一、N 路归并排序
1.1、概序
我们知道算法中有一种叫做分治思想,一个大问题我们可以采取分而治之,各个突破,当子问题解决了,大问题也就 KO 了,还有一点我们知道内排序的归并排序是采用二路归并的,因为分治后有 LogN 层,每层两路归并需要 N 的时候,最后复杂度为 NlogN,那么外排序我们可以将这个“二”扩大到 M,也就是将一个大文件分成 M 个小文件,每个小文件是有序的,然后对应在内存中我们开 M 个优先队列,每个队列从对应编号的文件中读取 TopN 条记录,然后我们从 M 路队列中各取一个数字进入中转站队列,并将该数字打上队列编号标记,当从中转站出来的最小数字就是我们最后要排序的数字之一,因为该数字打上了队列编号,所以方便我们通知对应的编号队列继续出数字进入中转站队列,可以看出中转站一直保存了 M 个记录,当中转站中的所有数字都出队完毕,则外排序结束。如果大家有点蒙的话,我再配合一张图,相信大家就会一目了然,这考验的是我们的架构能力。
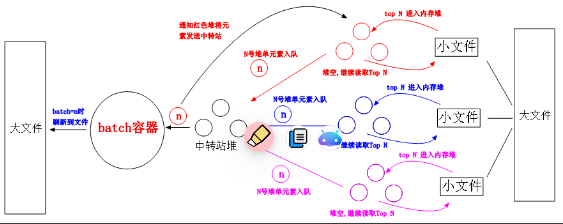
图中这里有个 Batch 容器,这个容器我是基于性能考虑的,当 batch=n 时,我们定时刷新到文件中,保证内存有足够的空间。
1.2、构建
<1> 生成数据
这个基本没什么好说的,采用随机数生成 n 条记录。
<2> 切分数据
根据实际情况我们来决定到底要分成多少个小文件,并且小文件的数据必须是有序的,小文件的个数也对应这内存中有多少个优先队列。
<3> 加入队列
我们知道内存队列存放的只是小文件的 topN 条记录,当内存队列为空时,我们需要再次从小文件中读取下一批的 TopN 条数据,然后放入中转站继续进行比较。
<4> 测试
最后我们来测试一下:
数据量:short.MaxValue。
内存存放量:1200。
在这种场景下,我们决定每个文件放 1000 条,也就有 33 个小文件,也就有 33 个内存队列,每个队列取 Top100 条,Batch=500 时刷新
硬盘,中转站存放 332 个数字(因为入中转站时打上了队列标记),最后内存活动最大总数为:sum=33100+500+66=896<1200。
时间复杂度为 N*logN。
总的代码:
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Diagnostics;using System.Threading;using System.IO;using System.Threading.Tasks;namespace ConsoleApplication2{public class Program{public static void Main(){//生成2^15数据CreateData(short.MaxValue);//每个文件存放1000条var pageSize = 1000;//达到batchCount就刷新记录var batchCount = 0;//判断需要开启的队列var pageCount = Split(pageSize);//内存限制:1500条List<PriorityQueue<int?>> list = new List<PriorityQueue<int?>>();//定义一个队列中转器PriorityQueue<int?> queueControl = new PriorityQueue<int?>();//定义每个队列完成状态bool[] complete = new bool[pageCount];//队列读取文件时应该跳过的记录数int[] skip = new int[pageCount];//是否所有都完成了int allcomplete = 0;//定义 10 个队列for (int i = 0; i < pageCount; i++){list.Add(new PriorityQueue<int?>());//i: 记录当前的队列编码//list: 队列数据//skip:跳过的条数AddQueue(i, list, ref skip);}//初始化操作,从每个队列中取出一条记录,并且在入队的过程中//记录该数据所属的 “队列编号”for (int i = 0; i < list.Count; i++){var temp = list[i].Dequeue();//i:队列编码,level:要排序的数据queueControl.Eequeue(i, temp.level);}//默认500条写入一次文件List<int> batch = new List<int>();//记录下次应该从哪一个队列中提取数据int nextIndex = 0;while (queueControl.Count() > 0){//从中转器中提取数据var single = queueControl.Dequeue();//记录下一个队列总应该出队的数据nextIndex = single.t.Value;var nextData = list[nextIndex].Dequeue();//如果改对内弹出为null,则说明该队列已经,需要从nextIndex文件中读取数据if (nextData == null){//如果该队列没有全部读取完毕if (!complete[nextIndex]){AddQueue(nextIndex, list, ref skip);//如果从文件中读取还是没有,则说明改文件中已经没有数据了if (list[nextIndex].Count() == 0){complete[nextIndex] = true;allcomplete++;}else{nextData = list[nextIndex].Dequeue();}}}//如果弹出的数不为空,则将该数入中转站if (nextData != null){//将要出队的数据 转入 中转站queueControl.Eequeue(nextIndex, nextData.level);}batch.Add(single.level);//如果batch=500,或者所有的文件都已经读取完毕,此时我们要批量刷入数据if (batch.Count == batchCount || allcomplete == pageCount){var sw = new StreamWriter(Environment.CurrentDirectory + "//result.txt", true);foreach (var item in batch){sw.WriteLine(item);}sw.Close();batch.Clear();}}Console.WriteLine("恭喜,外排序完毕!");Console.Read();}#region 将数据加入指定编号队列/// <summary>/// 将数据加入指定编号队列/// </summary>/// <param name="i">队列编号</param>/// <param name="skip">文件中跳过的条数</param>/// <param name="list"></param>/// <param name="top">需要每次读取的条数</param>public static void AddQueue(int i, List<PriorityQueue<int?