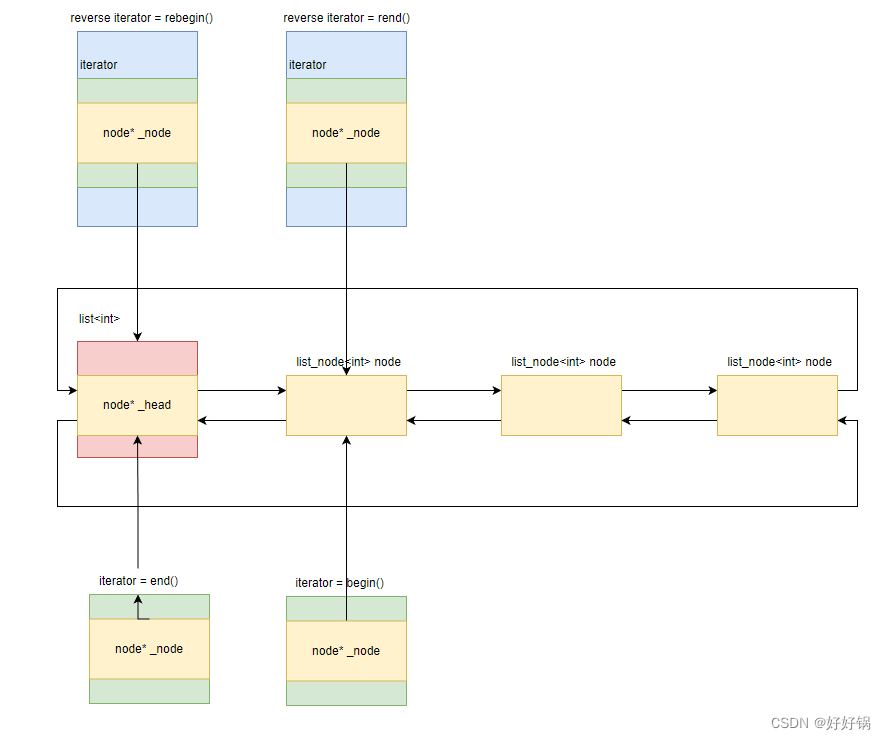
系列实验
深度学习实践——卷积神经网络实践:裂缝识别
深度学习实践——循环神经网络实践
深度学习实践——模型部署优化实践
深度学习实践——模型推理优化练习
代码可见于:
深度学习实践——循环神经网络实践
- 0 概况
- 1 架构实现
- 1.1 RNN架构
- 1.1.1 RNN架构搭建
- 1.1.2 RNN超参数调整
- 1.2 GRU架构
- 1.2.1 GRU架构搭建
- 1.2.2 GRU超参数调整
- 1.3 LSTM架构
- 1.3.1 LSTM架构搭建
- 1.3.2 LSTM超参数调整
- 1.4 三种架构的对比
- 2 序列到序列学习
- 3 实验结论
0 概况
**方法:**实验主要通过python中的pytorch与d2l环境进行,利用了jupyter notebook编写代码。RNN、GRU、LSTM架构的实现基于d2l所提供的教程代码,数据集的使用选择了d2l中的“time machine”数据集。对于基本架构,我选择调整epoch次数、学习率、隐含层神经元数量来寻找更优的结果。除了实现基本的循环神经网络架构外,还学习了seq2seq,并基于d2l教程复现了seq2seq从训练到推理的过程,并尝试调整参数观察变化。
步骤:
- 搭建RNN架构并调整参数以达到较好结果
- 搭建GRU架构并调整参数以达到较好结果
- 搭建LSTM架构并调整参数以达到较好结果
- 实现seq2seq的训练与推理
1 架构实现
1.1 RNN架构
1.1.1 RNN架构搭建
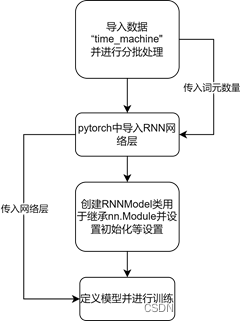
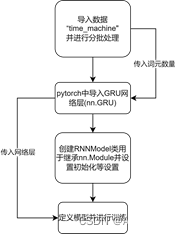
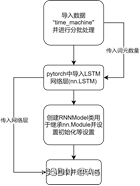
对于RNN架构的实现,我根据教材的指示使用了d2l中的“time machine(时间机器)”数据。此数据集是关于时间机器的一个短篇小说,可以用于进行小批量训练。而对于RNN的代码实现,则是通过pytorch与d2l库实现的。首先是利用d2l的数据加载模块,提供批量数与步长加载出“time machine”的数据。得到数据后,可以利用pytorch中的nn.RNN()来导入RNN神经层。在导入神经层后,构建一个RNNModel的类来继承nn.Module并设置一些训练时的规则与流程。最后定义一个RNNModel对象并传入RNN神经层与数据利用d2l的训练函数进行训练。由于代码较长故报告中不列出,详细代码可见于对应的.ipynb文件。下图为搭建RNN架构时的代码流程图。
