Pytorch从零开始实战——YOLOv5-Backbone模块实现
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——YOLOv5-Backbone模块实现
- 环境准备
- 数据集
- 模型选择
- 开始训练
- 可视化
- 模型预测
- 总结
环境准备
本文基于Jupyter notebook,使用Python3.8,Pytorch2.0.1+cu118,torchvision0.15.2,需读者自行配置好环境且有一些深度学习理论基础。本次实验的目的理解YOLOv5-C3模块。
第一步,导入常用包
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn.functional as F
import random
from time import time
import numpy as np
import pandas as pd
import datetime
import gc
import os
import copy
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
设置随机数种子
torch.manual_seed(428)
torch.cuda.manual_seed(428)
torch.cuda.manual_seed_all(428)
random.seed(428)
np.random.seed(428)
创建设备对象,并且查看GPU数量
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device, torch.cuda.device_count() # (device(type='cuda'), 2)
数据集
本次实验与上次实验仅仅是网络上的差异,其他并没有什么不同,本次数据集还是使用天气识别的数据集,分别有四个类别,cloudy、rain、shine、sunrise,不同的类别存放在不同的文件夹中,文件夹名是类别名。
使用pathlib查看类别
import pathlib
data_dir = './data/weather_photos/'
data_dir = pathlib.Path(data_dir) # 转成pathlib.Path对象
data_paths = list(data_dir.glob('*'))
classNames = [str(path).split("/")[2] for path in data_paths]
classNames # ['cloudy', 'sunrise', 'shine', 'rain']
使用transforms对数据集进行统一处理,并且根据文件夹名映射对应标签
all_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])total_data = datasets.ImageFolder("./data/weather_photos/", transform=all_transforms)
total_data.class_to_idx # {'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3}
随机查看五张图片
