UUID(Universally Unique IDentifier 通用唯一标识符),是一种常用的唯一标识符,在MySQL中,可以利用函数uuid()来生产UUID。因为UUID可以唯一标识记录,因此有些场景可能会用来作为表的主键,但直接用UUID来作为主键可能存在性能缺陷,我们需要采取一些优化手段。
目录
一、UUID主键的缺陷
二、优化方案
一、UUID主键的缺陷
在MySQL中,innodb是按照表的聚簇索引(主键)来组织数据存储的,也就是主键的顺序决定了数据存储的顺序。这也是为什么我们通常推荐用整型,自增的数字来作为表的主键,当新数据插入时,主键一定是最大的,只要放在叶子层中最后的数据页即可,对已有的数据不会有影响。
而如果用UUID来做主键,则会有2个缺陷:
- UUID的值是随机的,因此新插入的数据有可能会插到已有数据的中间,这会导致整个索引树的重新平衡和节点分裂,降低插入性能,数据量越大越严重。
- UUID是字符型,相对数字占用的存储空间很大,这意味着主键很大,而主键又会附加到所有的二级索引中,因此所有的索引都很臃肿,消耗额外的磁盘和内存资源,降低查询性能。
UUID的生成方式有很多版本,这里举2个最常用的:
- UUID V1: 通过时间戳和MAC地址来生成,可以生成顺序的UUID。
- UUID V4: 通过随机数来生成,无法生成顺序的UUID。
MySQL自带的函数uuid()是通过UUIDv1生成,因此上面第一个缺陷通常不存在,你需要注意的是某些应用是否会自己生成非顺序的UUID插入表中。
下面通过示例来看差别,我们创建两张结构一样的表,一张用数字作为主键,一张用UUID作为主键:
create table digital_pk(
id int auto_increment primary key,
serial int);create table uuid_pk(
id varchar(36) default(uuid()) primary key,
serial int);
我们分别向2张表中插入5条数据:
insert into digital_pk(serial) values(1);
insert into digital_pk(serial) values(2);
insert into digital_pk(serial) values(3);
insert into digital_pk(serial) values(4);
insert into digital_pk(serial) values(5);
insert into uuid_pk(serial) values(1);
insert into uuid_pk(serial) values(2);
insert into uuid_pk(serial) values(3);
insert into uuid_pk(serial) values(4);
insert into uuid_pk(serial) values(5);
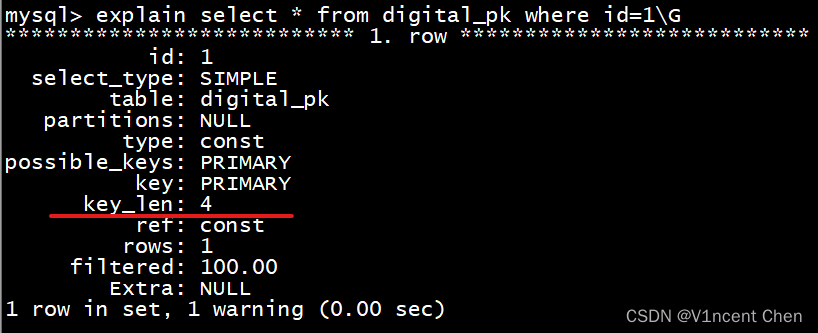
我们通过explain来查看索引的信息:
-
explain select * from digital_pk where id=1\G
explain select * from uuid_pk where id='71b49d70-7f98-11ee-a9a1-0050569c9844'\G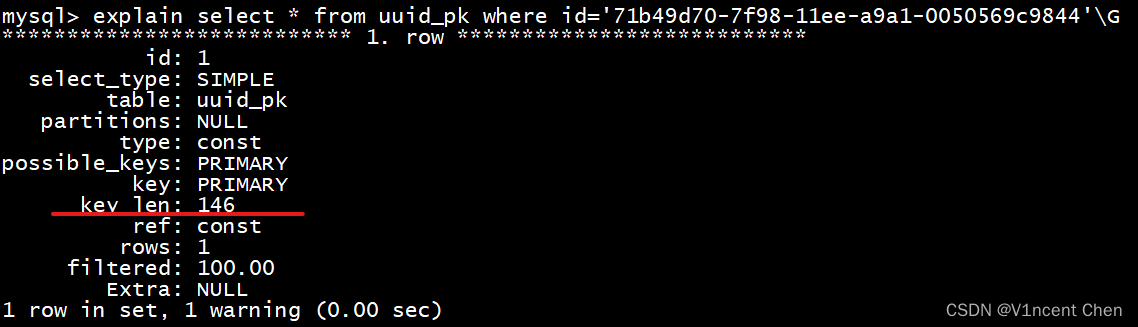
可以看到uuid作为主键的长度是146,而数字做主键的长度为4,这意味着当数据量非常大的时候,UUID的索引会非常臃肿,查询性能会很低。
二、优化方案
虽然通常不推荐使用UUID作为表的主键,但某些场景如果我们必须要用UUID作为主键,我们也可以通过一些方法来规避上述缺陷。
MySQL为了优化UUID的存储,专门提供了两个函数:
- uuid_to_bin(uuid, swap_flag),将字符型UUID转换为二进制UUID,转换后返回的数据类型是varbinary。
- bin_to_uuid(uuid, swap_flag),将二进制UUID转换为字符型UUID
在存储的时候用uuid_to_bin(uuid, swap_flag)将UUID由字符型转化为二进制,可以大大缩小索引的长度,函数中的swap_flag有2个取值:
- 0 代表转换后的数据依然是和UUID字符排序相同
- 1 代表转换后将UUID中的time-low和time-high部分(第一和第三组)交换位置,转换后数据可以按时间连续递增,对InnoDB的聚簇索引还会有性能提升。注意这个仅对UUID V1版本基于时间戳生成的UUID才有效,如果是其他类型的UUID,不会得到性能提升。
下面我们利用这个函数新建一个表uuid_pk_v2:
create table uuid_pk_v2(
id binary(16) default(uuid_to_bin(uuid(),1)) primary key,
serial int);
- 这里id列的数据类型变成了binary(16),同时uuid在存储时转换为二进制型存储。
插入1条数据
-
insert into uuid_pk_v2(serial) values(1);

