文章目录
- 1、本地独立部署会话模式的Flink
- 2、本地独立部署会话模式的Flink集群
- 3、向Flink集群提交作业
- 4、Standalone方式部署单作业模式
- 5、Standalone方式部署应用模式的Flink
Flink的常见三种部署方式:
- 独立部署(Standalone部署)
- 基于K8S部署
- 基于Yarn部署
1、本地独立部署会话模式的Flink
独立部署就是独立运行,即Flink自己管理Flink资源,不依靠任何外部的资源管理平台,比如K8S或者Hadoop的Yarn,当然,独立部署的代价就是:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理,生产环境或者作业量大的场景下不建议采用独立部署。
- 下载安装包
# 下载地址:
https://archive.apache.org/dist/flink/flink-1.17.0/
flink-1.17.0-bin-scala_2.12.tgz
- 上传安装包到Linux节点服务器上的某目录:
/opt/moudle/flink-1.17.0-bin-scala_2.12.tgz
- 解压
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/
- 启动,进入安装目录执行start-cluster.sh
[code9527@node01 flink-1.17.0] bin/start-cluster.sh

- 访问WebUI,对Flink集群进行监控管理
http://IP:8081
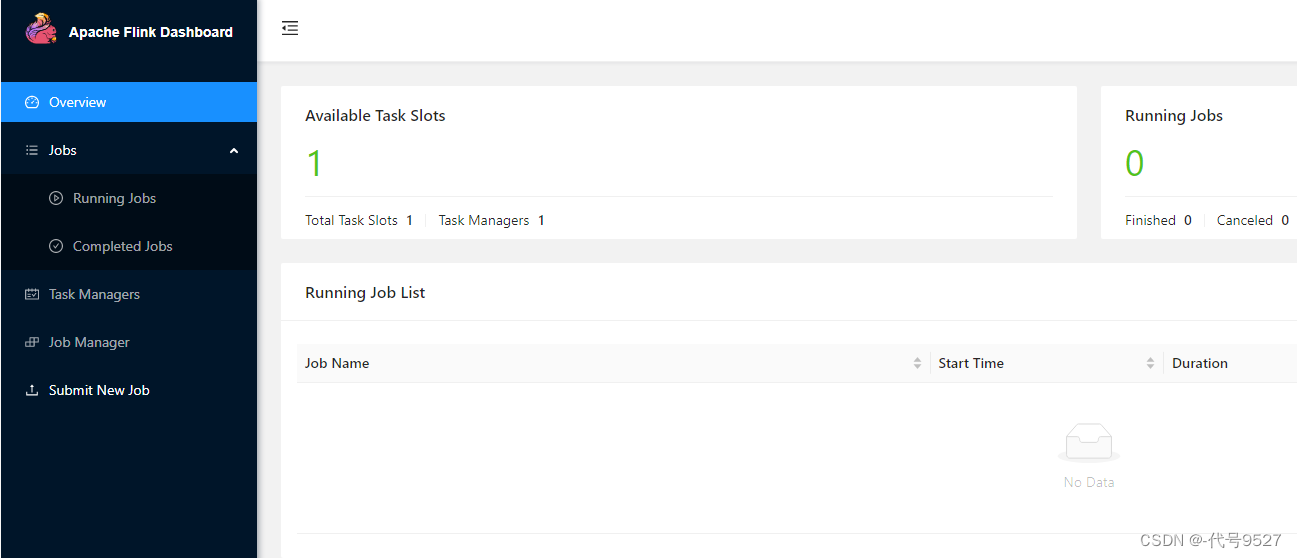
独立安装会话模式的Flink成功,控制台中,可以看到,TaskManager的数量为1(本来就一台机器,一个节点),由于默认每个TaskManager的Slot数量为1,所以总Slot数和可用Slot数都为1。最后,可停止集群:
[code9527@node01 flink-1.17.0] /bin/stop-cluster.sh
可能遇到的坑:
坑1:
start-cluster.sh执行报错:Please specify JAVA_HOME. Either in Flink config ./conf/flink-conf.yaml or as system-wide JAVA_HOME.