def plotsample(data):fig, axs = plt.subplots(1, 5, figsize=(10, 10)) #建立子图for i in range(5):num = random.randint(0, len(data) - 1) #首先选取随机数,随机选取五次#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据#而展示图像用的imshow函数最常见的输入格式也是3通道npimg = torchvision.utils.make_grid(data[num][0]).numpy()nplabel = data[num][1] #提取标签 #将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取axs[i].imshow(np.transpose(npimg, (1, 2, 0))) axs[i].set_title(nplabel) #给每个子图加上标签axs[i].axis("off") #消除每个子图的坐标轴plotsample(total_data)

根据8比2划分数据集和测试集,并且利用DataLoader划分批次和随机打乱
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_ds, test_ds = torch.utils.data.random_split(total_data, [train_size, test_size])batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,batch_size=batch_size,shuffle=True,)
test_dl = torch.utils.data.DataLoader(test_ds,batch_size=batch_size,shuffle=True,)len(train_dl.dataset), len(test_dl.dataset) # (901, 226)
模型选择
此次模型借用K同学所绘制的模型图
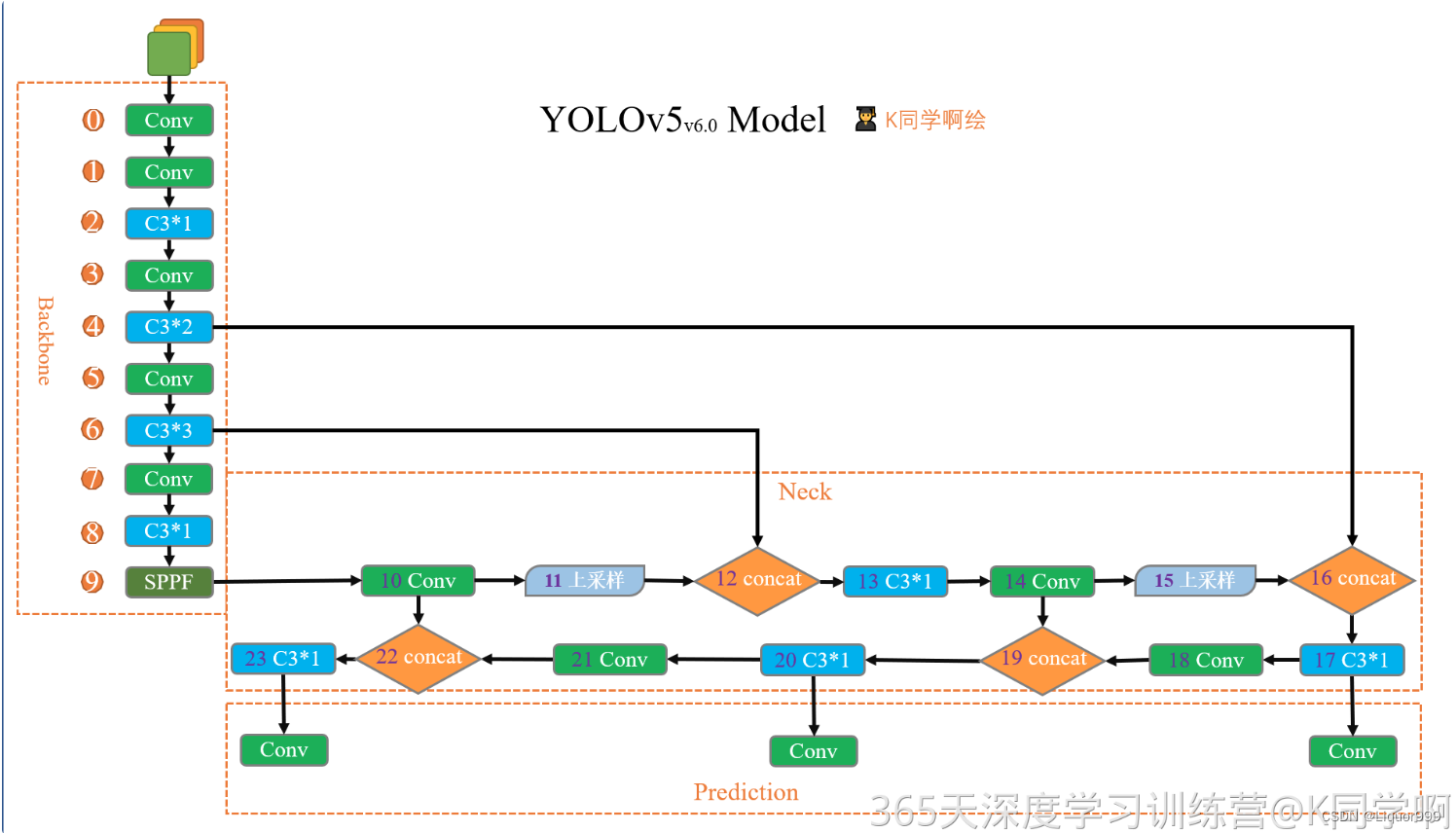
定义了一个autopad函数,用于确定卷积操作的填充,如果提供了p参数,则函数将使用提供的填充大小,否则函数中的填充计算将根据卷积核的大小k来确定,如果k是整数,那么将应用方形卷积核,填充大小将设置为k // 2,如果k是一个包含两个整数的列表,那么将应用矩形卷积核,填充大小将分别设置为列表中两个值的一半。
def autopad(k, p=None): if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] return p
定义自定义卷积层,在init方法中:创建了一个卷积层 self.conv,使用了 nn.Conv2d,该卷积层接受输入通道数 c1,输出通道数 c2,卷积核大小 k,步幅 s,填充 p,分组数 g,并且没有偏置项(bias=False)。创建了一个批归一化层 self.bn,用于规范化卷积层的输出。创建了一个激活函数层 self.act,其类型取决于 act 参数。如果 act 为 True,它将使用 SiLU(Sigmoid Linear Unit)激活函数;如果 act 为其他的 nn.Module 类,它将直接使用提供的激活函数;否则,它将使用恒等函数(nn.Identity)作为激活函数。其中,SiLU激活函数为SiLU(x) = x * sigmoid(x)。