初次训练使用的参数epochs次数为500次、学习率为1、隐含层数量256,下面为训练得到的结果。
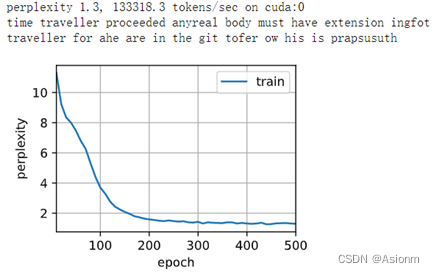
从上面的结果可以看出,在epochs为500,学习率为1时,图像在接近300时收敛,最后困惑度为1.3。从结果的输出可以看出,其语义基本是没有的,但是可以看出输出的单词,接近一半的单词是拥有正确拼写的。这说明了训练是有一定的效果,但是效果并不算太佳。那么下面将进行超参数地调整以达到更好的效果。
1.1.2 RNN超参数调整
以1.1.1中的训练参数作为基础参数,即epochs次数为500次、学习率为1、隐含层数量256,上下调整参数进行比较。
1 epochs次数
这里之所以选择epochs次数进行比较,其原因在于epochs次数对模型结果的收敛和对困惑度的影响十分大。一般来说次数越多那么梯度下降也越多,训练结果也越饱满同样效果会越好,同样也可能次数越多训练会过拟合。而如果次数很小那么效果也可能会非常差,因为训练并不足够。下面选取250、750、1000次进行实验以进行验证比较。(详细代码可见附加的文件,此处只展示结果)
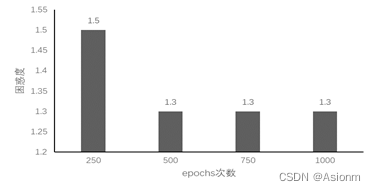
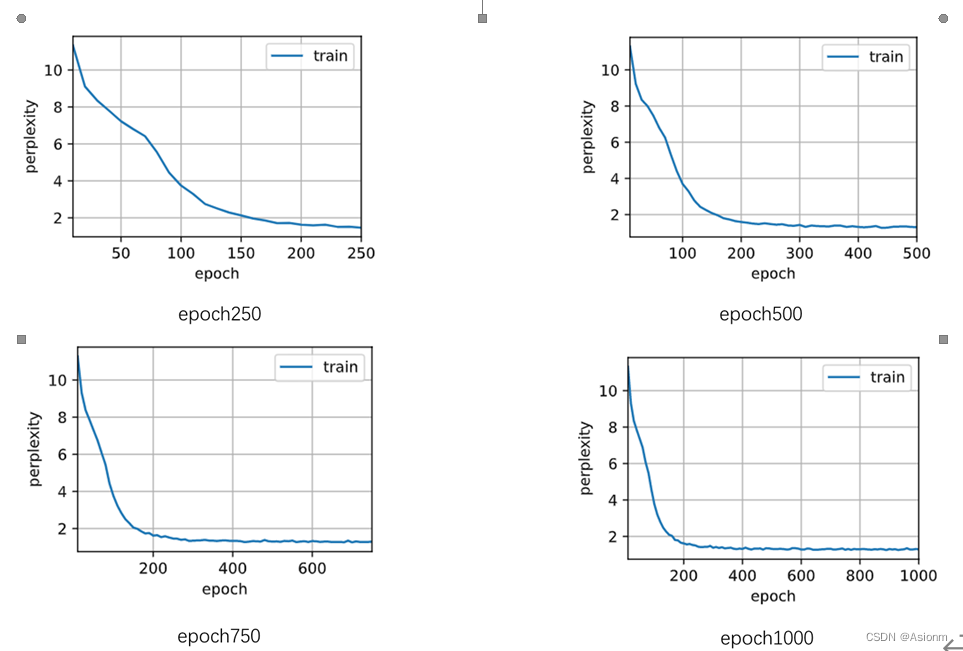
对于“time traveller”的预测:
(1)Epoch250: time traveller held in his hant wald at ifgristtand why had wan
(2)Epoch500: time traveller proceeded anyreal body must have extension ingfot
(3)Epoch750: time traveller came back andfilby seane whyse the lyon at ingte
(4)Epoch1000: time traveller held in whack and hareare redohat de sam e sugod
从结果中可以看出当epoch较小时对模型训练的结果影响是较为显著的,会使得训练的效果较差,但是当epoch到达一定数量时训练的结果基本维持在一定范围内,影响将很小。
