目标检测作为当前计算机视觉落地的热点技术之一,已被广泛应用于自动驾驶、智慧园区、工业检测和卫星遥感等场景。开发者在研究相关目标检测技术时,通常需熟练掌握图像目标检测框架,如通用目标检测框架 YOLO 系列,旋转目标检测框架 R3Det 等技术,学习门槛较高,还需不断优化和改进算法,来获得理想的目标检测效果。随着大模型的发展,有效帮助开发者降低目标检测的使用门槛。
在2023 IDEA大会,IDEA研究院发布最新视觉提示(Visual Prompt)模型T-Rex,帮助释放计算机视觉更多应用场景。小编在上手使用T-Rex模型,直呼太香了!无需设计算法,开箱即用,简单通过拖拽方框,框住想识别的物体,点击“开始检测”,就自动将相似的结果识别出来:

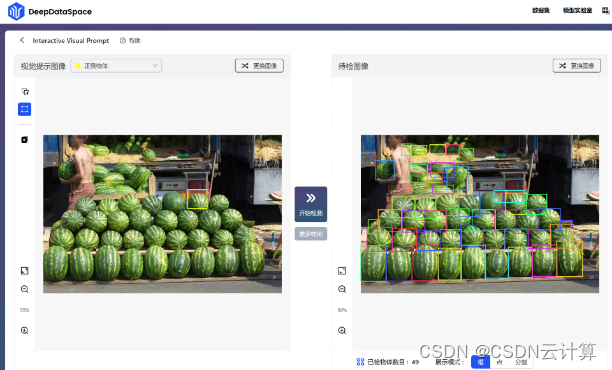
下面小编带大家体验一把!
零基础上手,秒识别检测,T-Rex模型来了!
打开视觉提示模型T-Rex的模型实验室官网:DeepDataSpace | The Go-To Choice for CV Data Visualization, Annotation, and Model Analysis,选择或者上传你想要检测的图像:
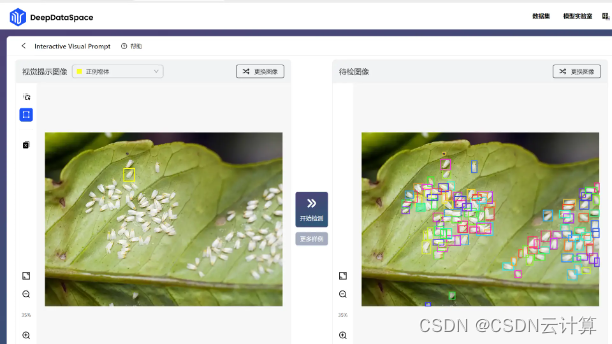
框住想要识别的物体,点击开始检测,秒出结果:
是不是很简单便捷?
其实背后的T-Rex模型大有来头!
今年4月,IDEA研究院发布的Grounded SAM (Grounding DINO + SAM),在Github已获得 11K Star,区别于只支持文字提示的Grounded SAM,T-Rex模型着重打造强交互的视觉提示功能。无需重新训练或微调,即可检测模型在训练阶段从未见过的物体。该模型不仅可应用于包括计数在内的所有检测类任务,还为智能交互标注场景提供新的解决方案,通过直观的视觉反馈与强交互性,也有助于提升检测的效率与精准度。目前,T-Rex 可应用在农业、零售、医疗、电子等行业。
据官网显示,T-Rex模型有以下四大特性:
开放集:不受预定义类别限制,具有检测一切物体的能力
视觉提示:利用视觉示例指定检测目标,克服罕见、复杂物体难以用文字充分表达的问题,提高提示效率
直观的视觉反馈:提供边界框等直观视觉反馈,帮助用户高效评估检测结果
交互性:用户便捷参与检测过程,对模型结果进行纠错
除了上面笔者试用的最基础的单轮提示模式,目前T-Rex模型还支持以下三种进阶模式:
· 多轮正例模式:适用于视觉提示不够精准造成漏检的场景
· 正例+负例模式: 适用于视觉提示带有二义性造成误检的场景
· 跨图模式:适用于通过单张参考图提示检测他图的场景
大家可以多多尝试!
为什么是T-Rex?
我们已迈入“大模型时代”,在许多领域大模型都展现出巨大潜力和价值。 如今我们可以简单用一句话、一个提示词就可以让AI帮助我们生成一张图片、一篇文章。然而在一些情况下,例如工业场景中的物体在日常生活中较为罕见,难以用语言描述。在此情况下,视觉提示显然是更高效的方法。T-Rex通过图片来提示,达到 “一图胜千言”的准确与高效。
谈及计算机视觉的发展,IDEA研究院创院理事长、美国国家工程院外籍院士沈向洋表示,首先是计算机视觉的应用场景长尾,其次是其场景碎片化,每个应用场景不一样。他出,计算机视觉领域在呼唤通用大模型的来临。以GPT-4V为代表的多模态大模型,是在语言能力上增加视觉能力;IDEA研究院的计算机视觉团队则选择了另一条路径,先将基础的视觉能力做到极致,再增加语言能力。
仔细思考,大模型的意义是让我们从判别式AI走向深层次判别式的AI,前者从数据和信号中去提取特征进行识别,完成像人脸识别语音识别、图像识别等任务,后者可以基于海量数据训练生成文字、语言、图片、视频等,更加智能、高效,有效提高生产力。毋庸置疑,通过之前的Grounded SAM发布,到如今T-Rex的推出,IDEA研究院走出自己的计算机视觉之路。
想了解更多T-Rex详情,可查看GitHub:trex-counting.github.io
)


)





)

)



)

(网络编程,UDP,TCP))