class Conv(nn.Module):def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))
定义Bottleneck类,这个模块的作用是实现标准的残差连接,以提高网络性能。在 init方法中:计算了中间隐藏通道数 c_,它是输出通道数 c2 乘以扩张因子 e 的整数部分。创建了两个 Conv 模块 self.cv1 和 self.cv2,分别用于进行卷积操作。self.cv1 使用 1x1 的卷积核,将输入特征图的通道数从 c1 变换为 c_。self.cv2 使用 3x3 的卷积核,将通道数从 c_ 变换为 c2。创建了一个布尔值 self.add,用于指示是否应用残差连接。self.add 为 True 的条件是 shortcut 为 True 且输入通道数 c1 等于输出通道数 c2。
在forward 方法中,首先,通过 self.cv1(x) 将输入 x 传递给第一个卷积层,然后通过self.cv2(self.cv1(x)) 将结果传递给第二个卷积层。最后,根据 self.add 的值来决定是否应用残差连接。如果 self.add 为 True,将输入 x 与第二个卷积层的输出相加,否则直接返回第二个卷积层的输出。这样模块在需要时应用残差连接,以保留和传递更多的信息。
class Bottleneck(nn.Module):def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
C3模块整体如上图所示,cv1 和 cv2 是两个独立的卷积操作,它们的输入通道数都是 c1,并经过相应的卷积操作后,输出通道数变为 c_。这是为了将输入特征映射进行降维和变换。cv3 接受 cv1 和 cv2 的输出,并且希望在这两部分特征上进行进一步的操作。为了能够将它们连接起来,cv3 的输入通道数必须匹配这两部分特征的输出通道数的总和,因此是 2 * c_。其中这个模块可以叠加n个Bottleneck块。
class C3(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
下面定义了SPPF模块,初始化SPPF模块时,c1 是输入通道数,c2 是输出通道数,k 是池化核的大小,默认为5。在初始化过程中,通过除以2来得到隐藏通道数 c_。同时,定义了两个卷积层 cv1 和 cv2,以及一个最大池化层 m。
forward 函数中,首先,输入通过卷积层 cv1 进行处理,然后通过最大池化层 m 进行两次池化,分别得到 y1 和 y2。最后,将原始输入 x、y1、y2 以及 y2 经过一次最大池化后的结果进行通道拼接,并通过卷积层 cv2 处理,得到最终输出。
这个模块实现了一种特殊的池化操作(空间金字塔池化),有助于提取输入特征的不同尺度信息。
class SPPF(nn.Module):def __init__(self, c1, c2, k=5): super().__init__()c_ = c1 // 2 self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * 4, c2, 1, 1)self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)def forward(self, x):x = self.cv1(x)with warnings.catch_warnings():warnings.simplefilter('ignore') y1 = self.m(x)y2 = self.m(y1)return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