>> list, ref int[] skip, int top = 100){var result = File.ReadAllLines((Environment.CurrentDirectory + "//" + (i + 1) + ".txt")).Skip(skip[i]).Take(top).Select(j => Convert.ToInt32(j));//加入到集合中foreach (var item in result)list[i].Eequeue(null, item);//将个数累计到skip中,表示下次要跳过的记录数skip[i] += result.Count();}#endregion#region 随机生成数据/// <summary>/// 随机生成数据///<param name="max">执行生成的数据上线</param>/// </summary>public static void CreateData(int max){var sw = new StreamWriter(Environment.CurrentDirectory + "//demo.txt");for (int i = 0; i < max; i++){Thread.Sleep(2);var rand = new Random((int)DateTime.Now.Ticks).Next(0, int.MaxValue >> 3);sw.WriteLine(rand);}sw.Close();}#endregion#region 将数据进行分份/// <summary>/// 将数据进行分份/// <param name="size">每页要显示的条数</param>/// </summary>public static int Split(int size){//文件总记录数int totalCount = 0;//每一份文件存放 size 条 记录List<int> small = new List<int>();var sr = new StreamReader((Environment.CurrentDirectory + "//demo.txt"));var pageSize = size;int pageCount = 0;int pageIndex = 0;while (true){var line = sr.ReadLine();if (!string.IsNullOrEmpty(line)){totalCount++;//加入小集合中small.Add(Convert.ToInt32(line));//说明已经到达指定的 size 条数了if (totalCount % pageSize == 0){pageIndex = totalCount / pageSize;small = small.OrderBy(i => i).Select(i => i).ToList();File.WriteAllLines(Environment.CurrentDirectory + "//" + pageIndex + ".txt", small.Select(i => i.ToString()));small.Clear();}}else{//说明已经读完了,将剩余的small记录写入到文件中pageCount = (int)Math.Ceiling((double)totalCount / pageSize);small = small.OrderBy(i => i).Select(i => i).ToList();File.WriteAllLines(Environment.CurrentDirectory + "//" + pageCount + ".txt", small.Select(i => i.ToString()));break;}}return pageCount;}#endregion}}
优先队列:
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Diagnostics;using System.Threading;using System.IO;namespace ConsoleApplication2{public class PriorityQueue<T>{/// <summary>/// 定义一个数组来存放节点/// </summary>private List<HeapNode> nodeList = new List<HeapNode>();#region 堆节点定义/// <summary>/// 堆节点定义/// </summary>public class HeapNode{/// <summary>/// 实体数据/// </summary>public T t { get; set; }/// <summary>/// 优先级别 1-10个级别 (优先级别递增)/// </summary>public int level { get; set; }public HeapNode(T t, int level){this.t = t;this.level = level;}public HeapNode() { }}#endregion#region 添加操作/// <summary>/// 添加操作/// </summary>public void Eequeue(T t, int level = 1){//将当前节点追加到堆尾nodeList.Add(new HeapNode(t, level));//如果只有一个节点,则不需要进行筛操作if (nodeList.Count == 1)return;//获取最后一个非叶子节点int parent = nodeList.Count / 2 - 1;//堆调整UpHeapAdjust(nodeList, parent);}#endregion#region 对堆进行上滤操作,使得满足堆性质/// <summary>/// 对堆进行上滤操作,使得满足堆性质/// </summary>/// <param name="nodeList"></param>/// <param name="index">非叶子节点的之后指针(这里要注意:我们/// 的筛操作时针对非叶节点的)/// </param>public void UpHeapAdjust(List<HeapNode> nodeList, int parent){while (parent >= 0){//当前index节点的左孩子var left = 2 * parent + 1;//当前index节点的右孩子var right = left + 1;//parent子节点中最大的孩子节点,方便于parent进行比较//默认为left节点var min = left;//判断当前节点是否有右孩子if (right < nodeList.Count){//判断parent要比较的最大子节点min = nodeList[left].level < nodeList[right].level ? left : right;}//如果parent节点大于它的某个子节点的话,此时筛操作if (nodeList[parent].level > nodeList[min].level){//子节点和父节点进行交换操作var temp = nodeList[parent];nodeList[parent] = nodeList[min];nodeList[min] = temp;//继续进行更上一层的过滤parent = (int)Math.Ceiling(parent / 2d) - 1;}else{break;}}}#endregion#region 优先队列的出队操作/// <summary>/// 优先队列的出队操作/// </summary>/// <returns></returns>public HeapNode Dequeue(){if (nodeList.Count == 0)return null;//出队列操作,弹出数据头元素var pop = nodeList[0];//用尾元素填充头元素nodeList[0] = nodeList[nodeList.Count - 1];//删除尾节点nodeList.RemoveAt(nodeList.Count - 1);//然后从根节点下滤堆DownHeapAdjust(nodeList, 0);return pop;}#endregion#region 对堆进行下滤操作,使得满足堆性质/// <summary>/// 对堆进行下滤操作,使得满足堆性质/// </summary>/// <param name="nodeList"></param>/// <param name="index">非叶子节点的之后指针(这里要注意:我们/// 的筛操作时针对非叶节点的)/// </param>public void DownHeapAdjust(List<HeapNode> nodeList, int parent){while (2 * parent + 1 < nodeList.Count){//当前index节点的左孩子var left = 2 * parent + 1;//当前index节点的右孩子var right = left + 1;//parent子节点中最大的孩子节点,方便于parent进行比较//默认为left节点var min = left;//判断当前节点是否有右孩子if (right < nodeList.Count){//判断parent要比较的最大子节点min = nodeList[left].level < nodeList[right].level ? left : right;}//如果parent节点小于它的某个子节点的话,此时筛操作if (nodeList[parent].level > nodeList[min].level){//子节点和父节点进行交换操作var temp = nodeList[parent];nodeList[parent] = nodeList[min];nodeList[min] = temp;//继续进行更下一层的过滤parent = min;}else{break;}}}#endregion#region 获取元素并下降到指定的level级别/// <summary>/// 获取元素并下降到指定的level级别/// </summary>/// <returns></returns>public HeapNode GetAndDownPriority(int level){if (nodeList.Count == 0)return null;//获取头元素var pop = nodeList[0];//设置指定优先级(如果为 MinValue 则为 -- 操作)nodeList[0].level = level == int.MinValue ? --nodeList[0].level : level;//下滤堆DownHeapAdjust(nodeList, 0);return nodeList[0];}#endregion#region 获取元素并下降优先级/// <summary>/// 获取元素并下降优先级/// </summary>/// <returns></returns>public HeapNode GetAndDownPriority(){//下降一个优先级return GetAndDownPriority(int.MinValue);}#endregion#region 返回当前优先队列中的元素个数/// <summary>/// 返回当前优先队列中的元素个数/// </summary>/// <returns></returns>public int Count(){return nodeList.Count;}#endregion}}








)
:017柳树、喜树、珙桐、木棉、楝、枫杨、竹柏、百日青、翅荚香槐、皂荚、灯台树)

-基础入门)


之系统分区电压域)



)
