目录
一、 学习目标
二、 磁盘结构
三、块设备内核组件
四、块设备驱动核心数据结构和函数
五、块设备驱动实例
六、 习题
一、 学习目标
块设备驱动是 Linux 的第二大类驱动,和前面的字符设备驱动有较大的差异。要想充分理解块设备驱动,需要对系统的各层都有所了解。本文以完成一个虚拟磁盘驱动为目的,依次介绍了磁盘结构、块设备相关的内核组件、块设备驱动所涉及的核心数据结构和函数接口,并在此基础之上用两种方法实现了虚拟磁盘的驱动。
二、 磁盘结构
作为一个 Linux 块设备驱动开发者,虽然可以不必太关心块设备硬件及机械上的实现细节就能够写出块设备驱动,但是如果了解一些块设备硬件及机械上的基本概念,还是有助于对整个子系统的理解的。在块设备中,最具典型意义的设备就是磁盘,一个磁盘的内部构造如下图所示。

主轴被伺服电机带动,在磁盘的读写过程中,盘片会高速旋转。盘片上涂覆了磁性介质,可以被磁化,通过磁化的极性不同来记录二进制的0或 1。磁化和磁感应的部件是盛头,它被固定在磁头传动臂上面,磁头传动臂在磁头传动轴的带动下进行摆动,从而使磁头位于盘片不同的半径位置。为了提高磁盘的存储容量,一个磁盘内部通常是由多个盘片重叠在一起的,并且盘片的反面也有磁头,它的内部立体示意图如下图所示.

盘片在旋转的过程中,磁头 (Head)在盘片上的轨迹构成一个磁道 (Trak),不同的盘片上同半径的磁道构成柱面(Cylinder),将一个磁道划分成多个小的扇形区域叫作扇区 (Sector)。于是一个磁盘的容量可以通过下面的公式来计算:
磁盘容量 = 磁头数 x 柱面数 x 每磁道扇区数 x 每扇区字节数
用 fdisk 命令格式化一个磁盘时通常会看到如下的信息 (这是一个 2GB 的U盘)
Disk /dev/sdb:1977 MB,1977614336 bytes61 heads,62 sectors/track,1021 cylinders, total 3862528 sectorsUnits = sectors of 1 * 512 = 512 bytesSector size (logical/physical): 512 bytes / 512 bytes
它表示该磁盘有 61 个磁头,1021 个柱面,每个磁道被划分为 62 个扇区,扇区的大小在逻辑上和在物理上都是 512 个字节,于是磁盘总的扇区数为:
61 x 1021 x 62=3861442
但是代码中显示总扇区为 3862528,多出了 1086 个扇区,这是怎么回事呢?原来,扇区在使用的过程中会损坏,多出的扇区用于替换那些坏掉的扇区,这部分多出的扇区叫作再分配扇区。当再分配扇区使用过多时,说明磁盘的扇区损坏率已经比较高了,应更换磁盘。另外,代码中的磁头数、柱面数等都是逻辑上的概念了。按照这个扇区计算的容量就和显示的相符了。
三、块设备内核组件
当用户层发起对硬盘的访问操作时,将会涉及下图中的一些内核组件,现在将各个组件的大概作用描述如下。
VFS (Virtual File System,虚拟文件系统):为应用程序提供统一的文件访问接口,屏蔽了各个具体文件系统的操作细节,是对所有文件系统的一个抽象。
Disk Caches: 硬盘高速缓存,用于缓存最近访问的文件数据,如果能在高速缓存中找到,就不必去访问硬盘,毕竟硬盘的访问速度要慢很多。
Disk Filesystem:文件系统,属于映射层(Mapping Layer)。在应用程序开发者的眼一个文件是线性存储的,但实际上它们很有可能是分散存放在硬盘的不同扇区上的.中,文件系统最主要的作用就是要把对文件从某个位置开始的若干个字节访问转换为对磁盘上某些扇区的访问。它是文件在应用层的逻辑视图到磁盘上的物理视图的一个映射。
Generic Block Layer: 通用块层,用于启动具体的块 IO 操作的层。它是对具体硬盘设备的抽象,使得内核的上层不用关心磁盘硬件上的细节信息。
