Ascend C编程模型与范式
1.并行计算架构抽象
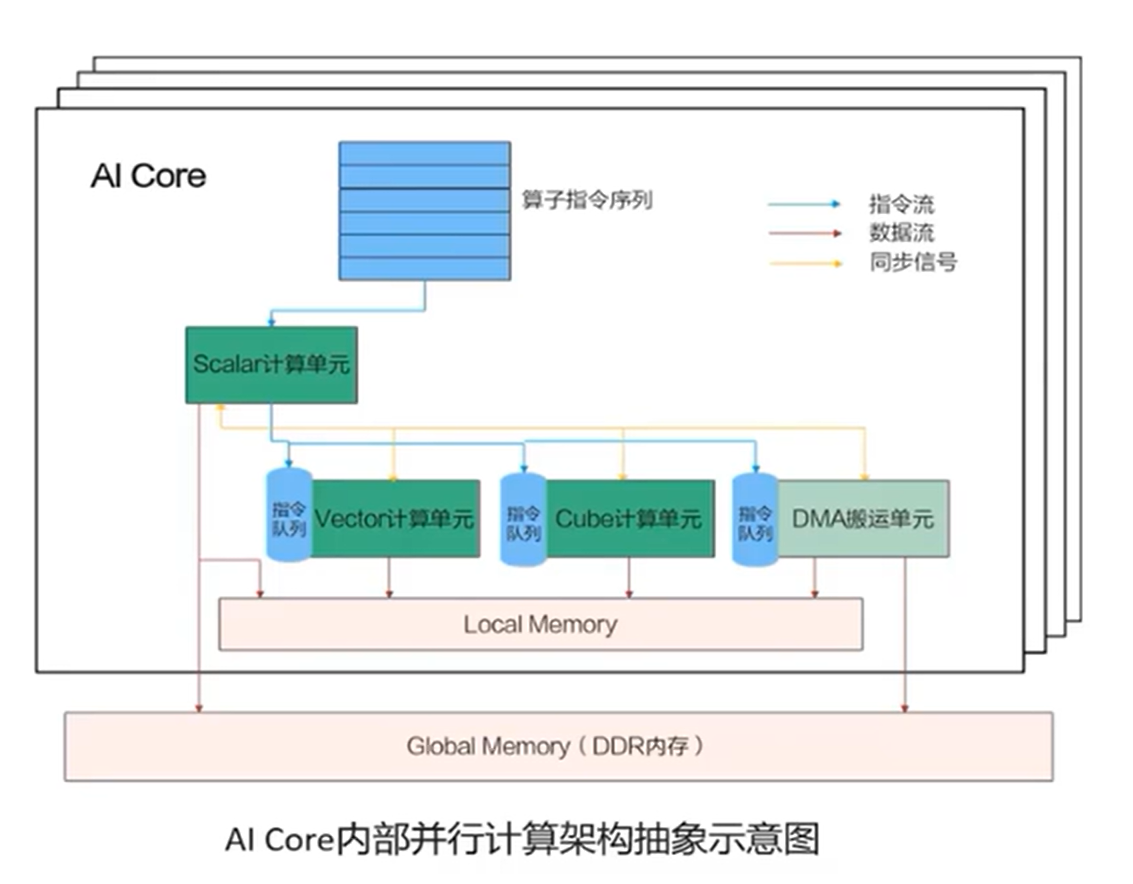
Ascend C编程开发的算子是运行在AI Core上的,所以我们需要了解一下AI Core的结构。AI Core主要包括计算单元、存储单元、搬运单元。
- 计算单元包括了三种计算资源:Scalar计算单元(执行标量计算);Cube计算单元(矩阵计算);Vector计算单元(向量运算)
- 搬运单元主要负责在Global Memory 和Local Memory之间搬运数据
- 包括内部存储(Local Memory)和外部存储(Global Memory)
数据在这些单元之间存储和计算,涉及到三种流:异步指令流、同步信号流、计算数据流。
- 异步指令流:指计算单元和搬运单元之间异步执行接收到的指令序列。
- 同步信号流:保证不同指令按照正确的逻辑关系执行
- 计算数据流:指搬运单元把数据搬运到Local Memory,把处理好的数据搬运回Global Memory的过程。
AI Core的内部架构图如下:
2.SPMD编程模型介绍
SPMD(Single Program, Multiple Data)模型是一种并行编程模型,用于同时处理多个数据元素的相同程序。在Ascend C中,SPMD模型用于编写并行计算任务,以便充分利用Ascend AI处理器的并行计算能力。
SPMD模型的要点如下:
-
Single Program:SPMD模型意味着编写的程序是相同的,不会针对不同的数据元素而改变。这个程序会在不同的数据上执行,但代码本身是相同的。这有助于提高代码的可维护性和复用性。每个核上唯一区别是block_idx不同。
-
Multiple Data:程序会同时处理多个数据元素,这些数据元素通常存储在数组或张量中。每个数据元素都会被相同的程序逐一处理,从而实现并行性。
3.核函数编写及调用
Ascend C核函数是一种用于编写高性能并行计算任务的特定函数,是算子设备侧入口。
3.1核函数定义
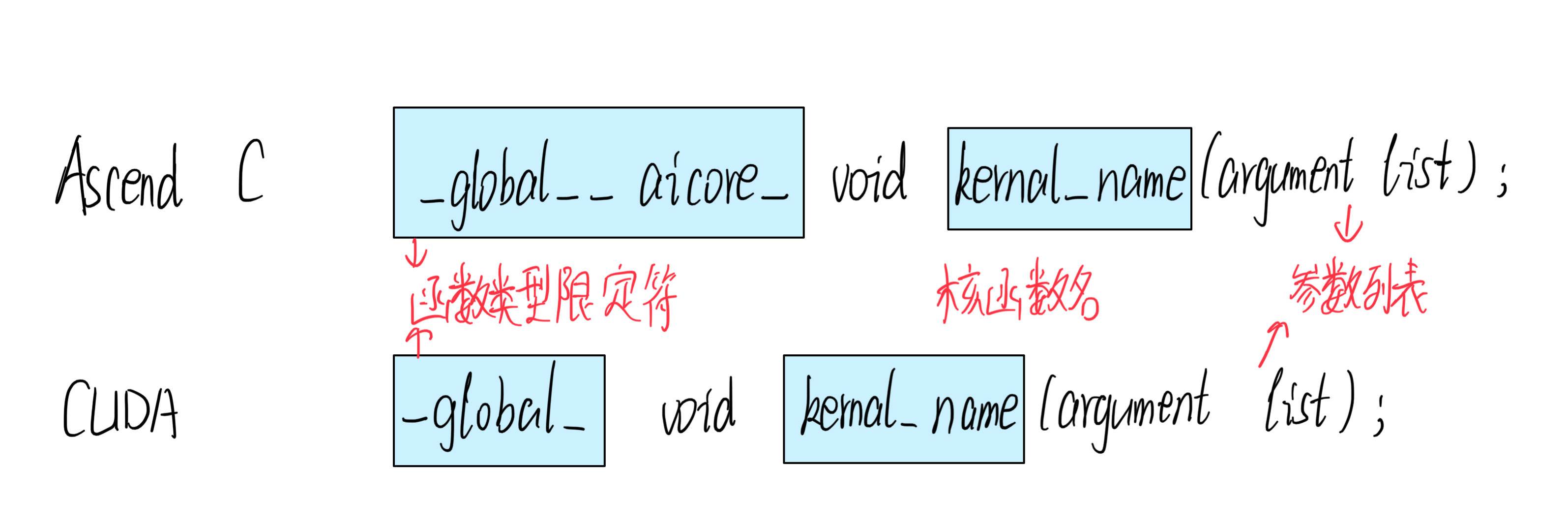
主要包括三个参数:函数类型限定符、核函数名、参数列表
1.使用__global__函数类型限定符来标识它是一个核函数,可以被<<<…>>>调用;使用__aicore__函数类型限定符来标识该核函数在设备端AI Core上执行。
2.指针入参变量需要增加变量类型限定符__gm__。表明该指针变量指向Global Memory上某处内存地址。
