目录
1、引言
2、什么是 RabbitMQ ?
3、RabbitMQ 优势
4、RabbitMQ 整体架构剖析
4.1、发送消息流程
4.2、消费消息流程
5、RabbitMQ 应用
5.1、广播
5.2、RPC
VC++常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)
https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章正在更新中...)
https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章正在更新中...)![]() https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_11931267.html开源组件及数据库技术(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/category_11931267.html开源组件及数据库技术(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_12458859.html网络编程与网络问题分享(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/category_12458859.html网络编程与网络问题分享(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_2276111.html
https://blog.csdn.net/chenlycly/category_2276111.html
1、引言
在进行系统设计的时候,各个模块、服务器之间为了实现数据的交互,通常是建立连接通过发送消息来进行。如果将他们一一建立连接,就会出现链路太多,每一条链路都必须感知对端等问题。此场景下消息将非常混乱,后期维护也将非常痛苦。为了解决这个问题,精简系统,引入RabbitMq。各相关模块不在相互发送消息,而将消息都发送给RabbitMQ,由RabbitMQ负责将消息传递出去。
那么,什么是RabbitMQ?RabbitMQ又是如何实现这些功能的呢?
2、什么是 RabbitMQ ?

在讲RabbitMQ之前,需要先了解一下AMQP的概念。
AMQP,即Advanced Message Queuing Protocol(高级消息队列协议),是一个提供统一消息服务的应用层标准高级消息队列协议。AMQP是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件传递消息,不受客户端/中间件不同产品、不同开发语言等条件的限制。该协议是一种二进制协议,提供客户端应用于消息中间件之间异步、安全、高效的交互。相对于我们常见的REST API,AMQP更容易实现,可以降低开销,同时灵活性高,可以轻松的添加负载平衡和高可用性的功能,并保证消息传递,在性能上AMQP协议也相对更好一些。
RabbitMQ是AMQP的一个开源实现,服务器端用Erlang语言编写,用于在分布式系统中存储转发消息,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、 ActionScript、XMPP、STOMP等,支持AJAX。 MQ(Messages Queue)是一种应用程序与应用程的通信方法。RabbitMQ相当于生产者与消费者的模式,消息发送端(生产者)将消息写入消息队列,消息接收端(消费者)从消息队列中取出消息、消费消息;而消息的发送端无需知道消息接受端的存在,反之亦然。
3、RabbitMQ 优势
RabbitMQ主要有以下几个优势:
- 可靠性(Reliablity):使用了一些机制来保证可靠性,比如持久化、传输确认、发布确认。
- 灵活的路由(Flexible Routing):在消息进入队列之前,通过Exchange来路由消息。对于典型的路由功能,Rabbit已经提供了一些内置的Exchange来实现。针对更复杂的路由功能,可以将多个Exchange绑定在一起,也通过插件机制实现自己的Exchange。
- 消息集群(Clustering):多个RabbitMQ服务器可以组成一个集群,形成一个逻辑Broker。
- 高可用(Highly Avaliable Queues):队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。
- 多种协议(Multi-protocol):支持多种消息队列协议,如STOMP、MQTT等。
- 多种语言客户端(Many Clients):几乎支持所有常用语言,比如Java、.NET、Ruby等。
- 管理界面(Management UI):提供了易用的用户界面,使得用户可以监控和管理消息Broker的许多方面。
- 跟踪机制(Tracing):如果消息异常,RabbitMQ提供了消息的跟踪机制,使用者可以找出发生了什么。
- 插件机制(Plugin System):提供了许多插件,来从多方面进行扩展,也可以编辑自己的插件。