I/O Scheduler Layer: I/O 调度层,负责将通用块层的块 IO 操作进行调度、排序和合并操作,使对硬盘的访问更高效。这在后面还会进一步进行说明。
Block Device Driver: 块设备驱动,也就是块设备驱动开发者写的驱动程序,是我们接下来讨论的话题。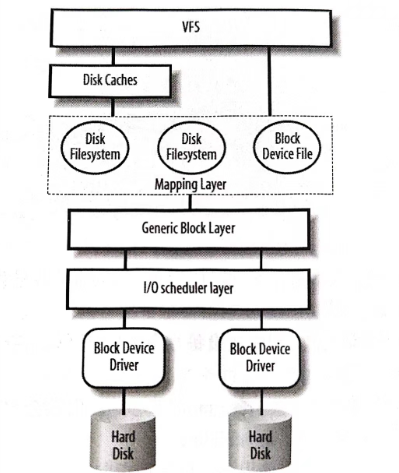
四、块设备驱动核心数据结构和函数
下面讨论的数据结构和函数都是针对 3.14 版本的内核源码而言的,低于这个版本的源码有些定义和用法不一样,当然高于这个版本的也可能会有一些新的变化(这是因为块设备子系统还在活跃地变化过程中)。
和字符设备一样,块设备也有主次设备号,只是次设备号对应的是块设备的不同分区。相关的函数如下。
int register_blkdev(unsigned int major, const char *name);
void unregister_blkdev(unsigned int major, const char *name);
register_blkdev:名字虽然是注册块设备,但实际上是注册主设备号。major 是要注册的主设备号,取值为1~255,如果为0则表示让内核分配一个空闲的主设备号。name 是和这个号绑定的名字,在整个系统中是唯一的。返回值分两种情况,如果 major 参数是255 之间的数,那么返回0表示成功,返回负数表示失败。如果 major 是 0,则返回的正数是分配得到的主设备号,返回负数表示失败。
unregister blkdev: 注销已注册的主设备号 major。
由于块设备的内核的其他组件完成了很多功能,所以块设备驱动基本不需要关心像struct block_device 这样的结构了。驱动开发者更关心的是一个硬盘的整体抽象,内核用struct gendisk 结构来表示,其中需要驱动开发者初始化的成员如下。
struct gendisk {int major;int first_minor;int minors;char disk_name[DISK_NAME_LEN];const struct block_device_operations *fops;struct request_queue *queue;void *private_data;
......
};
major:主设备号,赋值为注册成功的主设备号。
first_minor:第一个次设备号,通常赋值为 0,磁盘的设备号为注册的主设备号和0,其他分区的次设备号逐个递增。
minors: 次设备号的最大值,因为次设备号通常从0开始,所以也表示块设备最大的分区数。该值被设定后不能再修改。
disk_name: 块设备的名字,如 sda、mmcblk0 等。内核会自动在该名字后追加次设备号作为次设备的名字,如 sda1、mmcblk0p1 等。
private_data: 块设备驱动可以使用该成员保存指向其内部数据的指针。
queue: 请求队列,这个会在后面详细介绍。
fops: 块设备的操作方法集,和字符设备驱动一样,该结构中是一些函数指针,主要成员如下。
struct block_device_operations {int (*open) (struct block_device *, fmode_t);void (*release) (struct gendisk *, fmode_t);int (*ioctl) (struct block_device *, fmode_t, unsigned, unsigned long);int (*media_changed) (struct gendisk *);int (*revalidate_disk) (struct gendisk *);int (*getgeo)(struct block_device *,struct hd_geometry *);
......