2 学习率
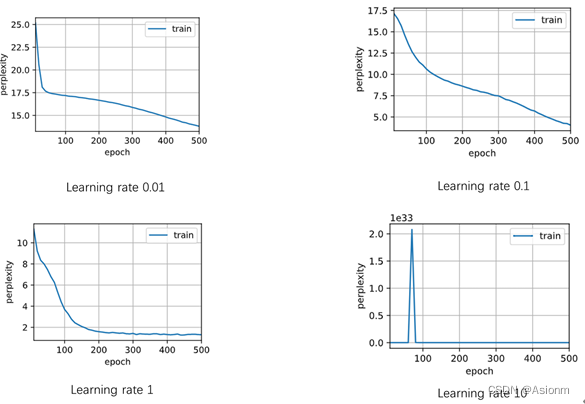
学习率对训练的结果是具有一定的影响的,学习率过大会使得结果的困惑度随着次数的增加每次都很大的不同,十分地混乱,而使得永远得不到较好结果。而如果学习率太低,那么在同样的次数下,其收敛的速度会更慢。下面选取学习率0.01、0.1、10进行实验比较,下面为运行结果。(详细代码可见附加的文件,此处只展示结果)
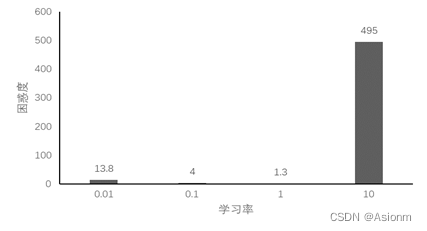
对于“time traveller”的预测:
(1)lr0.01: time traveller the the the the the the the the the the the the t
(2)lr0.1: time traveller thice dimensions al merice time al sicherenre thi
(3)lr1: time traveller proceeded anyreal body must have extension ingfot
(4)lr10: time travellerohc ohc ohc ohc ohc ohc ohc ohc ohc ohc ohc ohc oh
从结果中可以看出当学习率较小时模型的收敛速度会变慢,而其预测的结果中重复出现the也说明结果是很差的,而当学习率为0.1时虽然没有重复出现多个单词但是基本上单词的拼写全是错的。当学习率很大时,其困惑度也十分的大,其出现毫无语义的重复单词。最好的学习率是1在测试的中间,而学习率小时会使得训练地学习收到阻碍,而当学习率太大时会使得学习超过一定值而陷入一个无法寻找更优地循环中。
3 隐藏层神经元数量
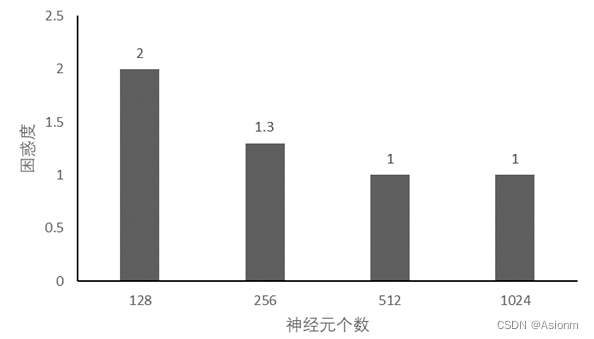
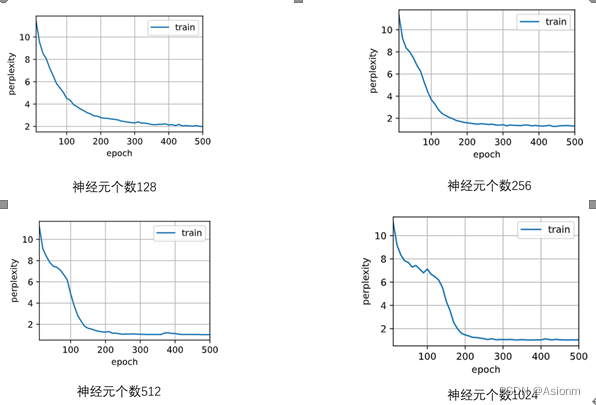
一般来说隐藏层神经元数量越多其拟合的效果会越好,而越少那么其结果可能会很差。因此隐藏层神经元数量是十分关键的,那么选取隐藏层神经元数量为128、512、1024进行比较,下面为运行结果。(详细代码可见附加的文件,此处只展示结果)
对于“time traveller”的预测:
(1)128: time travellerit s againstirad and the time travellerit s all ha