4、RabbitMQ整体架构剖析
在详细介绍RabbitMQ之前,先介绍几个重要的概念:
- Queue:消息队列
- Exchange:交换机,它会按照路由规则来投递消息
- Routing key:路由关键字,exchange会根据它来进行消息投递
- Bind:绑定了queue和exchange,根据路由规则将消息会投递到对应的消息队列中去。
- Producer:消息生产者
- Consumer:消息的消费者
RabbitMQ的整体架构图如下所示:
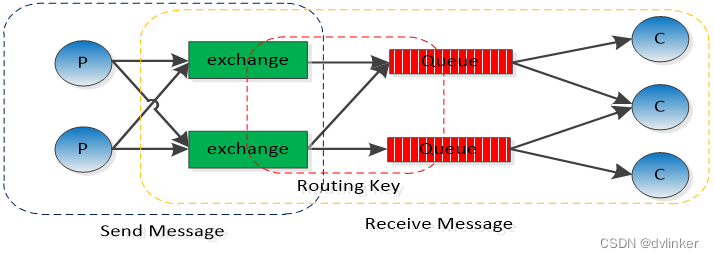
P(Producer,消息生产者)负责发送,C(Consumer,消息消费者)负责消费消息。其中交换机exchange、队列Queue的定义、exchange与Queue的绑定既可以放在发送端,也可以放在消费端,但是不管放在何处定义,要在使用前定义,否则会出错。本文统一将exchange放在生产者端来定义,而将queue的定义,queue与exchange的绑定放在消费端来处理。另外,为了防止第一次使用exchange是在消费端,可以在消费端也同时定义exchange。本文不考虑这种情况,默认在消费端使用exchange的时候已定义过。
4.1、发送消息流程
P端发送消息的基本过程是:
1)连接服务器;
2)声明exchange,并设置其相关属性;
3)将消息发送到exchange。
其中,exchange有3种类型:fanout、routing、topic:
1)fanout不处理路由键,为空即可,只要简单的将队列绑定到交换机上,那么发送到交换机上的消息都会被转发到与该交换机绑定的所有队列上。
2)Routing处理路由键,需要将一个队列绑定到交换机上,要求消息与一个特定的路由键完全匹配。
3)Topic将路由键与某模式进行匹配,此时队列需要绑定到一个模式上。匹配的规格是”#”匹配一个或多个词,”*”匹配一个词。
4.2、消费消息流程
C消费消息的基本过程是:
1)连接服务器;
2)声明队列queue及其属性(持久化、无消费者时是否自动删除队列等等);
3)设置routingkey,并且通过routingkey将queue与exchange绑定到一起;
4)等待消息,消费消息。
其中,queue可以设置的属性有:Exclusive、auto_delete、durable。
1)Exclusive:排他队列,如果一个队列被声明为排他队列,该队列仅对首次声明它的连接可见,并在连接断开时自动删除。
2)Auto_delete:自动删除,如果该队列没有任何订阅的消费者的话,该队列会被自动删除。这种队列适用于临时队列。
3)Durable:服务器重启后,队列不会丢失。
对上述的exchange、queue、binding的一个例子:
Mq.queue_bind(“QueueTest”, “ExchangeTest”, “Test”)这个绑定的意思是:任何发送到交换机ExchangeTest的具有路由键Test的消息都会被路由到名为QueueTest的队列中。
5、RabbitMQ 应用
一般平台的消息大致分为两种类型:notif和req-ack-notif。对应于rabbitmq正好有两种模型:publish/subscribe和rpc。下面根据实际应用来讲解这两个模型。
5.1、广播
假设应用服务器收到了一条消息A,需要广播给其他多个业务服务器。按照图一中rabbitmq的基本结构我们应该能想到两种方式:
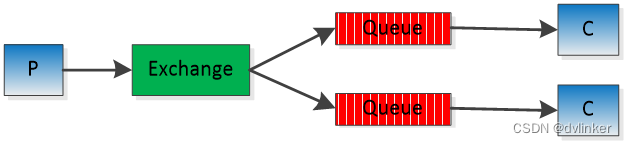
Method1
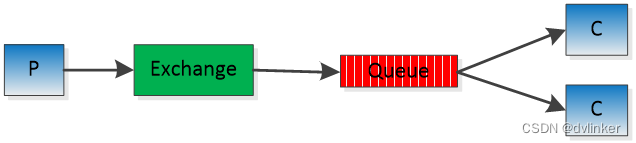
Method2
上述两种方法哪一种能实现我们的目的?答案是Method1,如果采用Method2的话,queue会将消息依次分发给两个消费端,例如客户端C1收到消息1,3,5…,客户端C2收到消息2,4,6…。
虽然此种方法不能实现我们的目的,但在此处插入一点,及每条消息的处理量可能而且几乎肯定是不同的,所以有时会出现客户端C1处理完了N条消息,但客户端C2一条还没处理完,为了解决这个问题,rabbitmq提供了公平调度的概念即Fair dispatch:Rabbitmq不会在同一时间给工作者分配多个任务,只有在工作者完成任务之后,才会再次接收到任务。
回到刚才讨论的地方,我们已经确立了使用Method1来完成该功能,现在根据该方法进行一些简单的编码验证(注:验证语言为python)。publish/subscribe模型之P客户端代码如下:
import pika#建立连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()#声明交换机
channel.exchange_declare(exchange='exchangeTest', type='fanout')#发送消息
channel.basic_publish(exchange='exchangeTest', routing_key='', body='Hello World!')
