是在局部进行优化策略的调整,其缺点是算法容易陷入局部最优。而PSO算法具有良好的局部开采能力,通过改变粒子学习模式,提高迭代速度,快速更新粒子的位置,从而确立可使全局最优的粒子,效果与精度俱佳。如果将BP神经网络嵌入到PSO算法中去,就可以提升局部搜索能力,优化原算法的初始权值和与阈值,基于训练集对BP 神经网络实行训练,从而实现与BP神经算法的优势互补,从而完成预测模型的构建,故本文结合PSO算法建立了BP 神经网络的热门预测模型。
4.2.1 算法原理
结合PSO算法建立BP 神经网络的热门预测模型步骤如下:
步骤 1:由上一章提到的微博热度评价指标,根据公式(4-5)计算微博热门度量值,将该度量值根据时间先后存储在时间序列中,由此来构建模型的数据训练集。输入层中将作为输入值,以作为神经网络的输出值。
步骤 2:对粒子的位置与速度进行初始化,同时设置函数自变量个数,粒子种群的规模,迭代次数,粒子搜索空间与位置信息。
步骤 3:定义适应度函数,并计算得到全部粒子的适应度值。
步骤 4:判断Vi 和Xi是否超出设定的范围。
步骤 5:及时更新粒子的速度与位置,当达到设定的最大迭代次数或差值满足最小界限时,输出输出本次全局最优解,如果未达到条件则重复进行步骤4。
步骤 6:从每个粒子找到的最优解中寻找全局最优解。将输出的作为参考,在BP 神经网络输入层输入权值与初始阈值。
步骤 7:基于上述数据训练集,建立BP 神经网络预测模型,计算的预测误差,通过不断迭代修正权值,直到可以进行输出。
步骤 8:按照热度顺序,预测下一阶段的预测值Sl+1。
通过不断调整位置与参数,多次迭代后可以找到全局最优解,从而获取BP 神经网络输入层输入权值与初始阈值,就可以结合PSO算法构建BP神经网络预测模型,实现对话题热度的预测。
4.2.2 模型的实验环境与数据获取
本章是在第三章的研究基础上,基于matlab的仿真工具来建立预测模型,根据上一章中通过爬虫技术获取的五种类型热点话题的微博信息,由于时间原因,对每种类型的前两条微博按照公式(4-2),得到时间序列,构建结合PSO算法BP神经网络预测模型,对进行预测分析,然并对这些热门微博变化的趋势与变化程度进行分析。
4.2.3 预测模型的参数设置
本算法通过不断调整位置与参数,多次迭代后可以找到全局最优解,并确定最终参数,从而获取输入层输入权值与初始阈值。本文中在选取适应度函数时采用了matlab中的Ackley函数,使用该函数时首先要进行参数设置,我们将粒子的种群规模确定为20,加速常数设定为,粒子最大运动速度限制在5之内,最大迭代次数为100,将粒子位置限定在。图4-2是随粒子迭代次数增加,适应度值的变化:
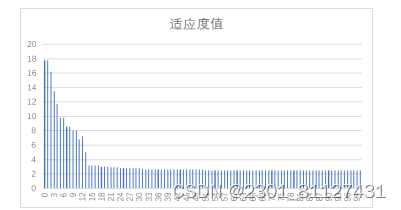
图4-2 粒子适应度值
由图可以看出随着迭代次数的增加,粒子的适应度值首先是迅速下降的,到第十五代时适应度值趋于稳定,这说明迭代次数越高,粒子适应度值越小,性能会越好。
本文将BP神经网络的结构设置为,将粒子学习速率设置为默认最优值,按照精度最大化原理选择合理的训练数据集规模。BP神经网络中的隐含层节点数大小会对预测结果产生比较大的影响,一般来说,隐含节点数越大,误差首先会降低,到达最优值后,误差又会随节点数增长变大,所以要从实际研究目的出发选取对预测结果产生误差最小的隐含节点数,本文拟通过结合文献经验与具体实验操作来决定隐含层节点数目,以使误差最小化。
首先进行仿真实验时,先将隐含层节点数的初始值设定成1,观测区间设定为,节点数累次增大1个,观察平均误差值的变化情况。每取一个隐含层节点书都要进行多组独立试验,来提高实验准确性,降低偶然因素的影响。实验结果表明,隐含层节点个数不同,平均相对误差也在随之波动,如下图4-3。
图4-3 不同隐含层节点个数的 MSE 值变化图
根据图4-3,隐含层节点数取5时,预测结果的平均相对误差最小。
4.2.4 预测结果与分析
本文根据平均相对误差(简称MSE)来判断预测模型的准确性,通过以下公式求得:
(4-4)
式(4-4)中,代表热度指数的预测值,为热度指数的实际值。由于时间关系,本章对第三章中的五类话题的前两个热门微博使用BP神经网络模型模拟话题热度的变化,预测下一时间阶段的热度指数。
当话题被推送为热门后,热门程度并不会保持不变,而是会随时间增大或降低,且经过不同的时间,热门程度指数的变化率也会存在差异。相隔的时间短,变化率可能会较大,相隔时间长,变化率会越小。为量化两者之间的联系,本文引入话题热门程度增长率,来衡量微博热门程度变化趋势,计算公式如下:
(4-5)
式(4-5)中,值含义为预测点与之前个时间间隔的热门趋势增长率的算数平均值,为第个时间间隔内的预测值,为第个时间间隔内的。其可以在一定程度上反映热门微博的趋势变化趋势与变化程度,值正负可以反映话题热门趋势,值大于0时说明该微博热门指数仍会上升,值小于0时则说明该微博热门指数会下降,通过分析的数值大小,我们可以衡量微博热门程度变化大小。同时,公式(4-5)能够衡量经过不同的时间间隔,对当前热门程度值的影响程度,相隔时间大,影响程度越小,相隔时间短,影响程度越大。