};
open; 打开块设备时调用,比如用于开始旋转光盘,准备之后的读写操作
release:关闭块设备时调用。
ioctl: 用于完成一些控制操作,但是对块设备的控制很大一部分都被上层的内核组件先截获并处理了,所以在块设备驱动中该函数几乎什么都不用做。
media_changed;用于检测可移动设备的介质是否被更换,如果更换了返回一个非 0值。如果不是可移动设备,该函数不用实现。
revalidate_disk;当介质被更换时,上层内核组件调用该函数,使驱动有机会对设备重新进行一些初始化操作。
getgeo: 向上层返回一些块设备的几何结构信息,如磁头数、柱面数、总的扇区数等
格式化的软件会用到这些参数,如前面提到的 fdisk。和字符设备不同的是,在操作方法集合中并没有包含与读、写相关的操作,实际上这些操作是通过请求队列和与之绑定的请求处理函数来完成的,后面我们会详细谈到这一点。
围绕 struct gendisk 结构,主要有下面一些函数。
struct gendisk *alloc_disk(int minors);
void add_disk(struct gendisk *disk);
void del_gendisk(struct gendisk *disk);
struct kobject *get_disk(struct gendisk *disk);
void put_disk(struct gendisk *disk);
void set_capacity(struct gendisk *disk, sector_t size);
sector_t get_capacity(struct gendisk *disk);
alloc_disk:动态分配一个 struct gendisk 结构对象,返回对象的地址,NULL 表示失败。minors 表示最大分区数。该函数还负责初始化 struct gendisk 结构对象内的部分成员应该使用该函数来获取 struct gendisk 结构对象。
add_disk: 添加 disk 到内核中,在 disk 完全初始化完成并能处理块 IO 操作之前,不能调用该函数,因为在该函数的执行过程中,上层的内核组件就会对块设备发起访问,比如获取块设备上的分区信息。
del_gendisk:从内核中删除 disk。
get_disk:增加 disk 的引用计数。
put_disk:减少 disk 的引用计数。
set_capacity:以 512 字节为一扇区进行计数,设置块设备用扇区数表示的容量。如果块设备的物理扇区不是 512 字节,也必须按照 512 字节为一扇区来设定容量。
get_capacity:获取块设备的总扇区数。
最后来讨论块设备驱动中最重要的部分一一块 I/O 操作。一个块 I/O 操作就是从块设备上读取若干个块数据到缓冲区中,或将缓冲区中的若干个块数据写入到块设备。块最小为块设备扇区大小,最大为一页内存,但必须是扇区大小的整数倍,所以常见的块大小为 512字节、1024 字节、2048 字节和 4096 字节。前面我们说过,当块设备的上层内该组件决定要对块设备进行访问时,将会启动块 I/O 操作。在正常情况下,这个操作由submit_bio 函数发起,其中涉及一个重要的数据结构struct bio。先不看这个结构的定,直觉上,这个结构应该包含一次块I /O 操作的一些信息:起始区号、扇区数量 (或字节数)、读写方式和缓冲区。因为只有具备这些信息,我们才能完成一次 I/O 操作。不过实际上这个结构要更复杂一些,其定义如下。
struct bio {struct bio *bi_next;struct block_device *bi_bdev;unsigned long bi_flags;unsigned long bi_rw;struct bvec_iter bi iter;unsigned int bi_phys_segments;unsigned int bi_seg_front_size;unsigned int bi_seg_back_size;atomic_t bi_remaining;bio_end_io_t *bi_end_io;void *bi_private;unsigned short bi_vcnt;unsigned short bi_max_vecs;atomic_t bi_cnt;struct bio_vec *bi_io_vec;struct bio_set *bi_pool;struct bio_vec bi_inline_vecs[0];
};
bi_next: 指向下一个 struct bio 结构对象,用于将提交的 bio(块I/O 结构对象,以后都简称 bio) 形成一个链表。
bi_bdev: bio 的目标块设备对象指针,在该块设备上完成块 IO 操作。
bi_flags:一些状态和命令的标志。
bi_rw:读写标志。
bi_iter:用于遍历bvec 的选代器。
bi_phys_segments、bi_seg_front_size、bi_seg_back_size:用于合并操作的成员。
bi_remaining、bi_cnt:与 bio 相关的引用计数。
bi_end_io:完成块IO 操作后的回调函数指针。
bi_private:通常用于指向父 bio。
bi_vcnt: 该 bio 所包含的 bio_vec 个数
bi_max_vecs:该bio 所包含的最大 bio vec 个数
bi_io_vec:指向 bio_vec 数组首元素的指针。
bi_pool:自定义的 bio和 bio_vec 内存池。
bi_inline_vecs:内的 bio_vec 数组,用在 bio_vec 个数较少时。
