文章目录
- 一、批量插入数据
- 二、分页
- 1.分页器的思路
- 2.用一个案例试试
- 3.自定义分页器
一、批量插入数据
当我们需要大批量创建数据的时候,如果一条一条的去创建或许需要猴年马月 我们可以先试一试for循环试试
我们首先建立一个模型类来创建一个表
models.py;建议连接到MySQL数据库下进行实验
class Book(models.Model):name = models.CharField(max_length=32)'记得创建好模型类后,执行数据库迁移命令:makemigrations、migrate'
配置路由文件urls.py
from django.conf.urls import urlfrom django.contrib import adminfrom app import viewsurlpatterns = [url(r'^admin/', admin.site.urls),url(r'^data/', views.data),]
'html代码'<div class="col-md-8 col-md-offset-2">{% for book_obj in book_query %}<p class="text-center" style="font-size:20px;">{{ book_obj.name }}</p>{% endfor %}</div>'views.py'from app import modelsdef data(request):for i in range(10000):models.Book.objects.create(name=f"第{i}本书")book_query = models.Book.objects.all()return render(request,'data.html',locals())'''浏览器访问一个django路由,立刻创建1万条数据并展示到前端页面涉及到大批量数据的创建,直接使用create可能会造成数据库崩溃所以django就有一个专门来创建的参数就是 dulk_create还有dulk_update 效率极高'''
从最后批量插入数据的结果来看,效率太慢了。
原因就是每一次插入一条数据时,都需要和数据库做链接,因此创建效率就特别慢。
所以我们就用到了django专门用来批量创建数据的参数dulk_create
from app import modelsdef data(request):book_list = []for i in range(10000):book_obj = models.Book(name=f"第{i}本书")book_list.append(book_obj)'''上述代码可以简化为一行'''[models.Book(name=f"第{i}本书") for i in range(10000)]models.Book.objects.bulk_create(book_list) # 批量创建# models.Book.objects.bulk_update(book_list) # 批量更新book_query = models.Book.objects.all()return render(request,'data.html',locals())
最终结果:
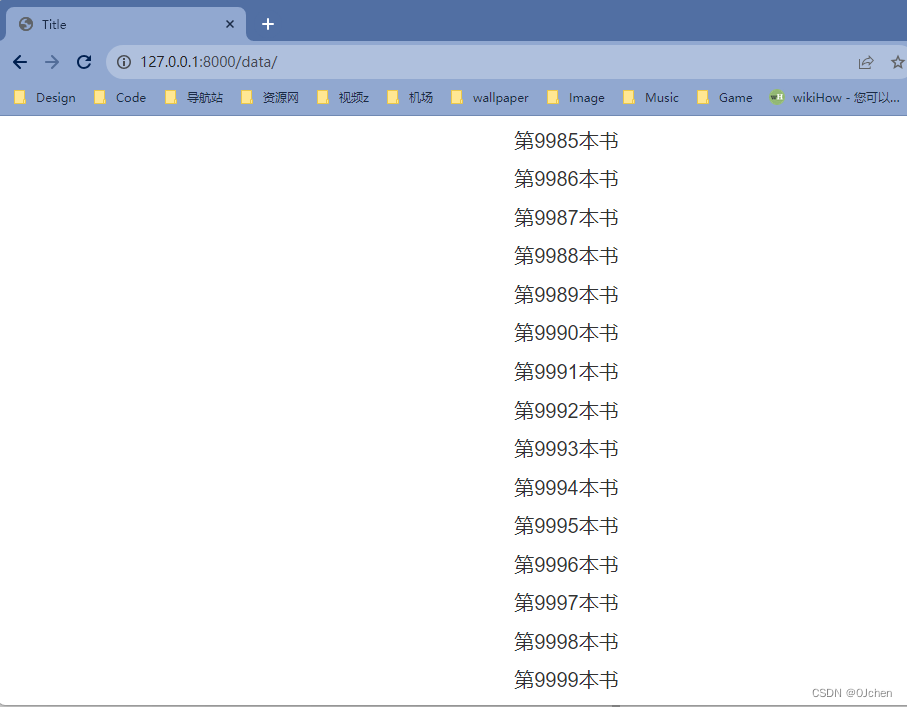
从浏览器展示中可以看到,使用了
bulk_create批量创建插入数据时,极快的创建完成后并在同一个页面展示出来了。但是这样展示出来的效果不够美观,所以我们需要把展示的数据进行分页展示
二、分页
这里我们将利用Django提供给我们的一个分页模块来帮助我们的页面达到一个分页的效果
1.分页器的思路
1.get请求也是可以携带参数的,所以我们在朝后端发送查看数据的同时可以携带一个参数告诉后端我们想看第几页的数据
current_page = request.GET.get('page',1) # 获取用户想访问的页码,如果没有,默认展示第一页try: # 由于后端接收到的前端数据是字符串类型所以我们这里做类型转换处理加异常捕捉current_page = int(current_page)except Exception as f:current_page = 1# 还需要定义页面到底展示几条数据per_page_num = 10 # 一页展示10条数据# 需要对总数据进行切片操作,需要确定切片起始位置和终止位置start_page = (current_page-1)*per_page_numend_page = current_page*per_page_num'''下面需要研究current_page、per_page_num、start_page、end_page四个参数之间的数据关系per_page_num = 10current_page start_page end_page1 0 102 10 203 20 30 4 30 40per_page_num = 5current_page start_page end_page1 0 52 5 103 10 15 4 15 20可以很明显的看出规律start_page = (current_page-1)*per_page_numend_page = current_page*per_page_num'''
2.数据总页面获取
内置方法之divmoddivmod(100,10)#(10,0) 10页divmod(101,10)#(10,1) 11页divmod(99,10)#(9,9) 10页'''余数只要不是0就需要在第一个数字上加一'''总共需要多少页数info_queryset = models.UserInfo.objects.all()all_count = info_queryset.count() # 数据总条数all_pager,more = divmod(all_count,per_page_num)if more: # 有余数则总页数加一all_pager += 1
3.利用start_page和end_page对总数据进行切片取值再传入前端页面就能够实现分页展示
后端info_list = models.UesrInfo.objects.all()[start_page:end_page]return render(request,'info.html',locals())前端{% for info in info_list %}<p>{{ info.name }}</p>{% endfor %}
4.由于模版语法没有range功能,但是我们需要循环产生很多分页标签,所以考虑后端生成传递给前端页面
后端
html_srt = ''xxx = current_pageif xxx<6:xxx = 6for i in range(xxx - 5,xxx+6)if current_page == i:html_str += '<li class="active"> <a href="?page=%s">%s</a></li>' %(i,i)else:html_str += '<li>href="?page=%s">%s</a></li>' % (i,i)
前端
{{ html_str }}
分页器主要是处理逻辑,代码最后很简单推导流程:1.queryset支持切片操作(正数)2.分页样式添加3.页码展示如果根据总数据和每页展示的数据得出总页码divmod()4.如何渲染出所有的页码标签前端模版语法不支持range 但是后端支持,我们可以在后端创建好html标签然后传递给html页面使用5.如何限制住展示的页面标签个数页码推荐使用奇数位(对称美),利用当前页前后固定位置来限制6.首尾页码展示范围问题上述是分页器组件的推导流程,我们无需真正编写django自带一个分页器组件,但是不是很好用,所以我们也可以自己自定义一个分页器
2.用一个案例试试
实验环境搭建
我们首先建立一个模型类来存储数据,因为要实现分页需要一定的数据量。
models.py;建议连接到MySQL数据库下进行实验
class UserInfo(models.Model):name = models.CharField(max_length=32)age = models.CharField(max_length=32)address = models.CharField(max_length=32)'记得创建好模型类后,执行数据库迁移命令:makemigrations、migrate'
配置路由文件urls.py
from django.conf.urls import urlfrom django.contrib import adminfrom app import viewsurlpatterns = [url(r'^admin/', admin.site.urls),url(r'^info/', views.info),]
tests.py 制作我们待会进行分页的数据,并将其写入数据库内
