交叉熵(Cross-Entropy)是一种用于衡量两个概率分布之间的距离或相似性的度量方法。在机器学习中,交叉熵通常用于损失函数,用于评估模型的预测结果与实际标签之间的差异。
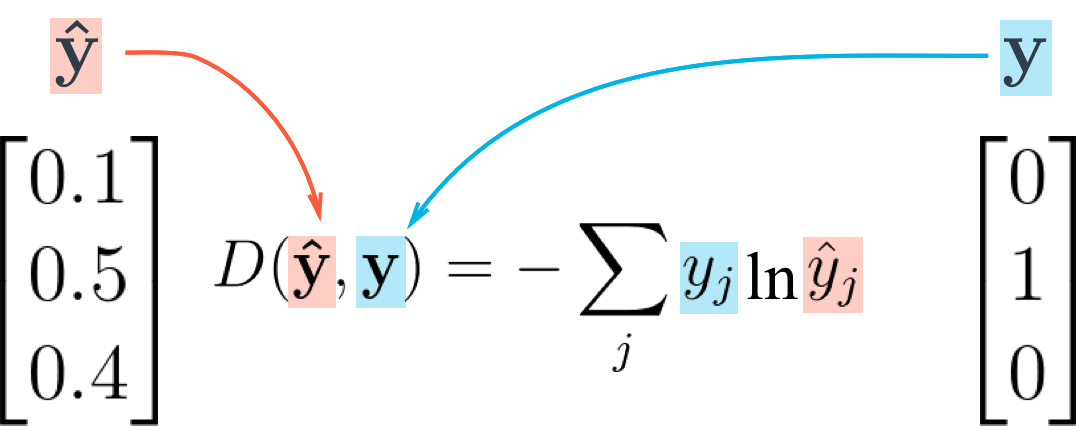
在分类问题中,交叉熵损失函数通常用于多分类问题,其中模型需要对输入样本进行分类,而标签是类别概率分布。交叉熵损失函数通过计算模型预测的概率分布与真实标签的概率分布之间的差异来衡量模型的性能。
具体来说,对于给定的样本和标签,交叉熵损失函数可以表示为:
L(y, y') = - ∑(y[i] * log(y'[i]))
其中 y 是真实标签的概率分布,y' 是模型预测的概率分布,x 是样本的特征向量。交叉熵损失函数的目的是最小化预测概率分布与真实概率分布之间的差异,使得模型能够更好地学习到数据的内在规律和特征。
在深度学习中,交叉熵损失函数通常与反向传播和优化算法一起使用,通过不断调整模型的参数来优化模型的性能。常用的交叉熵损失函数包括二元交叉熵、多元交叉熵和多标签交叉熵等。
import numpy as np
# 样本数据给出的分布概率,等于4的概率是100%,等于其他数字的概率是0%
p = [0,0,0,0,1,0,0,0,0,0]
# 第一种情况,识别结果是4的概率是80%,识别结果是9的概率是20%
q1 = [0,0,0,0,0.8,0,0,0,0,0.2]
# 第二种情况,识别结果是4的概率是60%,是9的概率是20%,是0的概率是20%
q2 = [0.2,0,0,0,0.6,0,0,0,0,0.2]
loss_q1 = 0.0
loss_q2 = 0.0
for i in range(1, 10):# 如果p(x)=0,那么,p(x)*log q1(x) 肯定等于0。如果q1(x)等于0,那么,log q1(x)不存在if p[i] != 0 and q1[i] != 0:loss_q1 += -p[i]*np.log(q1[i])# 如果p(x)=0,那么,p(x)*log q2(x) 肯定等于0。如果q2(x)等于0,那么,log q2(x)不存在 if p[i] != 0 and q2[i] != 0:loss_q2 += -p[i]*np.log(q2[i])print ("第一种情况,误差是:{}".format( round(loss_q1, 4)))
print ("第二种情况,误差是:{}".format(round(loss_q2, 4)))第一种情况,误差是:0.2231
第二种情况,误差是:0.5108






-- 属性获取与断言)
——管道过滤)






)
单位转像素(px)单位)
![[蓝桥杯 2022 省 A] 推导部分和](http://pic.xiahunao.cn/[蓝桥杯 2022 省 A] 推导部分和)