select id, serial from uuid_pk_v2;
select bin_to_uuid(id,1), serial from uuid_pk_v2;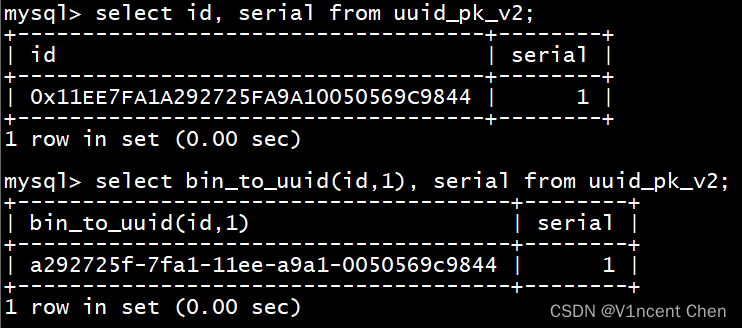
- 直接查询是以16进制显示的数据,这对我们没有意义,我们需要用bin_to_uuid()函数将数据还原为字符串型UUID。
我们再看一下索引:
explain select * from uuid_pk_v2 where id=uuid_to_bin('a292725f-7fa1-11ee-a9a1-0050569c9844',1)\G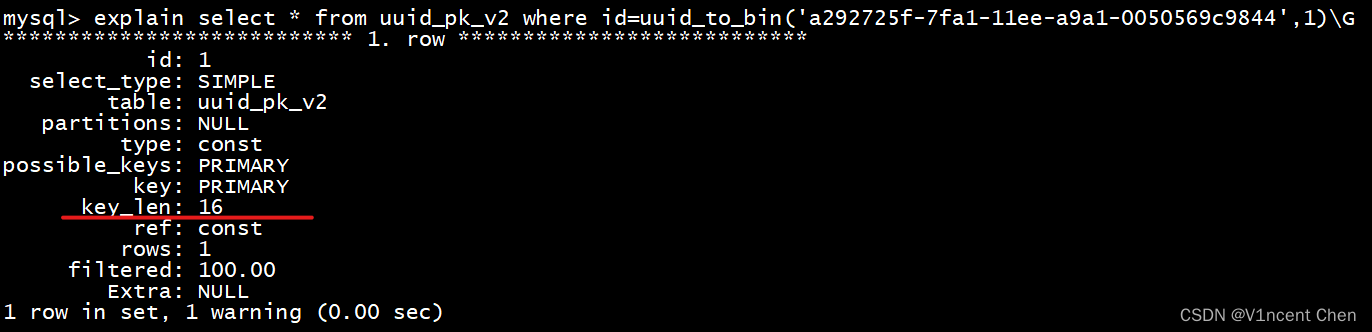
- 索引的长度从164缩短为16,只有原来的十分之一,这代表索引在磁盘和内存占用的空间也会缩小至十分之一,扫描速度会快的多。
- 因此,虽然在插入和查询的时候多了一层函数的处理,但是这可以完美解决前面UUID的两个缺陷,带来的性能提升是完全值得的。






 SyncVars特性使用)

 安装最新版本的 GCC)
:RNN)




)



【Nacos注册中心】)