import osif __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "nine.settings")import djangodjango.setup()from app import modelsfrom faker import Faker # 生成加的数据import random # 用来创建随机年龄obj_list = []for i in range(300): # 制作300条虚拟数据fake = Faker(locale='zh-CN') # 选择地区name = fake.name() # 生成随机名称age = random.randint(18,55) # 生成随机年龄address = fake.address() # 生成随机地址info_obj = models.UserInfo(name=name,age=age,address=address) # 生成一个个用户对象obj_list.append(info_obj)models.UserInfo.objects.bulk_create(obj_list) # 将一个个对象写入数据库内保存,一个对象对应一条记录
这里用到了一个Python第三方模块
faker,主要是生成各种各样的伪数据。具体使用自行搜索引擎查找。
views.py:先简单的搭建出模型,在web能看到数据效果
def info(request):info_list = models.UserInfo.objects.all() # 获取所有的数据all_count = info_list.count() # 通过计数获取有多少条数据per_page_num = 10 # 自定义每一页展示的数据条数,这个时候就可以动态计算了all_page_num,more = divmod(all_count,per_page_num) # divmod计算需要多少页来展示if more:all_page_num += 1 # 这样就获取到了所有的页码的数量current_page = request.GET.get('page',1) #获取用户指定的page,如果没有则默认展示第一页try:current_page = int(current_page) # 因为返回给前端的是字符串要转换成整型except ValueError: # 抛出异常类型错误current_page = 1html_str = ''xxx = current_pageif current_page < 6: # 一用户访问的页码小于6就等于6xxx = 6for i in range(xxx-5,xxx+6):if current_page == i:html_str += '<li class="active"><a href="?page=%s">%s</a></li>' % (i,i)else:html_str += '<li><a href="?page=%s">%s</a></li>' % (i,i)start_page = (current_page-1)*per_page_num # 定义出切片的起始位置end_page = current_page*per_page_num # 定义出切片的终止位置info_query = models.UserInfo.objects.all()[start_page:end_page]'''all返回的是QuerySet,可以看成列表套对象,也就是说支持索引取值现在的问题总可能让客户用源码修改页数吧?'''return render(request, 'info.html', locals())
info.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title><script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.7.1/jquery.min.js"></script><link href="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/3.4.1/css/bootstrap.min.css" rel="stylesheet"><script src="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/3.4.1/js/bootstrap.min.js"></script>
</head>
<body>