我们根据上一章的热门话题相关信息,结合 PSO算法建立了BP 神经网络热门微博预测模型,基于该模型,本文对五种话题下一时间阶段的热度变化趋势进行预测,并计算得到预测值,根据公式(4-5)得到每条微博的热门程度增长率,从而可以分析得到微博热门指数的变化趋势与变化程度,结合实际情况,进行对比分析,得出相应结论。如下表 4-1 ,我们基于预测模型记录了热门微博趋势预测的如下数据信息。
表4-1 热门微博趋势预测情况
热门微博 热门程度
变化趋势 变化强度
1 下降 0.3389 5179.3 4963
2 上升 0.3389 16248.2 15998.2
3 上升 0.3560 17837.4 16853
4 下降 0.4573 776.5 767
5 上升 0.1484 13668.9 13662.4
6 上升 0.1631 9843.7 9687.1
7 下降 0.0017 9323.5 9331.7
8 下降 0.2285 14571.8 14526.2
9 上升 0.3179 4925.7 4856.8
10 下降 0.2541 13953.5 13835.5
由表4-1,我们得到了微博热门指数的变化趋势、变化程度以及预测值,实际值。我们可以直观看到,预测值与实际值之间误差较小。根据热门程度增长率可以比较准确的反映出微博的热门程度变化趋势与变化强度。比如根据对表4-1中的预测结果分析,新闻类话题一二条微博热门趋势相反,且新闻类第二条微博的上升程度较第一条微博的下降程度更大,可以预测新闻类第二条微博在下一时间阶段会成为新闻类第一条热搜微博,经过时间验证,发现与实际相符,可以反映本文建立的预测模型,可以比较准确的预测热门程度变化趋势。
4.3 本章小结
本章利用PSO 算法较优的全局搜索特点提出了结合PSO算法的BP神经网络的微博热门预测模型。通过熟练掌握PSO算法与BP神经网络算法步骤,基于matlab仿真工具,完成实验参数的设置与隐含层节点数的选取,构建时间序列模型确定模型的输入值,最终得到了微博热门指数的变化趋势、变化程度以及热门程度指数的预测值。经过时间验证,发现预测结果与实际相符合,可以反映本文建立的预测模型,可以比较准确的预测热门程度变化趋势。
结 论
本文研究内容主要是以新浪微博为背景展开的,微博己经成为我们日常生活中必不可少的社交工具,已经成为了一个信息传播的大平台。在微博热搜之中,曝光度高、阅读数量或者互动数较高的内容信息比较容易成为热门微博,平台中包括“热搜排行榜”和“热门话题”等对每位用户进行推送,还会根据热度大小对热门微博的内容进行排序,本文分析了影响热门微博传播的一些因素之后,拟建立热度评价模型与热门微博预测模型,通过计算热门微博的热度与热门程度的变化趋势,来对话题热度的监控与预测。本文的主要成果有:
(1)运用爬虫工具爬取了五类话题的热门微博,结合用户影响力、内容影响力、传播影响力并基于因子分析法,建立了微博热度评价模型。在选择因子指标时,我们还另外增加了重度传播率、互动数两个指标,建立了比较完善的符合当前微博热度体系的的评级指标,从2019年4月21日在新浪微博平台用python分别爬取了关于新闻、体育、学习、情感、娱乐五个热门话题的前五条微博,并将参考指标进行处理加工,获得了相对应的各个微博因子数据,通过SPSS的因子分析得到各微博信息维度表达式以及热度计算公式,对数据进行整理分析,最终对其结果进行排序和对比,表明本热度评估模型模型具有较高的可信度。
(2)为弥补BO神经网路算法容易陷入局部最优的缺陷,提出了结合PSO算法的BP神经网络的微博热门预测模型。在分析了热门微博的判断指标之后,确定了通过熟练掌握PSO算法与BP神经网络算法步骤,基于matlab仿真工具,完成实验参数的设置与隐含层节点数的选取,构建时间序列模型确定模型的输入值,最终得到了微博热门指数的变化趋势、变化程度以及热门程度指数的预测值。经过时间验证,发现预测结果与实际相符合,可以反映本文建立的预测模型,可以比较准确的预测热门程度变化趋势,本次研究对现实情况的预判具有一定的指导意义。
参考文献
[1]Albert R, Jeong H, Barabasi AL. Error and attack tolerance of complex networks[J]. Nature, 2000, 406(6794): 378.
[2]Lerman K, Ghosh R. Information Contagion: an Empirical Study of the Spread of Newson Digg and Twitter Social Networks[J]. Computer Science, 2015,52: 166-176.
[3]Yang Zi, Guo Jingyi, Cai Keke. Understanding retweeting behaviors in social networks[C]. Proceedings of the 19th International Conference on Information and Knowledge Management. Toronto, Canada, 2010: 1633-1636.
