提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- Pipeline
- 举例
- 比较普通模式与 PipeLine 模式
- 小结:
Pipeline
前面我们已经说过,Redis客户端执行一条命令分为如下4个部分:1)发送命令2)命令排队3)命令执行4)返回结果。
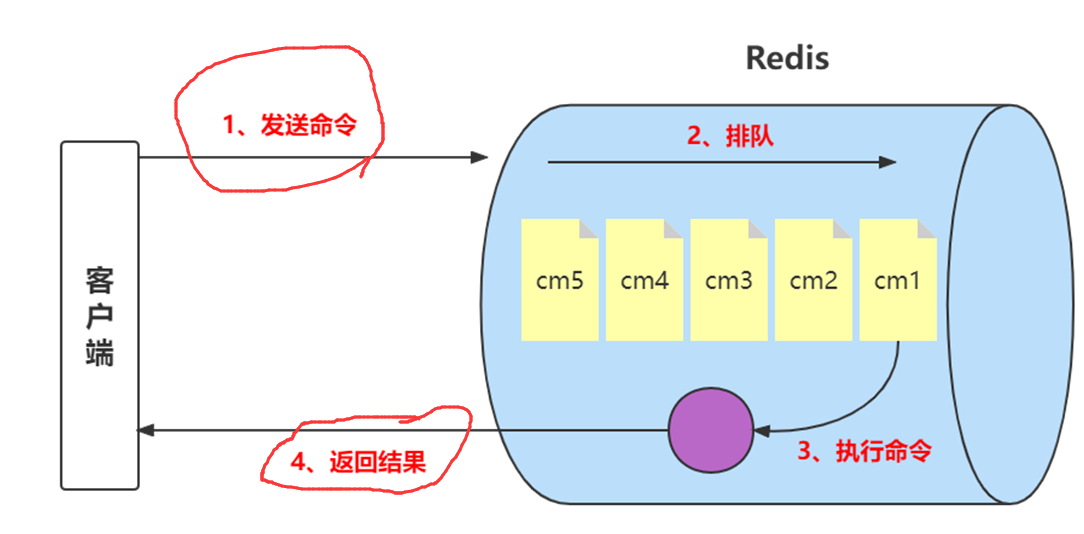
其中1和4花费的时间称为Round Trip Time (RTT,往返时间),也就是数据在网络上传输的时间。
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT。
但大部分命令是不支持批量操作的,例如要执行n次 hgetall命令,并没有mhgetall命令存在,需要消耗n次RTT。
举例
举例:Redis的客户端和服务端可能部署在不同的机器上。例如客户端在本地,Redis服务器在阿里云的广州,两地直线距离约为800公里,那么1次RTT时间=800 x2/ ( 300000×2/3 ) =8毫秒,(光在真空中传输速度为每秒30万公里,这里假设光纤为光速的2/3 )。而Redis命令真正执行的时间通常在微秒(1000微妙=1毫秒)级别,所以才会有Redis 性能瓶颈是网络这样的说法。
Pipeline(流水线)机制能改善上面这类问题,它能将一组 Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端,没有使用Pipeline执行了n条命令,整个过程需要n次RTT。
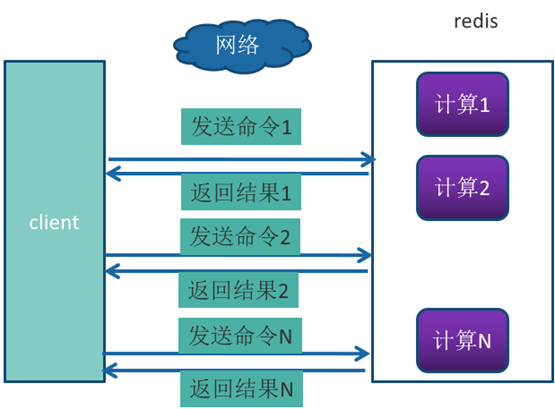
使用Pipeline 执行了n次命令,整个过程需要1次RTT。
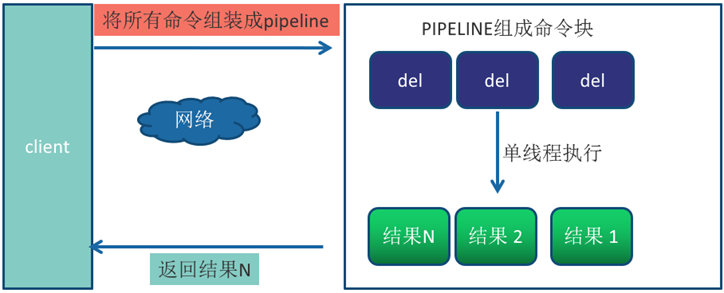
Pipeline并不是什么新的技术或机制,很多技术上都使用过。而且RTT在不同网络环境下会有不同,例如同机房和同机器会比较快,跨机房跨地区会比较慢。
redis-cli的–pipe选项实际上就是使用Pipeline机制,但绝对部分情况下,我们使用Java语言的Redis客户端中的Pipeline会更多一点。
比较普通模式与 PipeLine 模式
测试环境:
Windows:Eclipse + jedis2.9.0 + jdk 1.7
Ubuntu:部署在虚拟机上的服务器 Redis 3.0.7
/** 测试普通模式与 PipeLine 模式的效率: * 测试方法:向 redis 中插入 10000 组数据*/public static void testPipeLineAndNormal(Jedis jedis)throws InterruptedException {Logger logger = Logger.getLogger("javasoft");long start = System.currentTimeMillis();for (int i = 0; i < 10000; i++) {jedis.set(String.valueOf(i), String.valueOf(i));}long