<div class="container"><div class="row"><div class="col-md-8 col-md-offset-2"><table class="table table-striped"><thead><tr><th class="text-center">ID</th><th class="text-center">姓名</th><th class="text-center">年龄</th><th class="text-center">住址</th></tr></thead><tbody>{% for info in info_query %}<tr class="text-center"><td>{{ info.id }}</td><td>{{ info.name }}</td><td>{{ info.age }}</td><td>{{ info.address }}</td></tr>{% endfor %}</tbody></table></div><nav aria-label="Page navigation" class="text-center"><ul class="pagination"><li><a href="#" aria-label="Previous"><span aria-hidden="true">«</span></a></li>{{ html_str | safe }}<li><a href="#" aria-label="Next"><span aria-hidden="true">»</span></a></li></ul></nav></div>
</div>
</body>
</html>
最终效果:
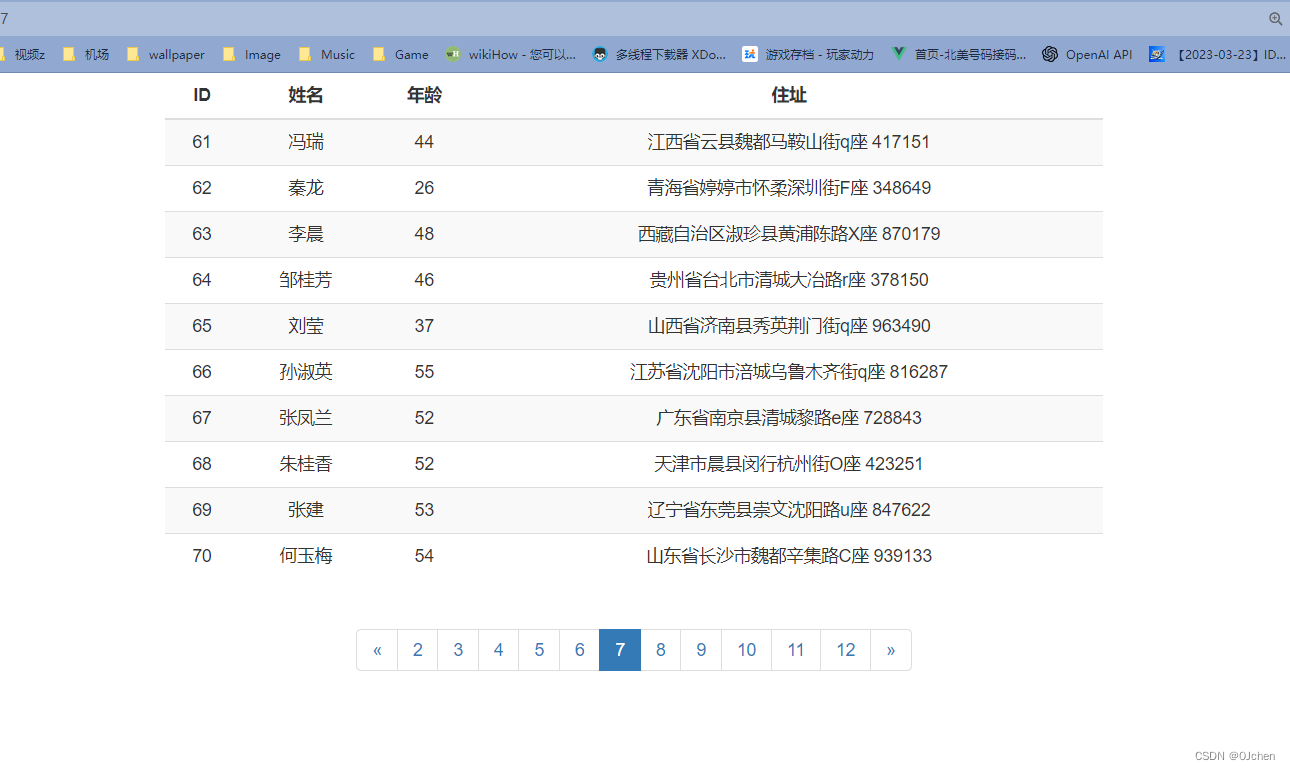
3.自定义分页器
是我们自己写好的分页器代码
一般是存在应用层.utils.mypage文件下的,我们需要的时候导入就行
class Pagination(object):def __init__(self, current_page, all_count, per_page_num=2, pager_count=11):"""封装分页相关数据:param current_page: 当前页:param all_count: 数据库中的数据总条数:param per_page_num: 每页显示的数据条数:param pager_count: 最多显示的页码个数"""try:current_page = int(current_page)except Exception as e:current_page = 1if current_page < 1:current_page = 1self.current_page = current_pageself.all_count = all_countself.per_page_num = per_page_num# 总页码all_pager, tmp = divmod(all_count, per_page_num)if tmp:all_pager += 1self.all_pager = all_pagerself.pager_count = pager_countself.pager_count_half = int((pager_count - 1) / 2)@propertydef start(self):return (self.current_page - 1) * self.per_page_num@propertydef end(self):return self.current_page * self.per_page_numdef page_html(self):# 如果总页码 < 11个:if self.all_pager <= self.pager_count:pager_start = 1pager_end = self.all_pager + 1# 总页码 > 11else:# 当前页如果<=页面上最多显示11/2个页码if self.current_page <= self.pager_count_half:pager_start = 1pager_end = self.pager_count + 1# 当前页大于5else:# 页码翻到最后if (self.current_page + self.pager_count_half) > self.all_pager:pager_end = self.all_pager + 1pager_start = self.all_pager - self.pager_count + 1else:pager_start = self.current_page - self.pager_count_halfpager_end = self.current_page + self.pager_count_half + 1page_html_list = []# 添加前面的nav和ul标签page_html_list.append('''<nav aria-label='Page navigation>'<ul class='pagination'>''')first_page = '<li><a href="?page=%s">首页</a></li>' % (1)page_html_list.append(first_page)if self.current_page <= 1:prev_page = '<li class="disabled"><a href="#">上一页</a></li>'else:prev_page = '<li><a href="?page=%s">上一页</a></li>' % (self.current_page - 1,)page_html_list.append(prev_page)for i in range(pager_start, pager_end):if i == self.current_page:temp = '<li class="active"><a href="?page=%s">%s</a></li>' % (i, i,)else:temp = '<li><a href="?page=%s">%s</a></li>' % (i, i,)page_html_list.append(temp)if self.current_page >= self.all_pager:next_page = '<li class="disabled"><a href="#">下一页</a></li>'else:next_page = '<li><a href="?page=%s">下一页</a></li>' % (self.current_page + 1,)page_html_list.append(next_page)last_page = '<li><a href="?page=%s">尾页</a></li>' % (self.all_pager,)page_html_list.append(last_page)# 尾部添加标签page_html_list.append('''</nav></ul>''')return ''.join(page_html_list)
自定义分页器的使用
django自带分页器模块但是使用起来很麻烦 所以我们自己封装了一个只需要掌握使用方式即可后端def info(request):info_list = models.UserInfo.objects.all()from app.utils.my_page import Pagination # 导入current_page = request.GET.get('page') # 获取当前页page_obj = Pagination(current_page=current_page,all_count=info_list.count(),per_page_num=10) # 生成对象info_query = info_list[page_obj.start:page_obj.end] # 切片html = page_obj.page_htmlreturn render(request,'info.html',locals())
前端
<div class="container"><div class="row"><div class="col-md-8 col-md-offset-2"><table class="table table-striped"><thead><tr><th class="text-center">ID</th><th class="text-center">姓名</th><th class="text-center">年龄</th><th class="text-center">住址</th></tr></thead><tbody>{% for info in info_query %}<tr class="text-center"><td>{{ info.id }}</td><td>{{ info.name }}</td><td>{{ info.age }}</td><td>{{ info.address }}</td></tr>{% endfor %}</tbody></table>{{ html | safe }}</div></div></div>
最终结果:
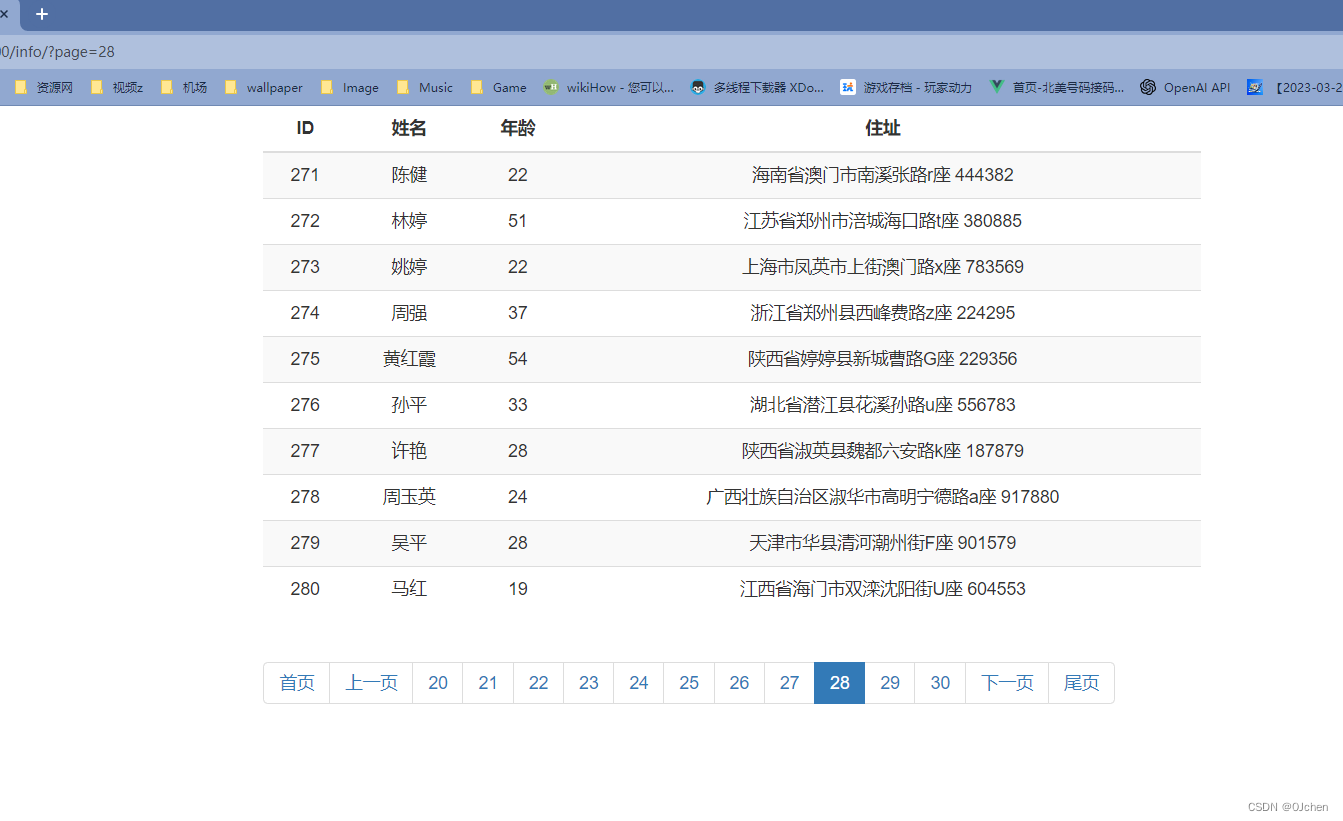
)


















 — Informer源码详解与运行)