3.核函数使用内核调用符<<<…>>>这种语法形式,来规定核函数的执行配置:
kernel_name<<<blockDim, l2ctrl, stream>>>(argument list);
解释每个参数的意思:
- blockDim:规定了核函数将会在几个核上执行
- l2ctrl:暂时设置为固定值nullptr,开发者无需关注
- stream:类型为aclrtStream
昨天做了一个关于Ascend C加法算法的算子开发实验,代码地址:Gitee代码仓库
在这个Add文件中,算子开发的核心代码在 add_custom.cpp中,其中核函数定义的代码为:
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z) { KernelAdd op; op.Init(x, y, z); op.Process(); }
这段代码使用__global__ __aicore__函数类型限定符表明这个核函数将在AI Core上执行
void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z):这是核函数的声明,接受三个GM_ADDR参数,分别命名为x、y和z。GM_ADDR是指向通用内存(GM,General Memory)的指针类型,表明这个核函数将操作通用内存中的数据。
KernelAdd op:初始化算子类,算子类提供算子初始化和核心处理等方法。
op.Init(x, y, z):初始化函数,获取该核函数需要处理的输入输出地址,同时完成必要的内存初始化工作
op.Process():核心处理函数,完成算子的数据搬运与计算等核心逻辑
定义完了核函数之后,就可以进行调用:
void add_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z) { add_custom<<<blockDim, l2ctrl, stream>>>(x, y, z); }
<<<blockDim, l2ctrl, stream>>>:这是CUDA执行配置,它指定了核函数 add_custom 的执行方式。blockDim 表示使用多少个CUDA线程块,l2ctrl 和 stream 表示与线程块配置和流相关的信息。这些参数通常用于控制CUDA核函数的执行方式和资源配置。


 等级考试试卷(七级))





)
TCP 实战抓包分析(三)TCP 第一次握手 SYN 丢包)

)




)
)

)