Zheyuan Jiang, Jingyue Gao, Jianyu Chen (2022). Unsupervised Skill Discovery via Recurrent Skill Training. In Conference on Neural Information Processing Systems (NeurIPS), 2022.
通过循环技能训练发现无监督技能
1、Motivation
以往的无监督技能发现方法主要使用的是并行训练,文章作者发现,当不同技能访问的状态重叠时,并行训练过程有时会阻碍探索,这导致状态覆盖率低,限制了学习技能的多样性。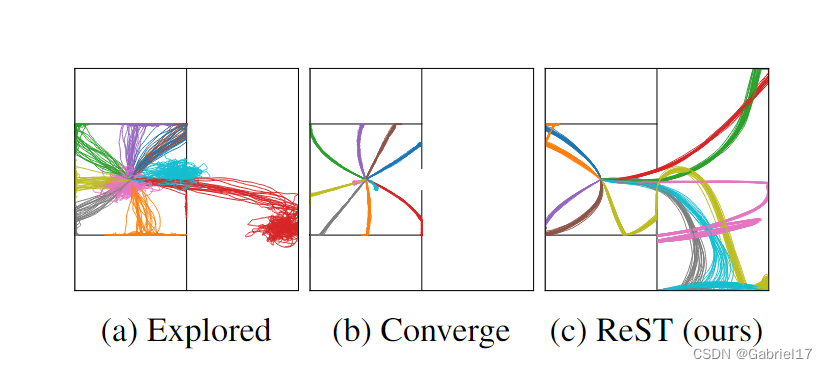
作者指出,这在DIAYN中表现为探索退化,即:当并行训练的多个技能访问同一状态时,该状态将被阻止再次访问,收敛后的技能可能会避免访问某些状态,即使在训练期间对它们进行了探索。
2、Introduction
作者提出了名为ReST的方法可以解决上述探索退化的问题。ReST不是并行地训练所有的技能,而是以一种循环的方式一个接一个地训练技能,并附带一个内在的奖励,以阻止覆盖其他技能的频繁访问状态。
本文贡献:
- 发现了探索退化的现象。
- 造成探索退化的原因是多个技能访问相同的状态会减少并行训练中的Mutual Information奖励(猜测这句话的意思是,在例如DIAYN中定义的objective是最大化I(s;z),即最大化state和特定skill之间的关联,但是当有多个skill访问相同的state时,反而会减小state与某种特定的skill之间的关联,使I(s;z)减小)。而ReST方法提供了一种基于状态覆盖的Intrinsic Reward,可以有效地防止多种技能访问相同的状态。
- 实验表明ReST方法与baseline方法相比获得了更好的状态覆盖率和散度。
3、Method
ReST方法解决探索退化问题的核心思想是鼓励后一种经过训练的skill避免访问其他skill经常访问的状态。
为了实现这一核心思想,有两种方案:(1)确定每个skill访问每个状态的频率 (2)确定给定状态对于一个skill的新颖性程度
本文主要使用的是方案(2),基于RND来计算给定状态对于一个skill的novelty为多少(方案(2)相对方案(1)更容易实现,因为在之前的NovelD方法中,就有使用过RND来计算novelty)。
ReST方法对于每一个skill都分配了一对RND网络,而对于RND的训练最小化以下Loss。
L i = E s ∼ p ( s ∣ z i ) [ ∣ ∣ f ^ i ( s ) − f i ( s ) ∣ ∣ 2 ] \mathcal{L}_i=\mathbb{E}_{s\sim p(s|z_i)}\left[||\hat{f}_i(s)-f_i(s)||^2\right] Li=Es∼p(s∣zi)[∣∣f^i(s)−fi(s)∣∣2]
因为需要在训练某种skill时避免访问其他技能访问过的状态(即基于它相对最小的奖励),所以将奖励函数ri定义为:
r i ( s t , a t ) = min j ∈ { 1 , 2 , . . . , N } , j ≠ i ∣ ∣ f j ^ ( s t + 1 ) − f j ( s t + 1 ) ∣ ∣ 2 r_i(s_t,a_t)=\min_{j\in\{1,2,...,N\},j\neq i}||\hat{f_j}(s_{t+1})-f_j(s_{t+1})||^2 ri(st,at)=j∈{1,2,...,N},j=imin∣∣fj^(st+1)−fj(st+1)∣∣2
以此使访问其他skill经常访问过的状态时,获得的reward最小。
但是这种reward会使训练难以收敛,于是文章作者又提出了另外一种reward方法。
r i ( s t , a t ) = − log [ ∑ j ∈ { 1 , 2 , . . . , N } , j ≠ i e ( − α ⋅ ∣ ∣ f ^ j ( s t + 1 ) − f j ( s t + 1 ) ∣ ∣ 2 ) N − 1 ] r_i(s_t,a_t)=-\log\left[\frac{\sum_{j\in\{1,2,...,N\},j\neq i}e^{\left(-\alpha\cdot||\hat{f}_j(s_{t+1})-f_j(s_{t+1})||^2\right)}}{N-1}\right] ri(st,at)=−log N−1∑j∈{1,2,...,N},j=ie(−α⋅∣∣f^j(st+1)−fj(st+1)∣∣2)
4、实验
本文实验基于PPO算法实现。
- 通过在2D navigations tasks上的实验发现,ReST方法相比于其他例如DIAYN等方法更容易突破环境中的bottlenecks,能够在算法收敛后有更广泛的状态覆盖。
- 通过在Mujoco环境中的实验发现,ReST方法能够发现dynamic的机器人运动技能,而例如DIAYN等方法倾向于发现static的技能。
5、结论
这篇文章主要基于recurrent+RND的方法解决了以往基于mutual information的技能发现方法中的探索退化问题。通过为每个skill分配一对RND网络,来计算给定的状态对于一个skill的新颖度。
作者提出ReST还有一些局限性:(1)样本训练效率更差,因为每个epoch只能训练一个skill。(2)intrinsic reward需要基于其他所有skill的RND网络的预测误差,这导致计算复杂度很高(这就限制了N的大小,并且本文方法好像无法动态扩展N的大小)。(3)ReST方法无法扩展到continuous latent上。
6、伪代码











![[科普] 无刷直流电机驱动控制原理图解](http://pic.xiahunao.cn/[科普] 无刷直流电机驱动控制原理图解)