上面的内容比较多,涉及的知识点也比较多,驱动开发者应始终重点关注前面提到的四点信息,即起始扇区号、扇区数量 (或字节数)、读写方式和缓冲区。bi_rw 是读写标志,除此之外,好像就没有其他对我们有用的信息了。这确实是一件让人感到沮丧的事,但是细心观察就会发现部分成员是结构成员,再继续查找就会发现,在 bi_iter 中就包含了对应的信息,接下来看看 struct bvec_iter 结构的定义。
struct bvec_iter {sector_t bi_sector;unsigned int bi_size;unsigned int bi_idx;unsigned int bi_bvec_done;
};
bi_sector: 要访问的块设备扇区号,迭代器中遍历的第一个 bio_vec 元素的扇区号就是起始扇区号。
bi_size、bi_bve_done: 未完成和已完成的字节数。
bi_idx:当前处理的 bio_vec 在数组中的下标。
从上面的信息中我们知道,要访问的块设备扇区号在迭代器的 bi_sector 成员中,用这个选代器可以遍历 bio 中的 bi_io_vec 数组的每一个元素。我们还有两个重要的信息没有找到,那就是扇区数量(或字节数) 和缓冲区,显然这些信息应该放在 bio_vec 中,该第结构的定义如下。
struct bio_vec {struct page *bv_page;unsigned int bv_len;unsigned int bv_offset;
};
bv_page: 缓冲区所在的物理内存页的管理对象指针
bv_len:该 bio vec 要完成的块操作字节数。
bv_offset: 缓冲区在物理内存页中的偏移。
说了那么多,其实它们之间的关系可以通过下图来展示
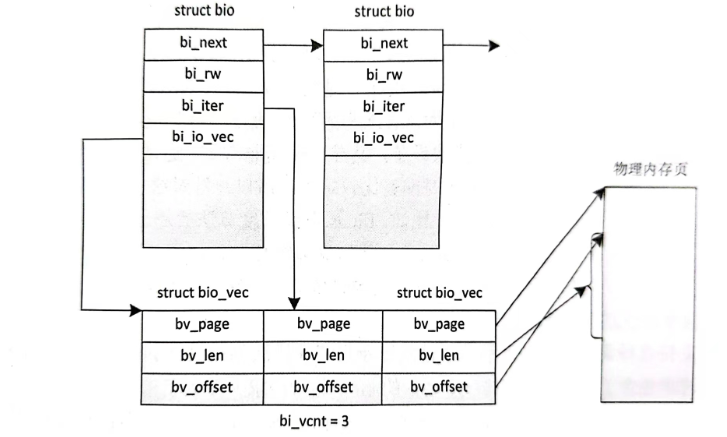
一个块 I/O 操作用一个 struct bio 结来表示,上层递交的块 I/O 操作可以放在一个链表中,用 bi_next 指针来链接。bi_rw 用来说明本次块 I/O 操作是还是写,bi_io_vec 指向了一个 struct bio_vec 结构对象数组中的首元素,在 struct bio_vec 结构中,bv_page描述了用于块 I/O 操作的缓冲区所在的物理内存页,by_len 表示该 bio_vec 要读写的字节,bv_offset 是缓冲区在所在物理内存页中的偏。一个 bio 由b个 bio_vec 来组没,要完成一个块I /O操作,就要历 bio 中的每一个 bio _vec。可以使用代器 bi_iter进行遍历,它描述了正森进行的 bio_vec,初始时,bi_iter 达代器对应第一个 bio_vec。
和bio相关的主要函数和宏如下。
bio data_dir(bio)
bio_for_each_segment (bvl, bio, iter)
bio_kmap_atomic(bio, iter)
bio_kunmap_atomic(addr)
void bio_endio(struct bio *bio, int error);
bio_data_dir: 获取本次块 I/O 操作的读写方向,在同一个 bio 中的 bio_vec 的读写都是一致的,要么全是读,要么全是写。
bio_for_each_segment: 用迭代器 iter 遍历 bio 中的每一个 bio_vec,得到的 bio_vec是bvl
__bio_kmap_atomic:将选代器 iter 对应的 bio_vec 中的物理页面映射,支持高端内存。返回的是映射后再加上 bv_offset 偏移的虚拟地址。
__bio_kunmap_atomic:解除前面的映射。
bio_endio: 结束一个 bio,error 为 0 表示 bio 正常结束,否则是其他错误码,比如-EIO
一个块 IO 操作之所以要用这么复杂的形式来表示,一是便于分散/聚集 IO 的操作,也可以利用分散/聚集 DMA 来进行数据传输。二是映射的方式可以使它既能处理普通内存,也能处理高端内存。
当块设备的上层内核组件启动了块 IO 操作后,bio 可以由 IO 调度器来进行合理的调度,从而提高IO 效率。举个例子来说,当随后提交的 bio 访问的扇区和前一个 bio 访问的扇区相邻,并且访问方式相同(都为读,或都为写),那么 I/O 调度器就可以将这两个 bio 进行合并。另外,对于磁盘这类块设备,其寻道时间非常长,通常在毫秒级,但一旦磁头移动到对应的磁道上,访问的时间就比较短了。所以,针对这一类块设备,I/O调度器可以通过 bio 的顺序来提高效率。比如,Linus 电梯调度算法就是让磁盘上的块 I/O操作排序为让磁头单向往主轴方向移动或单向往磁盘边缘移动,这样就可以有效减少寻道时间。不过,对于固态硬盘、U 盘和 SD 卡这类设备而言,这种调度又是多余的,因为它们访问哪个扇区的时间都一样。
为了支持这种调度,内核又引入了请求以及将请求排队的请求队列的概念。简单来说,一个请求包含了多个合并和排序了之后的 bio,每个请求又放入了请求队列中。在内核中,请求是用 struct request 结构来表示的,该结构的成员非常多,下面仅列出对理解驱动开发有帮助的几个成员。
struct request { struct list_head queuelist;struct request_queue *q;struct bio *bio;struct bio *biotail;
};
queuelist; 链表成员,用于将多个请求组织成一个链表。
q:当前请求属于的请求队列。
bio: 请求中包含的第一个 bio 对象。
biotail: 请求中包含的最后一个 bio 对象。
请求队列是用 request_queue 结构来表示的,最主要的成员如下所示。
struct request_queue {struct list_head queue_head;request_fn_proc *request_fn;make_request_fn *make_request_fn;
};
queue_head:请求队列的链表头。