YOLOv5——backbone模块将上面模块组合起来,包括一系列卷积、C3、SPPF和全连接层
class YOLOv5_backbone(nn.Module):def __init__(self):super(YOLOv5_backbone, self).__init__()self.Conv_1 = Conv(3, 64, 3, 2, 2) self.Conv_2 = Conv(64, 128, 3, 2) self.C3_3 = C3(128,128)self.Conv_4 = Conv(128, 256, 3, 2) self.C3_5 = C3(256,256)self.Conv_6 = Conv(256, 512, 3, 2) self.C3_7 = C3(512,512)self.Conv_8 = Conv(512, 1024, 3, 2) self.C3_9 = C3(1024, 1024)self.SPPF = SPPF(1024, 1024, 5)self.classifier = nn.Sequential(nn.Linear(in_features=65536, out_features=100),nn.ReLU(),nn.Linear(in_features=100, out_features=4))def forward(self, x):x = self.Conv_1(x)x = self.Conv_2(x)x = self.C3_3(x)x = self.Conv_4(x)x = self.C3_5(x)x = self.Conv_6(x)x = self.C3_7(x)x = self.Conv_8(x)x = self.C3_9(x)x = self.SPPF(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = YOLOv5_backbone().to(device)
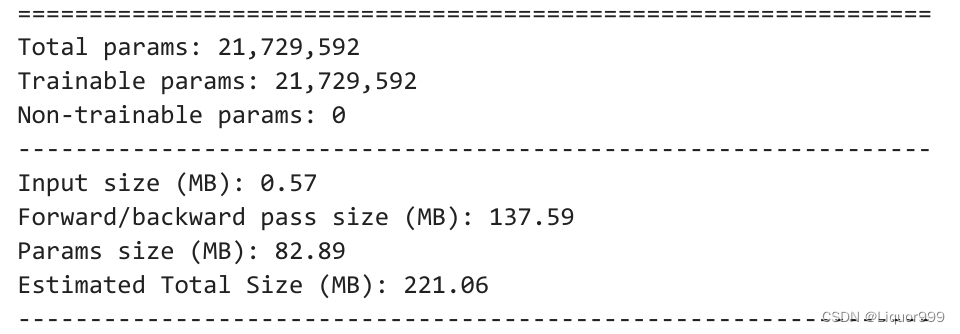
使用summary查看模型架构
from torchsummary import summary
summary(model, input_size=(3, 224, 224))
开始训练
定义训练函数
def train(dataloader, model, loss_fn, opt):size = len(dataloader.dataset)num_batches = len(dataloader)train_acc, train_loss = 0, 0for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)opt.zero_grad()loss.backward()opt.step()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
定义测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_acc, test_loss = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss += loss.item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
