bookroo网页上有很多不错的英文图书书目。比如这个关于儿童花样滑冰的书单:
https://bookroo.com/explore/books/topics/ice-skating
怎么批量下载下来呢?
这个网页是动态网页,要爬取下来比较麻烦,可以先查看源代码,然后把源代码保存到本地e盘:DOCTYPE html.htm
打开这个源代码文件:

仔细看,书籍信息在json对象里面:

问ChatGPT如何提取这些书籍名称:
如何从以上网页源代码中提取出title的内容,比如提取出"title":"Mice Skating"、title":"Flora and the Penguin"中的:Mice Skating、Flora and the Penguin
ChatGPT的回复:
你的问题描述中的内容看起来像是一段JSON格式的数据,而不是HTML源代码。这是一个JSON对象,其中包含一个"books"的列表,每个列表项又是一个包含各种属性(包括"title")的字典。
为了提取"title"的内容,你可以首先将这个JSON字符串转换为Python的数据结构,然后遍历"books"列表,提取每个书籍的"title"。以下是一个例子:
import json
# 这是你的JSON字符串。我已经将其稍微清理过了。
json_str = '''
{
"props": {
"pageProps": {
"initialData": {
"pages": [
{
"books": [
{
"title": "Flora and the Penguin",
...
},
{
"title": "Mice Skating",
...
},
...
]
}
]
}
}
}
}
'''
# 将JSON字符串转为Python数据结构
data = json.loads(json_str)
# 遍历"books"列表
for page in data['props']['pageProps']['initialData']['pages']:
for book in page['books']:
# 提取并打印"title"
print(book['title'])
注意:我在JSON字符串中使用了省略号("...")来表示你的原始数据中还有更多的内容。在实际使用中,你应该用你的完整的JSON字符串替换json_str的值。
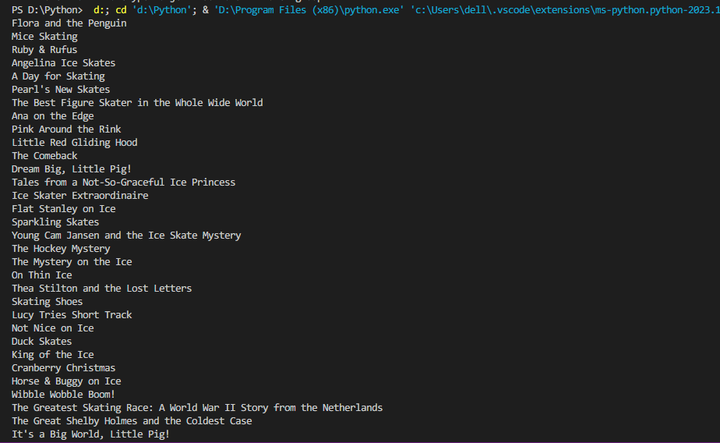
将所有的JSON字符串复制到json_str = ''' ''' 里面,运行程序,成功获取到页面的所有图书名称:





)





![2023年中国分布式光纤传感产量、需求量及行业市场规模分析[图]](http://pic.xiahunao.cn/2023年中国分布式光纤传感产量、需求量及行业市场规模分析[图])

)

创建不同类型的工程(IntelliJ IDEA 2022.1.3版本))