connection.close()publish/subscribe模型之C客户端代码:
import pika#建立连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()#创建queue
channel.queue_declare(queue=’QueueTest’)#绑定
channel.queue_bind(exchange=’exchangeTest’, queue=’QueueTest’)
def callback(ch, method, properties, body):
print “ [x] Received %r” %(body, )
channel.basic_consume(callback, queue =’QueueTest’, no_ack=True)
channel.start_consuming()AMQP支持在一个TCP连接上启用多个MQ通信channel,每个channel都可以被应用作为通信流, 被分配了一个整数标识,自动由Connection()类的.channel()方法维护。每个AMQP程序至少要有一个连接和一个channel。
5.2、RPC
对于大部分消息我们不仅仅是通知,更多的是需要对方在接收到消息后给我们回复的。此时,
我们就需要rabbitmq提供的RPC模型,如下图所示:
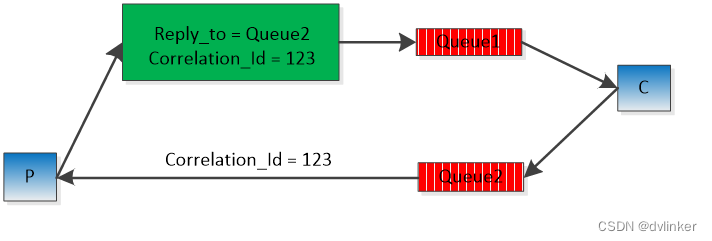
RPC模型与广播模型相比,最大的区别是消费者客户端在接收到消息的时候,需要给发送者P回复消息。而同样的,消息生产者P也不仅仅是做为发送端了,他还需要接收来自消费端C回复的消息。
由P到C我们知道直接将Queue1绑定到exchange上就OK了,那么C回复消息的时候通过什么回给P呢?为此,rabbitmq在P发送消息的时候,提供设置回调队列及关联ID,C在给P回复消息的时候,通过回调队列即可。提供关联ID的目的是即使P端收到Queue2的消息,也要验证Correlation_Id是否匹配,不匹配的话,直接忽略。
使用如下的代码进行验证(注:验证语言为python),RPC模型之P端的代码如下:
import pika
class Center(object):def __init__(self):self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))self.channel = self.connection.channel() #定义接收返回消息的队列,此处为一随机生成的队列result = self.channel.queue_declare(exclusive=True)self.callback_queue = result.method.queue#等待接收消息self.channel.basic_consume(self.on_response, no_ack=True,queue=self.callback_queue)#定义接收到返回消息的处理方法def on_response(self, ch, method, props, body):self.response = bodydef request(self, n):self.response = None#发送计算请求
self.channel.basic_publish(exchange='',routing_key='compute_queue', properties=pika.BasicProperties
(reply_to = self.callback_queue,), body=str(n))#接收返回的数据while self.response is None:self.connection.process_data_events()return int(self.response)
center = Center()
response = center.request(30)
print " [.] Got %r" % (response,)RPC模型之C端代码:
import pikaclass Center(object):def __init__(self):self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))self.channel = self.connection.channel() #定义接收返回消息的队列,此处为一随机生成的队列result = self.channel.queue_declare(exclusive=True)self.callback_queue = result.method.queue#等待接收消息self.channel.basic_consume(self.on_response, no_ack=True,queue=self.callback_queue)#定义接收到返回消息的处理方法def on_response(self, ch, method, props, body):self.response = bodydef request(self, n):self.response = None#发送计算请求
self.channel.basic_publish(exchange='',routing_key='compute_queue', properties=pika.BasicProperties
(reply_to = self.callback_queue,),body=str(n))#接收返回的数据while self.response is None:self.connection.process_data_events()return int(self.response)
center = Center()
response = center.request(30)
print " [.] Got %r" % (response,)

)
单位转像素(px)单位)
![[蓝桥杯 2022 省 A] 推导部分和](http://pic.xiahunao.cn/[蓝桥杯 2022 省 A] 推导部分和)



)







的三个组成部分)