原因:未安装Java环境
yum install -y java-1.8.0-openjdk.x86_64
坑2:
http://IP:8081访问不通
处理下防火墙:
firewall-cmd --add-port 8081/tcp --permanentfirewall-cmd --reload
2、本地独立部署会话模式的Flink集群
上面部署的单机Flink,当你有多台服务器,要部署一个集群时,大体流程和上面一样。假设有三台服务器,角色分配规划如下:
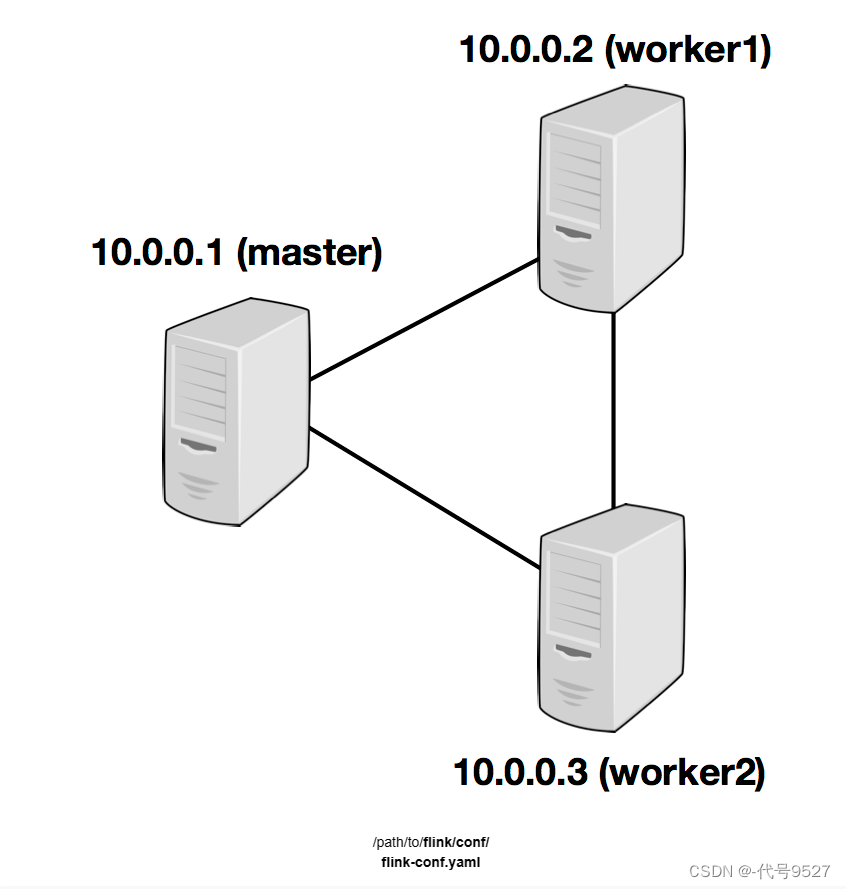
| 节点服务器 | node-01 | node-02 | node-03 |
|---|---|---|---|
| 角色 | JobManager+TaskManager | TaskManager | TaskManager |
主节点上的操作:
- 上传安装包到Linux节点服务器上的某目录:
/opt/moudle/flink-1.17.0-bin-scala_2.12.tgz
- 解压
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/
- 进入解压目录/conf目录,修改flink-conf.yaml文件
vi flink-conf.yaml# 修改内容如下:
# JobManager节点地址,我写了IP,这里IP或者hostname都行
jobmanager.rpc.address: node-01
jobmanager.bind-host: 0.0.0.0
rest.address: node-01
rest.bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: node-01- 其他可选配置:在flink-conf.yaml文件中还可以对集群中的JobManager和TaskManager组件进行优化配置
- jobmanager.memory.process.size:对JobManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。- taskmanager.memory.process.size:对TaskManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1728M,可以根据集群规模进行适当调整。