request_m: 指向由块设备驱动开发者提供的请求处理函数。采用这种方式内核会把块IO 请求 (bio)首先经过排序、合并等手段来形成请求 (struct request),然后再把求放入到请求队列中,最后调用块设备驱动开发者提供的由该函数指针指向的请求处理函数来处理这个队列中的请求。
make_request_fn:指向用于构造请求的函数(将 bio 排序、合并的函数),该函数以由内核提供默认的请求构造函数,那么驱动开发者就应该提供请求处理函数来处理请求,这通常用于磁盘这类设备。还可以由驱动开发者来实现一个用于构造请求的函数,然后该指针指向这个函数,这通常适用对 bio 的排序和合并操作有特殊要求的设备,或者根本不需要将 bio 排序和合并的设备 驱动开发者也就不需要提供请求处理函数了),如固态硬盘、U 盘和 SD 卡等。
围绕请求和请求队列有如下常用的宏或函数。
struct request_queue *blk_alloc_queue(gfp_t gfp_mask);
void blk_queue_make_request (struct request_queue *q,make_request_fn *mfn);
struct request_queue *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock);
blk_queue_logical_block_size(struct request_queue *q,unsigned short size);
void blk_cleanup_queue(struct request_queue *q);
struct request *blk_fetch_request(struct request_queue *q);
__rq_for_each_bio( bio, rq);
bool __blk_end_request_cur(struct request *rq, int error);
blk_alloc queue: 分配一个请求队列。
blk_queue_make requet: 为请求队列q 指定请求构造函数 mfn
blk_init_queue:分配并初始化一个请求队列,由内核提供默认的请求构造函数,请求处理函数为rfn,因为内核和驱动都要使用队列,所以内核在调用整动提供的请求处理员数前首先要获得 lock自旋锁,这防止了在请求处理的过程中内为块设备安排其他的请求。但这也使得请求处理涵数在原子上下文,带来了之前讨论自旋锁时引入的编程限制,当然也可以先释放锁,在非原子上下文中完成这些在原子上下文中受限的操作,然再获取自旋锁。不过在自旋锁释放期间,不能访问请求队列
通常情况下,blk_alloc_queue 和 blk_queue_make_request 是联合使用的,表示不使用内核提供的默认请求构造函数,而是使用驱动提供的请求构造函数, 而这种情况往往又不需要构造请求, 直接在请求构造函数中处理 bio即可, 所以请求队列完成了一种形式。
blk_queue_logical_block_size; 设逻辑扇区的大小,应该设置成块设备能访问的最小数据块大小。绝大多数的设备都是 512 字节。
blk_cleanup_queue;清空并销毁队列
blk_fetch_request: 取出队列中最顶端的请求。
__blk_end_request_cur: 以状态 error 完成一个请求,并更新请求。如请求都完成则返回假,否则返回真。
五、块设备驱动实例
下面分别展示直接处理 bio 和使用请求队列来实现的两种块设备驱动实例(这些代码都基于 Linux-3.14.25 内核源码)。块设备用一片 8MB 字节的内存来模拟,这和内核中的ramdisk 之类的块设备驱动类似,但是更简化。首先介绍直接处理 bio 的驱动代码
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>#include <linux/fs.h>
#include <linux/slab.h>
#include <linux/genhd.h>
#include <linux/blkdev.h>
#include <linux/hdreg.h>
#include <linux/vmalloc.h>#define VDSK_MINORS 4
#define VDSK_HEADS 4
#define VDSK_SECTORS 16
#define VDSK_CYLINDERS 256
#define VDSK_SECTOR_SIZE 512
#define VDSK_SECTOR_TOTAL (VDSK_HEADS * VDSK_SECTORS * VDSK_CYLINDERS)
#define VDSK_SIZE (VDSK_SECTOR_TOTAL * VDSK_SECTOR_SIZE)static int vdsk_major = 0;
static char vdsk_name[] = "vdsk";struct vdsk_dev
{u8 *data;int size;spinlock_t lock;struct gendisk *gd;struct request_queue *queue;
};struct vdsk_dev *vdsk = NULL;static int vdsk_open(struct block_device *bdev, fmode_t mode)
{return 0;
}static void vdsk_release(struct gendisk *gd, fmode_t mode)
{
}static int vdsk_ioctl(struct block_device *bdev, fmode_t mode, unsigned cmd, unsigned long arg)
{return 0;