(2)256: time traveller proceeded anyreal body must have extension ingfot
(3)512: time travelleryou can show black is white by argument said filby
(4)1024: time traveller for so it will be convenient to speak of himwas e
从结果中可以看出当神经元个数增加时,其最终的困惑度会减小。其收敛的曲线也会存在一定的变化会存在极速下降的部分。而其预测的结果中神经元个数为512与1024的可以看出存在一定的语义,且拼写也都正确。之所以会这样,我个人认为是神经元个数与拟合效果有关。一般来说神经元个数越多其参数也越多对应的拟合效果一般也会越好。
基于上面的调参可以发现,最好的一组是神经元个数为512与1024的组合,其他的训练效果均差于基础参数。
1.2 GRU架构
1.2.1 GRU架构搭建
对于GRU架构的实现,同样使用了d2l中的“time machine(时间机器)”数据。GRU相对于RNN增加了一些控制单元,就好像电路那样限制了一些内容的输入同时保存了一些重要的内容。架构实现的代码主要参考于d2l,其代码基本与RNN的一致,不同的是改变了神经层。同样layer的调取也是通过pytorch的api,也就是与RNN构建不同的是layer从nn.RNN()变为了nn.GRU()。下面构建的流程图。(详细代码可见于.ipynb文件)
初次训练使用的参数epochs次数为500次、学习率为1、隐含层数量256,下面为训练得到的结果。
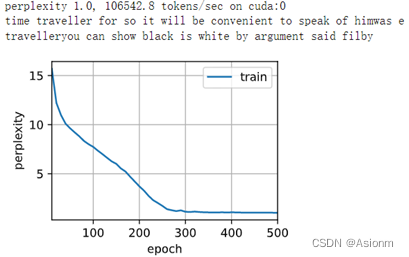
从上面的结果可以看出,在epochs为500,学习率为1时,图像在接近250时收敛,最后困惑度为1。从结果的输出可以看出,其拼写基本正确,且已经拥有一定的语义。这说明了训练是有一定的效果,且与RNN相比其效果更好。
1.2.2 GRU超参数调整
对于GRU超参数的调整基本与RNN的一致,其参数选取理由一致,下面为调参结果
1 epochs次数
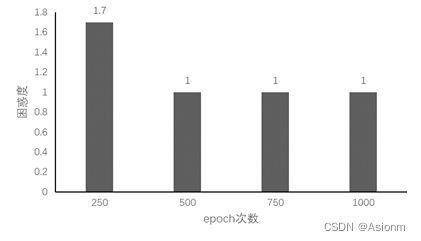
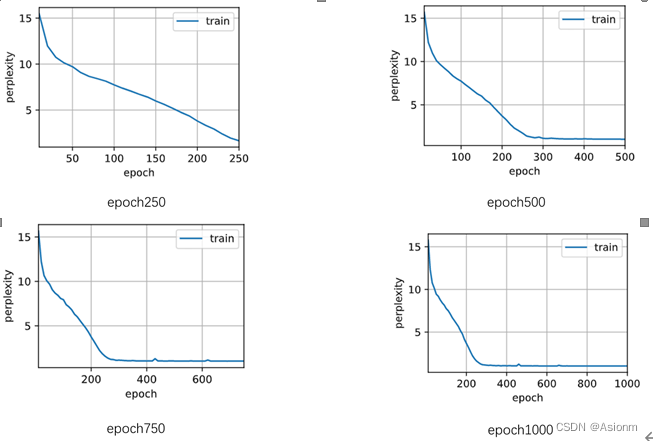
对于“time traveller”的预测:
(1)Epoch250: time travelleris cofr mensthe fourth dimension do net gout the l
(2)Epoch500: time traveller for so it will be convenient to speak of himwas e
(3)Epoch750: time traveller with a slight accession ofcheerfulness really thi
(4)Epoch1000: time traveller with a slight accession ofcheerfulness really thi
可以看出其规律基本与RNN的一致,但是其起点的效果就优于RNN。
2 学习率
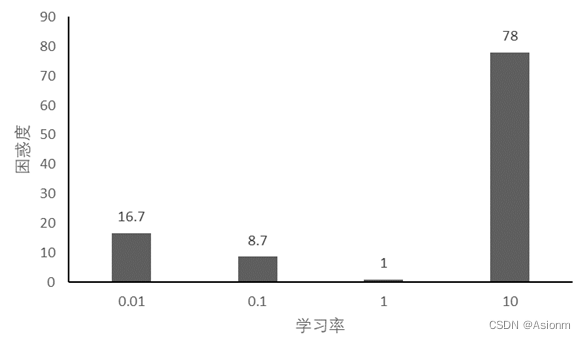
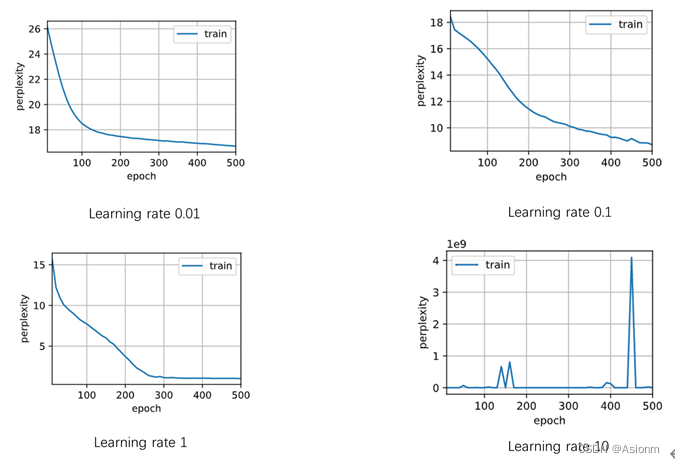
对于“time traveller”的预测:
(1)lr0.01: time traveller t e e t e e t e e t e e t e e t
(2)lr0.1: time travellere the the the the the the the the the the the the
(3)lr1: travelleryou can show black is white by argument said filby
(4)lr10: time travellerohc ohc ohc ohc ohc ohc ohc ohc ohc ohc ohc ohc oh
此结果基本与RNN的一致,不同点在于困惑度的大小。
3 隐藏层神经元数量
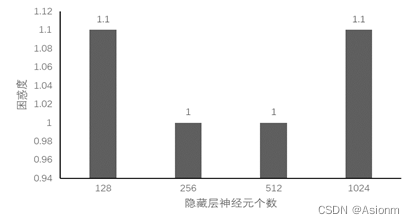
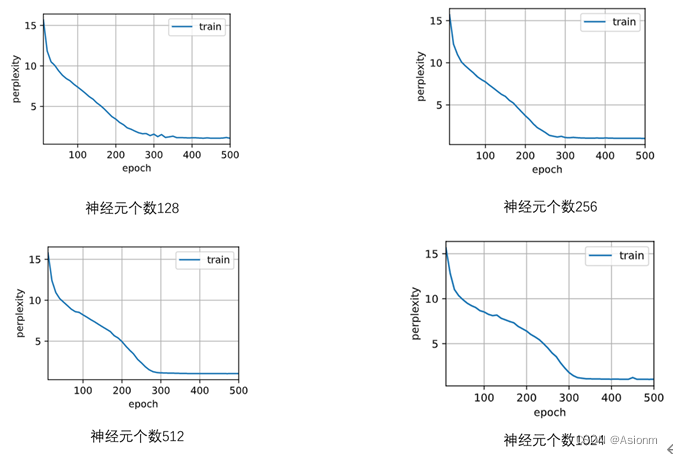
对于“time traveller”的预测:
(1)128: time travellerit s against reason said filbywhat is there is the
(2)256: travelleryou can show black is white by argument said filby
(3)512: time traveller for so it will be convenient to speak of himwas e
