几乎所有的编程语言都会提供排序函数,比如C语言中qsort(),C++ STL中的sort()、stable_sort(),还有Java语言中的Collections.sort()。在平时的开发中,我们也都是直接使用这些现成的函数来实现业务逻辑中的排序功能。那你知道这些排序函数是如何实现的吗?底层都利用了哪种排序算法呢?
基于这些问题,今天我们就来看排序这部分的最后一块内容:如何实现一个通用的、高性能的排序函数?
如何选择合适的排序算法?
如果要实现一个通用的、高效率的排序函数,我们应该选择哪种排序算法?我们先回顾一下前面讲过的几种排序算法。
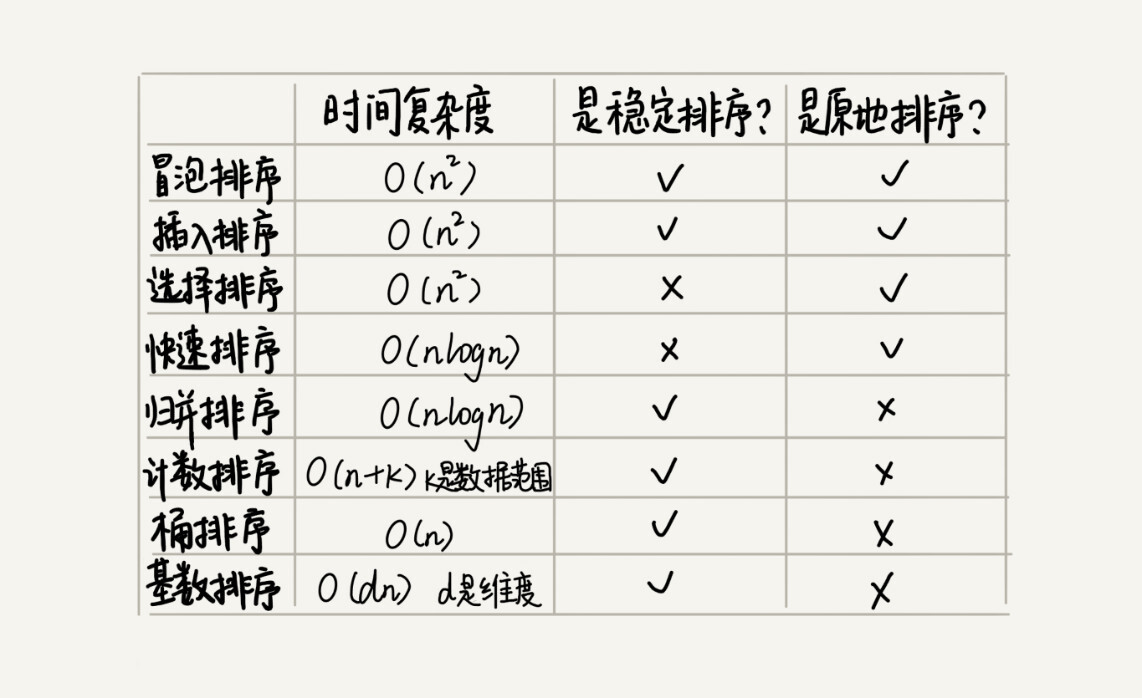
我们前面讲过,线性排序算法的时间复杂度比较低,适用场景比较特殊。所以如果要写一个通用的排序函数,不能选择线性排序算法。
如果对小规模数据进行排序,可以选择时间复杂度是O(n2)的算法;如果对大规模数据进行排序,时间复杂度是O(nlogn)的算法更加高效。所以,为了兼顾任意规模数据的排序,一般都会首选时间复杂度是O(nlogn)的排序算法来实现排序函数。
时间复杂度是O(nlogn)的排序算法不止一个,我们已经讲过的有归并排序、快速排序,后面讲堆的时候我们还会讲到堆排序。堆排序和快速排序都有比较多的应用,比如Java语言采用堆排序实现排序函数,C语言使用快速排序实现排序函数。
不知道你有没有发现,使用归并排序









)


)




)
)