}static int vdsk_getgeo(struct block_device *bdev, struct hd_geometry *geo)
{geo->cylinders = VDSK_CYLINDERS;geo->heads = VDSK_HEADS;geo->sectors = VDSK_SECTORS;geo->start = 0;return 0;
}static void vdsk_make_request(struct request_queue *q, struct bio *bio)
{struct vdsk_dev *vdsk;struct bio_vec bvec;struct bvec_iter iter;unsigned long offset;unsigned long nbytes;char *buffer;vdsk = q->queuedata;bio_for_each_segment(bvec, bio, iter) {buffer = __bio_kmap_atomic(bio, iter);offset = iter.bi_sector * VDSK_SECTOR_SIZE;nbytes = bvec.bv_len;if ((offset + nbytes) > get_capacity(vdsk->gd) * VDSK_SECTOR_SIZE) {bio_endio(bio, -EINVAL);return;}if (bio_data_dir(bio) == WRITE)memcpy(vdsk->data + offset, buffer, nbytes);elsememcpy(buffer, vdsk->data + offset, nbytes);__bio_kunmap_atomic(bio);}bio_endio(bio, 0);
}static struct block_device_operations vdsk_fops = {.owner = THIS_MODULE,.open = vdsk_open,.release = vdsk_release,.ioctl = vdsk_ioctl,.getgeo = vdsk_getgeo,
};static int __init vdsk_init(void)
{vdsk_major = register_blkdev(vdsk_major, vdsk_name);if (vdsk_major <= 0)return -EBUSY;vdsk = kzalloc(sizeof(struct vdsk_dev), GFP_KERNEL);if (!vdsk)goto unreg_dev;vdsk->size = VDSK_SIZE;vdsk->data = vmalloc(vdsk->size);if (!vdsk->data)goto free_dev;spin_lock_init(&vdsk->lock);vdsk->queue = blk_alloc_queue(GFP_KERNEL);if (vdsk->queue == NULL)goto free_data;blk_queue_make_request(vdsk->queue, vdsk_make_request);blk_queue_logical_block_size(vdsk->queue, VDSK_SECTOR_SIZE);vdsk->queue->queuedata = vdsk;vdsk->gd = alloc_disk(VDSK_MINORS);if (!vdsk->gd)goto free_queue;vdsk->gd->major = vdsk_major;vdsk->gd->first_minor = 0;vdsk->gd->fops = &vdsk_fops;vdsk->gd->queue = vdsk->queue;vdsk->gd->private_data = vdsk;snprintf(vdsk->gd->disk_name, 32, "vdsk%c", 'a');set_capacity(vdsk->gd, VDSK_SECTOR_TOTAL);add_disk(vdsk->gd);return 0;free_queue:blk_cleanup_queue(vdsk->queue);
free_data:vfree(vdsk->data);
free_dev:kfree(vdsk);
unreg_dev:unregister_blkdev(vdsk_major, vdsk_name);return -ENOMEM;
}static void __exit vdsk_exit(void)
{del_gendisk(vdsk->gd);put_disk(vdsk->gd);blk_cleanup_queue(vdsk->queue);vfree(vdsk->data);kfree(vdsk);unregister_blkdev(vdsk_major, vdsk_name);
}module_init(vdsk_init);
module_exit(vdsk_exit);MODULE_LICENSE("GPL");
MODULE_AUTHOR("name <e-mail>");
MODULE_DESCRIPTION("This is an example for Linux block device driver");