end = System.currentTimeMillis();logger.info("the jedis total time is:" + (end - start));Pipeline pipe = jedis.pipelined(); // 先创建一个 pipeline 的链接对象long start_pipe = System.currentTimeMillis();for (int i = 0; i < 10000; i++) {pipe.set(String.valueOf(i), String.valueOf(i));}pipe.sync(); // 获取所有的 responselong end_pipe = System.currentTimeMillis();logger.info("the pipe total time is:" + (end_pipe - start_pipe));BlockingQueue<String> logQueue = new LinkedBlockingQueue<String>();long begin = System.currentTimeMillis();for (int i = 0; i < 10000; i++) {logQueue.put("i=" + i);}long stop = System.currentTimeMillis();logger.info("the BlockingQueue total time is:" + (stop - begin));}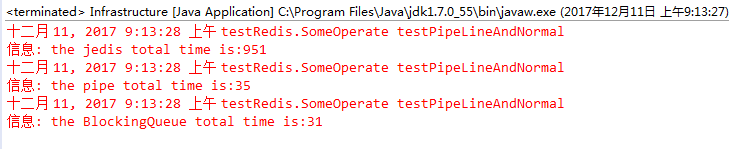
小结:
1、Pipeline执行速度一般比逐条执行要快。
2、客户端和服务端的网络延时越大,Pipeline的效果越明显。
Pipeline虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否则一次组装Pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成,比如可以将Pipeline的总发送大小控制在内核输入输出缓冲区大小之内或者控制在单个TCP 报文最大值1460字节之内。
内核的输入输出缓冲区大小一般是4K-8K,不同操作系统会不同(当然也可以配置修改)
最大传输单元(Maximum Transmission Unit,MTU),这个在以太网中最大值是1500字节。那为什么单个TCP 报文最大值是1460,因为因为还要扣减20个字节的IP头和20个字节的TCP头,所以是1460。
同时Pipeline只能操作一个Redis实例,但是即使在分布式Redis场景中,也可以作为批量操作的重要优化手段。


![.[[backup@waifu.club]].wis勒索病毒数据怎么处理|数据解密恢复](http://pic.xiahunao.cn/.[[backup@waifu.club]].wis勒索病毒数据怎么处理|数据解密恢复)




: Const Correctness, Const成员函数和Const Cast)
)







函数,有什么用法区别)