(4)1024: time traveller with a slight accession ofcheerfulness really thi
从结果中可以看出其结果基本一致,但是128与512的困惑度比其他两者低,而128可能是因为欠拟合的原因,而512则可能为过拟合。
基于上面的调参可以发现,最好的一组是神经元个数为512组合。
1.3 LSTM架构
1.3.1 LSTM架构搭建
对于LSTM架构的实现,同样使用了d2l中的“time machine(时间机器)”数据。LSTM也称为长短期记忆网络,它具有一定的记忆功能。LSTM相对于GRU更加地复杂,拥有更多的门控系统,因此同样的参数数据下LSTM的训练时间可能长于GRU,但是相应的训练效果可能会更好。下面利用d2l的LSTM模块快速搭建LSTM架构。(详细代码可见于.ipynb文件)
初次训练使用的参数epochs次数为500次、学习率为1、隐含层数量256,下面为训练得到的结果。
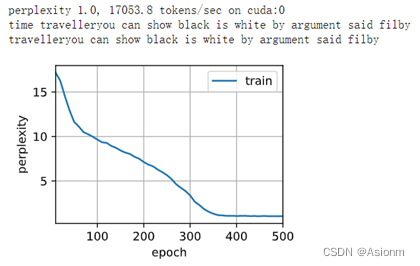
从上面的结果可以看出,在epochs为500,学习率为1时,图像在接近250时收敛,最后困惑度为1。从结果的输出可以看出,其拼写基本正确,且已经拥有一定的语义。这说明了训练是有一定的效果,且与RNN相比其效果更好,与GRU相比效果基本一致。
1.3.2 LSTM超参数调整
对于LSTM超参数的调整基本与RNN的一致,其参数选取理由一致,下面为调参结果。
1 epochs次数
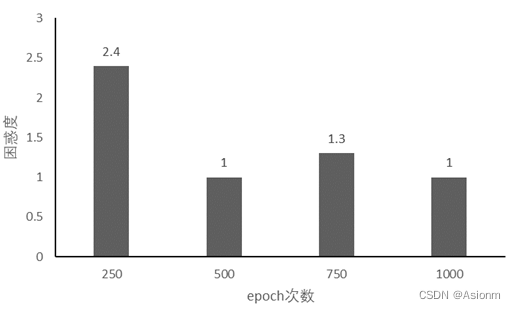
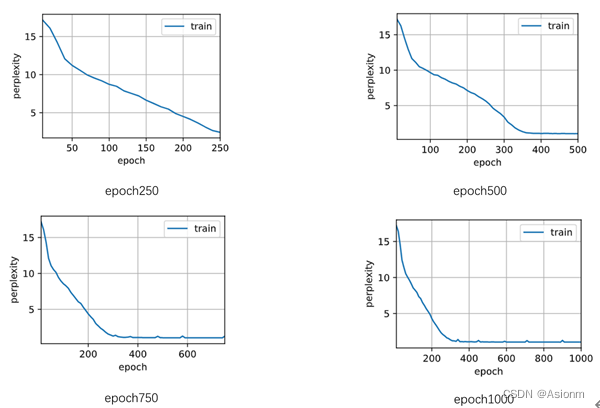
对于“time traveller”的预测:
(1)Epoch250: time traveller soud in the bertal it it as ingous doo doust hick
(2)Epoch500: time travelleryou can show black is white by argument said filby
(3)Epoch750: time traveller fich wi har hive tree yyinn waid the peos co vepr
(4)Epoch1000: time travelleryou can show black is white by argument said filby