代码第 12 行至第 18 行定义了关于虚拟磁盘的一些几何信息,包括最大分区数、磁头数、柱面数、每个扇区字节数和计算得到的总扇区数和容量。代码第 20 行至第 30行定义了一个代表设备的结构,包含了指向 8MB 字节内存的 data 指针、描述虚拟磁盘大小的 size、描述磁盘的 gendisk 结构对象指针、请求队列 queue 和与之绑定的自旋锁 lock。在 vdsk_init 函数中,首先使用 register_blkdev 注册了主设备号,因为参数 vdsk_major为0,所以内核会分配一个空闲的主设备号。接下来使用 spin_lock_init 初始化了自旋锁该自旋锁其实并没有用到),使用 blk_alloc_queue 分配了一个请求队列,并用blk_queue_make_request 来告诉内核使用驱动提供的 vdsk_make_request 请求构造函数。使用 blk_queue_logical_block_size 设置了逻辑块大小,并将 vdsk 对象指针保存到了请求队列中,方便之后从请求队列中获取该数据。最后使用 alloc_disk 分配了一个gendisk 结构对象,并初始化其中相应的成员。用 set_capacity 设置了磁盘容量后,就用 add_disk 向内核添加了 gendisk。
块设备的操作方法集合 vdsk_fops 指定了 open、release 和 ioctl 函数,因为是虚拟设备,所以在这些函数中并不做具体的事情。vdsk_getgeo 则返回了虚拟磁盘的几何数据。该块设备驱动中最重要的函数是请求构造函数 vdsk_make_request,但正如我们前面所说,在这个函数中并没有构造请求,而是直接去处理了 bio。代码第 68 行使用bio_for_each_segment 宏遍历 bio 中的每一个 bi_vec, 将得到的 bio_vec 中的物理页面使用.__bio_kmap_atomic 进行映射,该函数自动处理缓冲区在页面中的偏移。接下来获取起始扇区号,并将扇区号转换为8MB 内存中的偏移量,后面获取了读写字节数,并判剧操作的范围是否超过了虚拟磁盘的边界。如果没有超过边界,则根据读写方向把数据以虚拟磁盘的内存中复制到缓冲区或将缓冲区的数据复制到虚拟做盘的内存中,复制完成后使用_bio_kunmap_atomic 解除映射。当每一个 bio_vec 都被遍历完之后,使用bio_endio 结束这个块 I/O 请求.
下面是使用请求队列的驱动代码
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>#include <linux/fs.h>
#include <linux/slab.h>
#include <linux/genhd.h>
#include <linux/blkdev.h>
#include <linux/hdreg.h>
#include <linux/vmalloc.h>#define VDSK_MINORS 4
#define VDSK_HEADS 4
#define VDSK_SECTORS 16
#define VDSK_CYLINDERS 256
#define VDSK_SECTOR_SIZE 512
#define VDSK_SECTOR_TOTAL (VDSK_HEADS * VDSK_SECTORS * VDSK_CYLINDERS)
#define VDSK_SIZE (VDSK_SECTOR_TOTAL * VDSK_SECTOR_SIZE)static int vdsk_major = 0;
static char vdsk_name[] = "vdsk";struct vdsk_dev
{int size;u8 *data;spinlock_t lock;struct gendisk *gd;struct request_queue *queue;
};static struct vdsk_dev *vdsk = NULL;static int vdsk_open(struct block_device *bdev, fmode_t mode)
{return 0;
}static void vdsk_release(struct gendisk *gd, fmode_t mode)
{
}static int vdsk_ioctl(struct block_device *bdev, fmode_t mode, unsigned cmd, unsigned long arg)
{return 0;
}static int vdsk_getgeo(struct block_device *bdev, struct hd_geometry *geo)
{geo->cylinders = VDSK_CYLINDERS;geo->heads = VDSK_HEADS;geo->sectors = VDSK_SECTORS;geo->start = 0;return 0;
}static void vdsk_request(struct request_queue *q)
{struct vdsk_dev *vdsk;struct request *req;struct bio *bio;struct bio_vec bvec;struct bvec_iter iter;unsigned long offset;unsigned long nbytes;char *buffer;vdsk = q->queuedata;req = blk_fetch_request(q);while (req != NULL) {__rq_for_each_bio(bio, req) {bio_for_each_segment(bvec, bio, iter) {buffer = __bio_kmap_atomic(bio, iter);offset = iter.bi_sector * VDSK_SECTOR_SIZE;nbytes = bvec.bv_len;if ((offset + nbytes) > get_capacity(vdsk->gd) * VDSK_SECTOR_SIZE)return;if (bio_data_dir(bio) == WRITE)memcpy(vdsk->data + offset, buffer, nbytes);elsememcpy(buffer, vdsk->data + offset, nbytes);__bio_kunmap_atomic(bio);}}if (!__blk_end_request_cur(req, 0))req = blk_fetch_request(q);}