[4]Zamparas V, Kanavos A, Makris C. Real Time Analytics for Measuring User Influence on Twitter[C]. IEEE, International Conference on TOOLS with Artificial Intelligence. IEEE, 2016: 591-597.
[5]Mei Y, Zhong Y, Yang J. Finding and Analyzing Principal Features for Measuring User Influence on Twitter[C]. IEEE First International Conference on Big Data Computing Service and Applications. IEEE Computer Society, 2015: 478-486.
[6]Zhu YX, Zhang XG, Sun GQ, etal. Influence of Reciprocal Links in Social Networks[J]. Plos One, 2013, 9(7): 103-107.
[7]Teutle ARM.Twitter: Network properties analysis: International Conference on Electronics, Communications and Computer, 2017: 4-15.
[8]Golder S A, Yardi S. Structural Predictors of Tie Formation in Twitter: Transitivity and Mutuality: IEEE International Conference on Social Computing, 2010:6-7.
[9]付文豪.社交网络信息传播的实证分析及应用[D]. 南京:南京邮电大学硕士论文, 2017: 10-27.
[10]郑斐然, 苗夺谦, 张志飞, 等. 一种中文微博新闻话题检测的方法[J]. 计算机科学, 2012,39(1): 138-141.
[11]张鲁民, 贾焰, 周斌, 等. 一种基于情感符号的在线突发事件检测方法[J]. 计算机学报, 2013, 36(8): 1659-1667.
[12]何跃, 蔡博驰. 基于因子分析法的微博热门程度评价模型[J]. 统计与决策, 2016(18): 52-54.
[13]宋蕾, 张培晶. 基于LDA主题建模的微博舆情分析系统研究[J]. 网络安全技术与应用, 2014(4): 5-6.
[14] Puvipadawat S,Murata T.Breaking news detectection and tracking in Twitter[C]. Proc of the 9th IEEE/WIC/ACMIntConf on Web Intelligence and Intelligent Agent Technology (WI-IAT’10), New York: ACM, 2010: 120-123.
[15]王长宁, 陈维勤, 许浩. 对微博舆情热门程度监测及预警的指标体系的研究[J]. 计算机与现代化, 2013(1): 126-129.
[16]赵晓航. 基于情感分析与主题分析的“后微博”时代突发事件政府信息公开研究——以新浪微博“天津爆炸”话题为例[J]. 图书情报工作, 2016, 60(20): 104-111.
[17]刘功申, 孟魁, 谢婧. 一种微博预警算法[J]. 计算机科学, 2014, 41(12): 33-37.
[18]Zhang Zhen-hai, Li Shi-ning, Li Zhi-gang, et al.Multi-label featurese lection algorithm based on information entropy [J]. Journal of Computer Research and Development, 2013, 50(6): 1177-1184.
[19]Yan Hong, Guan Yan-ping. Method to deter-mine quantity of internal nodes of back propagation neural networks and its demonstration[J]. Contro Engineering, 2009, 16(S1): 99-103.
[20]连芷萱, 兰月新, 夏一雪, 刘茉, 张双狮. 基于首发信息的微博舆情热度预测模型[J]. 情报科学, 2018, 36(09): 107-114.




)
)



网络安全竞赛样题卷④)





、strlen()、length()\以及size()用法区别)

)

方法(解决null、undefined、0之间的排序(混乱)问题))