可以看出基本呈现递减的形式,但是当为750时困惑度却较高预测结果也不是很好,这可能与偶然性有关需要更多实验以证明。
2 学习率
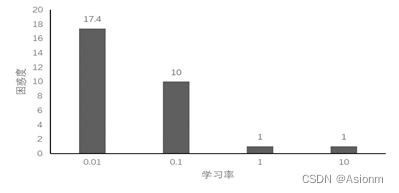
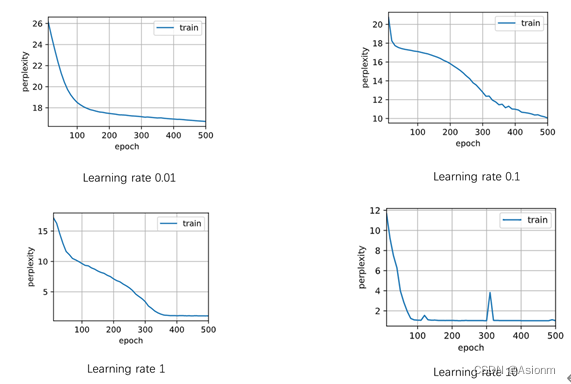
对于“time traveller”的预测:
(1)lr0.01: time traveller t e e t e e t e e t e e t e e t
(2)lr0.1: time travellere the the the the the the the the the the the the
(3)lr1: travelleryou can show black is white by argument said filby
(4)lr10: time traveller for so it will be convenient to speak of himwas e
可以看出训练效果随着学习率的增大而增大,与GRU与RNN不同的是,LSTM架构的学习率是学习率越大效果越好,而其他两者则是介于一个范围内。者可能与架构内部网络层有关。
3 隐藏层神经元数量
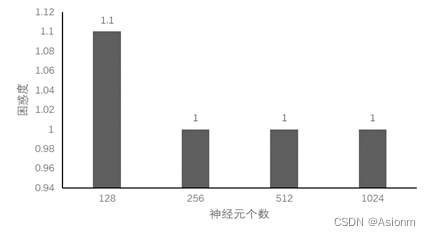
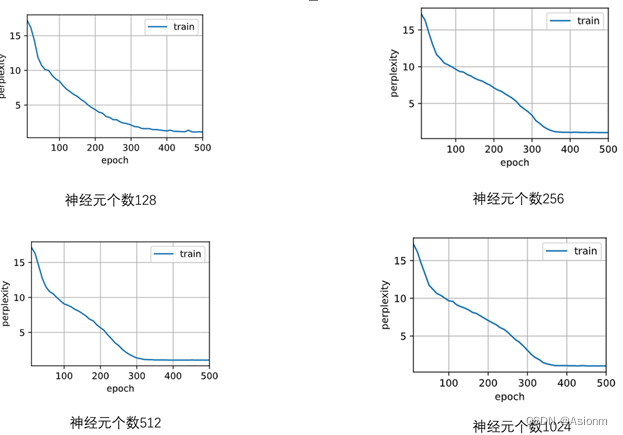
对于“time traveller”的预测:
(1)128: time travellerice withereal inhis fefclndiface traces along i ou
(2)256: travelleryou can show black is white by argument said filby
(3)512: time travelleryou can show black is white by argument said filby
(4)1024: time traveller for so it will be convenient to speak of himwas e
1.4 三种架构的对比
从上面的调参实验中可以看到,RNN明显是差于GRU与LSTM的。GRU与LSTM拥有更好的收敛能力,以及更好地效果,且其预测的有效性也更好。而GRU与LSTM的对比相对来说在以上实验中并不能明显看出,可能在更复杂的数据集中才可以测试出两组的优缺点。但是在调参实验中,GRU与LSTM在学习率调节方面存在明显的不同,在GRU中学习率最优的是为1时,最差为10时,而LSTM却是1与10同样的效果。而这可能是由于两者的网络层存在差异所照成的。