- taskmanager.numberOfTaskSlots:对每个TaskManager能够分配的Slot数量进行配置,默认为1,可根据TaskManager所在的机器能够提供给Flink的CPU数量决定。所谓Slot就是TaskManager中具体运行一个任务所分配的计算资源。- parallelism.default:Flink任务执行的并行度,默认为1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
- 修改workers文件,指定干活儿的节点TaskManager的信息,这里是node01和另外两台主机02、03
[code9527@node01 conf] vi workers# 修改如下内容:
node-01
node-02
node-03# 用IP也行,这就是上面单机我也用用IP,而不用默认localhost的原因,多节点下看着乱得很
- 修改masters文件
vi masters# 修改内容,hostname也行
node-01:8081
至于两个Task的从节点,直接把上面改好的Flink安装目录拷贝或分发给另外两个节点服务器:
# node02、node03上建好/opt/moudle/flink-1.17.0/目录后,01节点执行
scp /opt/moudle/flink-1.17.0 root@node02:/opt/moudle/flink-1.17.0/
scp /opt/moudle/flink-1.17.0 root@node03:/opt/moudle/flink-1.17.0/再修改node02的taskmanager.host:
# conf目录下
vim flink-conf.yaml# 改为:
taskmanager.host: node02 # IP或hostname
再修改node03的taskmanager.host:
# conf目录下
vim flink-conf.yaml# 改为:
taskmanager.host: node03 # IP或hostname
回node01启动,执行start-cluster.sh
[code9527@node01 flink-1.17.0] bin/start-cluster.sh
此时,在控制台,应该可以看到当前集群的TaskManager数量为3,总Slot数和可用Slot数都为3
3、向Flink集群提交作业
