今天来看看架构的演变过程
一、单体架构

从图中可以看到,所有服务耦合在一起,数据库存在单点,一旦其中一个服务出现问题时,整个工程都需要重新发布,从而导致整个业务不能提供响应
这种架构对于小项目而言是没有什么问题的,反而更加灵活,但是当业务量暴增的时候,就无法灵活应对了
二、第一次切分
单体架构无法满足业务增长的需求,需要对数据库进行进一步的切分,以提高扩展性
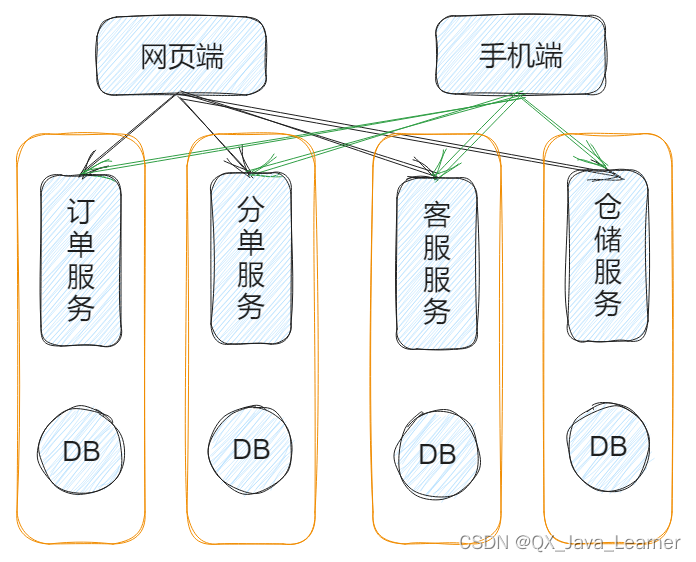
业务通过进程间的服务进行互相调用,数据库之间没有耦合性,不会存在单点故障
前端只需要调用相应的服务,返回自身需要的数据库,然后与用户进行交互
在进行第一次切分后,相对于单体架构已经有所进步,但数据库层面仍然存在问题
根据数据量需要评估是否使用读写分离的设计,服务层面也增加了相应的复杂性,前端调用随着调用接口数量的增加也急需治理
三、服务拆分带来的问题
服务拆分后,又有新的问题出现了
客户端如何访问这些服务?这些服务的调用情况?切分是否合理?是否安全?如果受到攻击应该如何应对?是否可以使用限流或降级的方式来及时解决?
应对这些问题,API 网关是一个不错的解决方案。当有新的设备需要调用这些接口时,可以复用原有接口,不需要二次开发
接口的维护也会更有条理性,对于访问次数、安全等问题,都可以在这一层进行解决
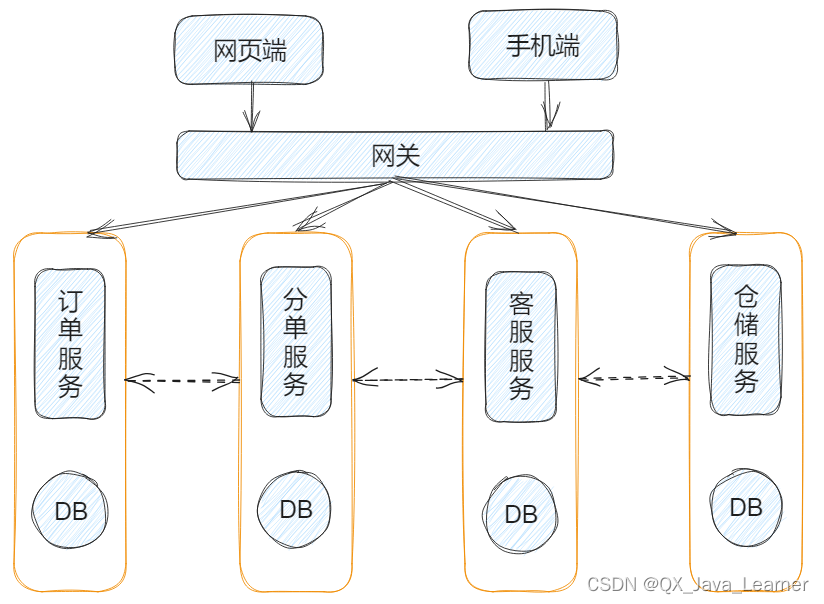
当多种服务需要互相调用时,服务的数量会急剧增加,服务的治理就成为新的问题,另外还有不同服务的版本问题,如果不能管理起来,服务的调用就会非常混乱
一般的分布式服务都有一个注册中心,例如,Dubbo 是基于 ZooKeeper 进行的二次开发,自身提供管理控制台,可以对服务进行注册和查找,SpringCloud 有 Eureka,还有 etcd、Consul 等可供选择
如此一来,整体上已经达到了一个非常好的状态,但是每个应用服务仍然存在着单点问题,当一个服务出现问题时,有可能导致连锁反应,最终导致整个系统瘫痪。这时需要除监控告警外的一种容错机制来保障整体服务的可运行性
通过网关层的反向代理来实现高可用是一个不错的解决方案
访问层无须了解整个体系有多少应用服务,只需要关心服务是否能提供服务,并且对必要的接口进行检测即可。当发现服务无法正常提供服务时,提供相应的告警机制,通知相关人员处理
随着服务的切分、业务的扩展,数据量的激增也是一个非常大的问题,若采用传统的方案应对,各种关系型数据库都有瓶颈,吧运算量比较大、比较耗资源的运算通过跨库来统计查询的需求
随着数据量的不断增涨,需要将业务和统计分离
统计一般都是比较耗时的应用,比如计算用户的留存情况,需要分析一周甚至更长周期内的用户数据,若使用在线分析显然不现实,对于大数据量的分析和数据挖掘,需要从业务中抽取数据进行离线分析,然后将分析的结果进行展示
参考资料:《微服务架构实战》—— 张锋
一 叶 知 秋,奥 妙 玄 心





)












)