定义学习率、损失函数、优化算法
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.0001
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
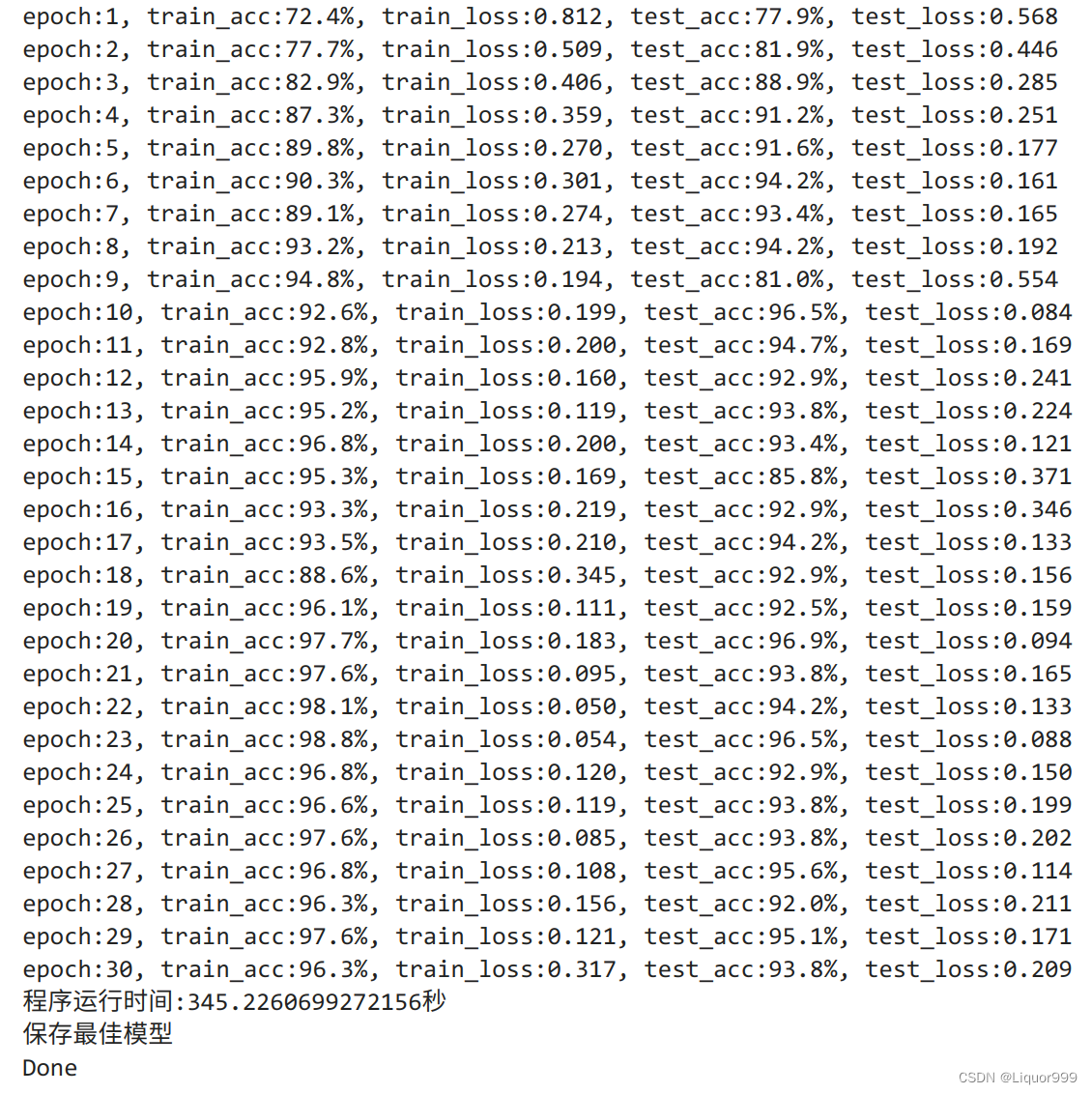
开始训练,epoch设置为30
import time
epochs = 30
train_loss = []
train_acc = []
test_loss = []
test_acc = []T1 = time.time()best_acc = 0
best_model = 0for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval() # 确保模型不会进行训练操作epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)if epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))T2 = time.time()
print('程序运行时间:%s秒' % (T2 - T1))PATH = './best_model.pth' # 保存的参数文件名
if best_model is not None:torch.save(best_model.state_dict(), PATH)print('保存最佳模型')
print("Done")
可视化
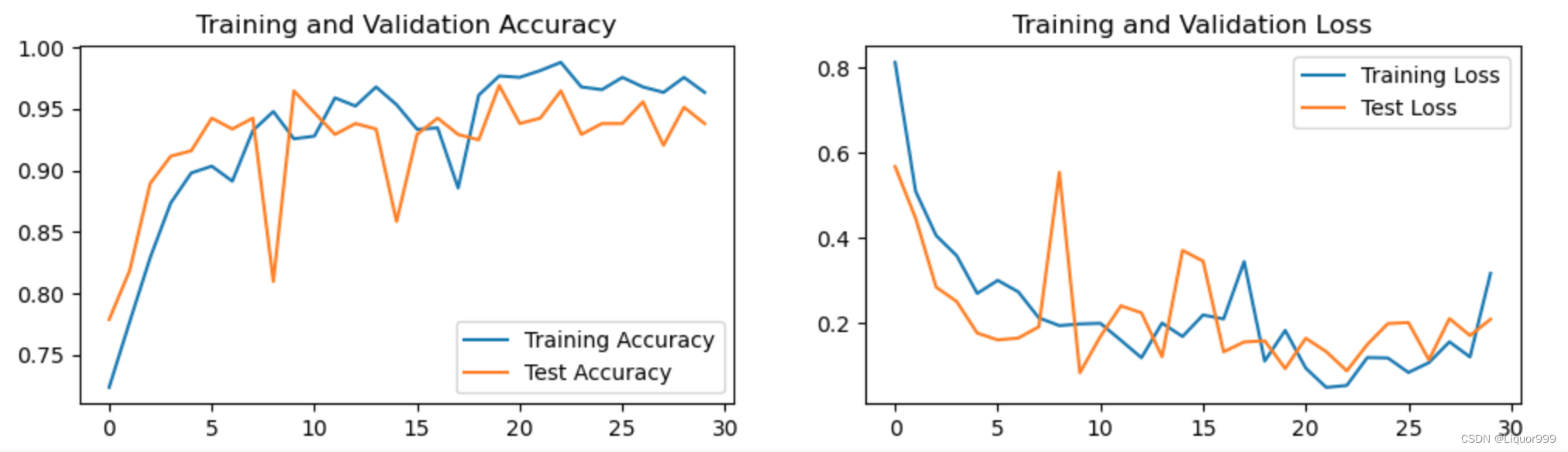
将训练与测试过程可视化
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
模型预测
定义预测函数
from PIL import Image classes = list(total_data.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')
预测一张图片
predict_one_image(image_path='./data/weather_photos/cloudy/cloudy10.jpg', model=model, transform=all_transforms, classes=classes) # 预测结果是:cloudy
查看一下最佳模型的epoch_test_acc, epoch_test_loss
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss # (0.9690265486725663, 0.09377550333737972)
总结
本次实验了解到模型由卷积、批归一化和残差连接组成,可以进一步提取和强化特征,同时又了解到SPPF层的实现,其用于捕获不同尺度的上下文信息。
)







![[单片机课程设计报告汇总] 单片机设计报告常用硬件元器件描述](http://pic.xiahunao.cn/[单片机课程设计报告汇总] 单片机设计报告常用硬件元器件描述)

圆角(border-radius)不起作用的问题)