上一篇,写了读取socket发送的单词并统计单词个数的程序,这里演示将它提交到集群中年去执行,首先将程序打包,在pom.xml中添加打包插件:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers combine.children="append"><transformerimplementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"></transformer></transformers></configuration></execution></executions></plugin></plugins>
</build>打包,指令或者IDEA页面上操作:
mvn clean
mvn package
打包完成后,在target目录下即可找到所需JAR包,JAR包会有两个,一个原始包,一个带依赖的包(类似SpringBoot打包插件),因为集群中已经具备任务运行所需的所有依赖,所以建议使用原始包original-xxx.jar。下面打开Flink的控制台,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的JAR包:
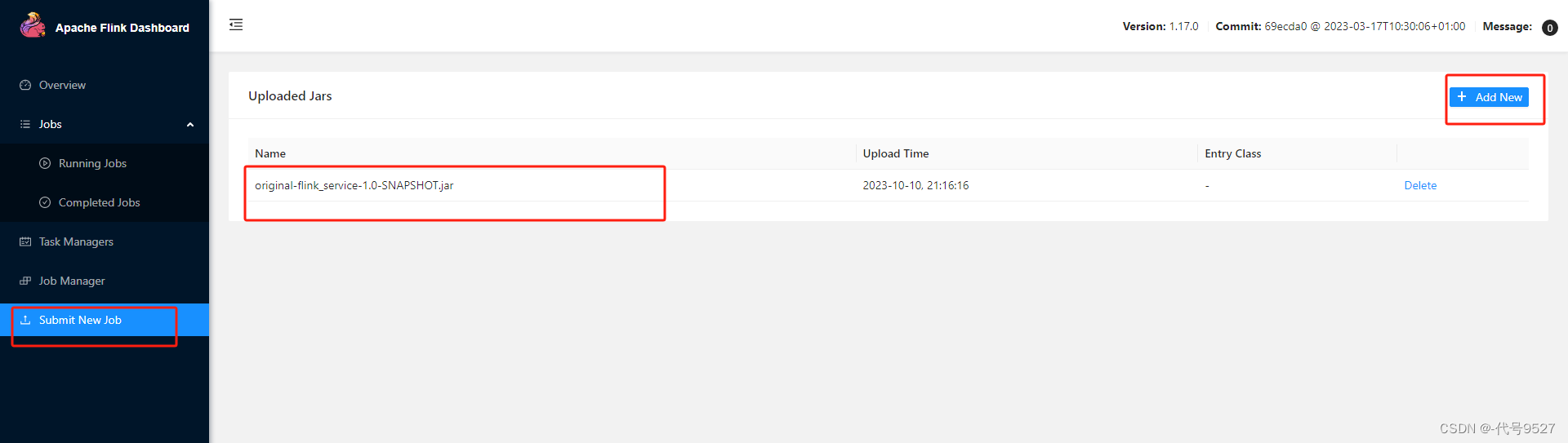
点击该JAR包,出现任务配置页面,进行相应配置:
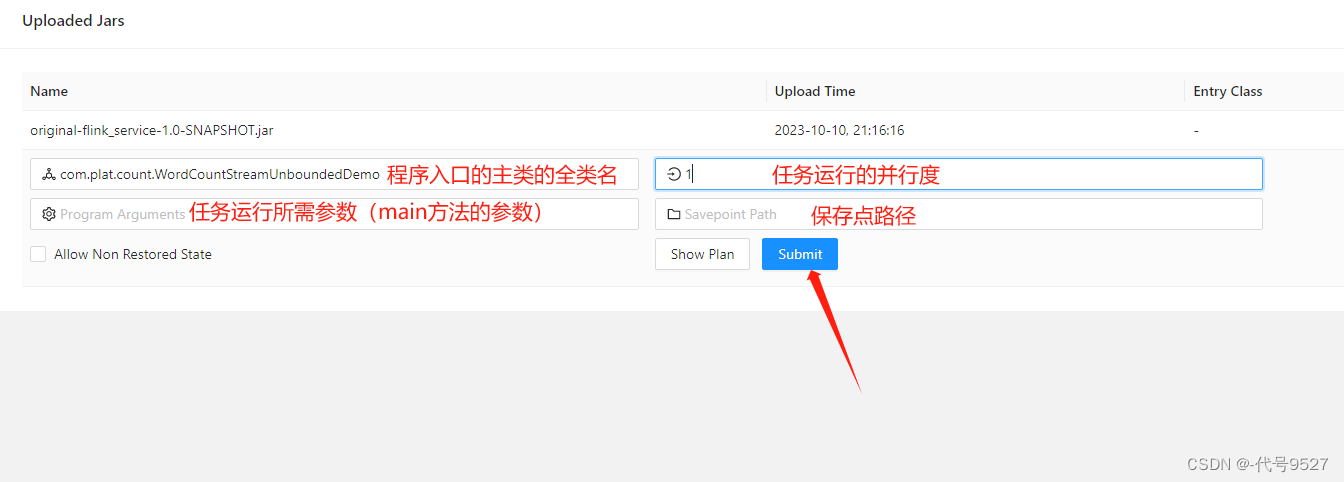
点Submit提交作业(点Submit没反应参考【这篇】),导航栏的Running Jobs可查看程序运行列表情况
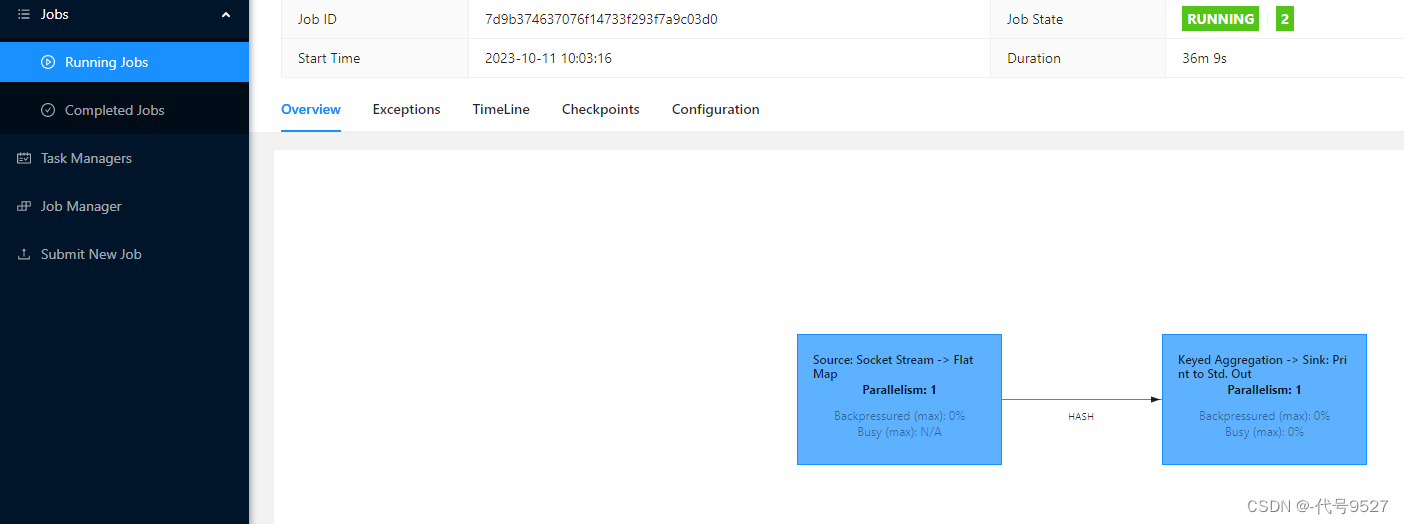
在Flink程序里写的Linux主机里开启端口监听,并在socket端口中输入一些字符串:

先点击Task Manager侧边栏,再切StdOut的tab页,点刷新,可以看到运行成功:
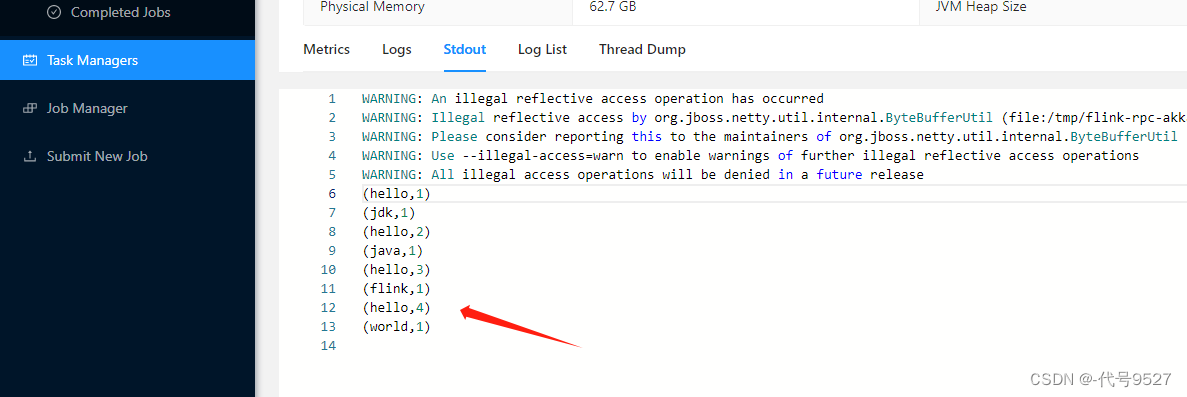
先取消任务,接下来用命令行提交任务:

使用命令行提交,会话模式下还是先启动集群:
bin/start-cluster.sh
进入flink安装目录/opt/module/flink-1.17.0,把前面的jar包上传到该目录下,执行flink run指令提交作业
bin/flink run -m 10.4.95.27:8081 -c com.plat.count.SocketStreamWordCount ./FlinkService-1.0-SNAPSHOT.jar# -m指定了提交到的JobManager
# -c指定了入口类
提交成功:

此时web控制台还是可以看到同样的效果,且/opt/module/flink-1.17.0/log路径中,也可以查看TaskManager的输出:
[root@node-105-69 log] cat flink-atguigu-standalonesession-0-node-105-69.out(hello,1)
(hello,2)
(flink,1)
(hello,3)
(scala,1)4、Standalone方式部署单作业模式
部署不了单作业模式,前面说了,Standalone方式下,Flink并不支持单作业模式部署。因为单作业模式需要借助一些资源管理平台,比如K8S
5、Standalone方式部署应用模式的Flink
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本。需要使用同样在bin目录下的standalone-job.sh来创建一个JobManager
# 先停掉会话模式
[root@node-105-69 flink-1.17.0] bin/stop-cluster.sh
# 继续开启对应的Linux主机的netcat
nc -lk 9527
将上面的安装包放到flink的lib目录下
[root@node-105-69 flink-1.17.0] mv FlinkService-1.0-SNAPSHOT.jar lib/
启动JobManager,这里我们直接指定作业入口类,脚本会到lib目录扫描所有的jar包
[root@node-105-69 flink-1.17.0] bin/standalone-job.sh start --job-classname com.plat.count.SocketStreamWordCount
启动TaskManager:(独立部署,这个时候干活的Task是手动起的)
[root@node-105-69 flink-1.17.0] bin/taskmanager.sh start
发送数据到9527端口:
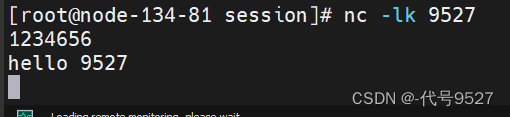
查看控制台:
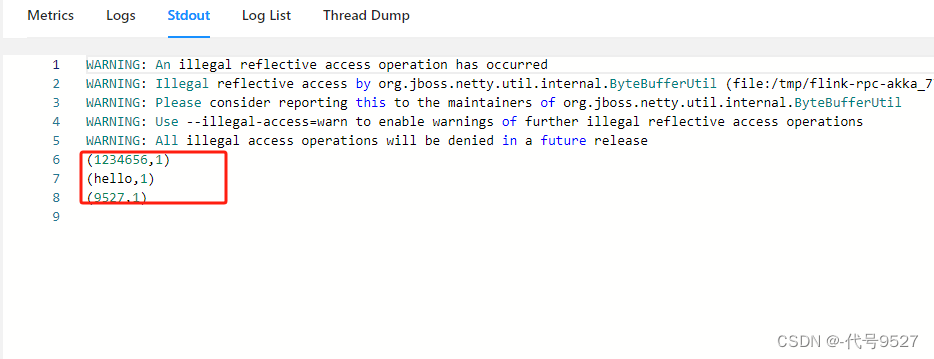
停掉集群:
bin/taskmanager.sh stop
bin/standalone-job.sh stop

—— 数据结构简介)









![[0xGameCTF 2023] web题解](http://pic.xiahunao.cn/[0xGameCTF 2023] web题解)







)