2 序列到序列学习
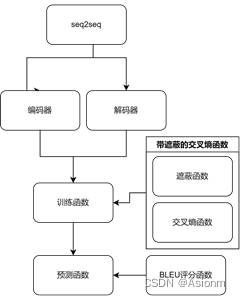
序列到序列模型是一个基于编码器与解码器的模型,可以用于解决输出序列与输入序列不一致的情况,一般用于翻译。对于序列到序列模型的构建训练,我是通过d2l教程进行的,在教程的代码中,首先需要定义编码器与解码器,用于处理输入与输出。其次设置带有遮蔽功能的交叉熵函数用于损失函数,并将其带入训练函数中。最后进行训练,然后定义BLEU评分函数用于预测时量化预测效果。其代码搭建的流程如下图所示。(具体代码见于.ipynb文件)
下面为隐藏层层数为2,神经元个数为256,学习率为0.005, epoch为300的结果。
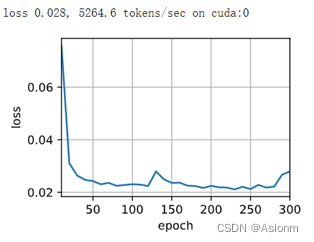
下面为预测结果,

可知bleu越大越解决1那么其预测的效果越好,可以看到前两者的值为1,说明预测效果是很好的,但是后面两个的值却越来越小,而在查看正确翻译后发现输出的法语翻译效果是不佳的。而仔细观察其原因可以发现后两者稍微比前两者的单词个数要多长度要长,所以者可能是导致其效果不佳的原因,这说明此seq2seq模型拥有一定的优化空间。
3 实验结论
本次实验中构建了RNN、GRU、LSTM架构对“time machine”数据集进行了训练,在训练的过程中通过不断地调节epoch\学习率\神经元个数三个参数以获取较好的结果。除了不同参数外的对比,还进行了不同架构间的对比。除了构建三个经典的循环神经网络模型外,还学习了seq2seq这个含有编码器与解码器的模型,并进行训练推理得到相应结果。
最后的结果发现,epoch次数很小时会对实验的结果造成不利的影响,但是当epoch达到一定的大小后此影响将逐渐减小,甚至变得毫无影响。而学习率对于RNN与GRU来讲其最佳值在1附近,但是对于LSTM却发现,学习率为10时LSTM照样可以拥有较好的结果,但是其他两者学习率为10时效果却是最差的。对于神经元个数对结果的影响,从上面的实验内容可以看出,其影响是最为显著的,一般来说神经元个数越多其效果越好,而这也可能是因为神经元越多拟合效果越佳的原因。对于seq2seq的学习,在最后的训练预测结果中可以发现,模型对短句子的预测效果较好,但是对于较长的句子的效果却是十分差的,这也说明此模型具有一定的提升空间。