}static struct block_device_operations vdsk_fops = {.owner = THIS_MODULE,.open = vdsk_open,.release = vdsk_release,.ioctl = vdsk_ioctl,.getgeo = vdsk_getgeo,
};static int __init vdsk_init(void)
{vdsk_major = register_blkdev(vdsk_major, vdsk_name);if (vdsk_major <= 0)return -EBUSY;vdsk = kzalloc(sizeof(struct vdsk_dev), GFP_KERNEL);if (!vdsk)goto unreg_dev;vdsk->size = VDSK_SIZE;vdsk->data = vmalloc(vdsk->size);if (!vdsk->data)goto free_dev;spin_lock_init(&vdsk->lock);vdsk->queue = blk_init_queue(vdsk_request, &vdsk->lock);blk_queue_logical_block_size(vdsk->queue, VDSK_SECTOR_SIZE);vdsk->queue->queuedata = vdsk;vdsk->gd = alloc_disk(VDSK_MINORS);if (!vdsk->gd)goto free_data;vdsk->gd->major = vdsk_major;vdsk->gd->first_minor = 0;vdsk->gd->fops = &vdsk_fops;vdsk->gd->queue = vdsk->queue;vdsk->gd->private_data = vdsk;snprintf(vdsk->gd->disk_name, 32, "vdsk%c", 'a');set_capacity(vdsk->gd, VDSK_SECTOR_TOTAL);add_disk(vdsk->gd);return 0;free_data:blk_cleanup_queue(vdsk->queue);vfree(vdsk->data);
free_dev:kfree(vdsk);
unreg_dev:unregister_blkdev(vdsk_major, vdsk_name);return -ENOMEM;
}static void __exit vdsk_exit(void)
{del_gendisk(vdsk->gd);put_disk(vdsk->gd);blk_cleanup_queue(vdsk->queue);vfree(vdsk->data);kfree(vdsk);unregister_blkdev(vdsk_major, vdsk_name);
}module_init(vdsk_init);
module_exit(vdsk_exit);MODULE_LICENSE("GPL");
MODULE_AUTHOR("name <e-mail>");
MODULE_DESCRIPTION("This is an example for Linux block device driver");
代码中大部分内容和直接处理 bio 的代码相同,区别在于两个方面: 第一个是使用
blk_init_queue 来分配并初始化请求队列,这就让内核用默认的请求构造函数来处理块 I/O操作。第二个则是提供了请求队列绑定的请求处理函数 vdsk_request。当 bio 经过 IO 调度器转换成请求,并排队到请求队列后,该函数被调用。
vdsk_request 函数中使用了三层循环来处理请求,最外层是代码第71行的while 循环, 它使用 blk_fetch_request 来取出队列中的每一个请求,并用 blk_end_request_cur 来完成请求。代码第 72 行是中间层的循环,使用 __rq_for_each_bio 从请求中取出每一个 bio。代码第 73 行则是最内层的循环,使用 bio_for_each_segment 从 bio 中取出每一个 bio_vec。对 bio_vec 的处理方法和前面的方法一样。
下面是在目标板上的测试方法,如果在宿主机上测试,那么宿主机内核的版本应该是 3.14。测试的过程是: 加载驱动,对虚拟磁盘进行分区、格式化,挂载分区,创建文件并向文件中写入数据,读出数据,删除文件,取消挂载,卸载驱动。在测试中也可以发现,块设备的设备节点是自动创建的,并不需要用 mknod 命令来创建设备节点,在驱动中我们也没有做特别的处理
win11的串口驱动总是要卸载重装真的恶心


六、 习题
1.块设备驱动中,set_capacity 和 get_capacity 函数是按照 ()为扇区大小的
[A] 设备物理扇区大小[B] 512 字节[D]2048 字节[C] 1024 字节
2.块设备的容量计算公式是 ( )。
[A] 磁头数 X 柱面数 X 每磁道扇区数 X 每扇区字节数
[B] 柱面数 X 每磁道扇区数 X 每扇区字节数
3.要完成一个 bio 请求,需要遍历 ( )。
[A] 该 bio 中的每一个 bvec
[B] 该 bio 中的每一个page
4.要完成一个 request 请求,需要遍历 (
[A] 该 request 中的每一个 bio
[B] 每一个 bio 中的每一个 bvec
答案: B A A AB





)
,检查crl(证书吊销列表))












