前言
随着人工智能技术的不断发展,多模态大模型作为一种新型的机器学习技术,逐渐成为人工智能领域的热点话题。多模态大模型能够处理多种媒体数据,如文本、图像、音频和视频等,并通过学习不同模态之间的关联,实现更加智能化的信息处理。
近年来,文档解析与向量化技术在加速多模态大模型训练与应用中扮演着至关重要的角色。这些技术不仅提高了数据处理的速度和效率,还优化了模型的性能和准确性。今天,我们就来探讨一下这些技术如何助力多模态大模型的训练与应用。
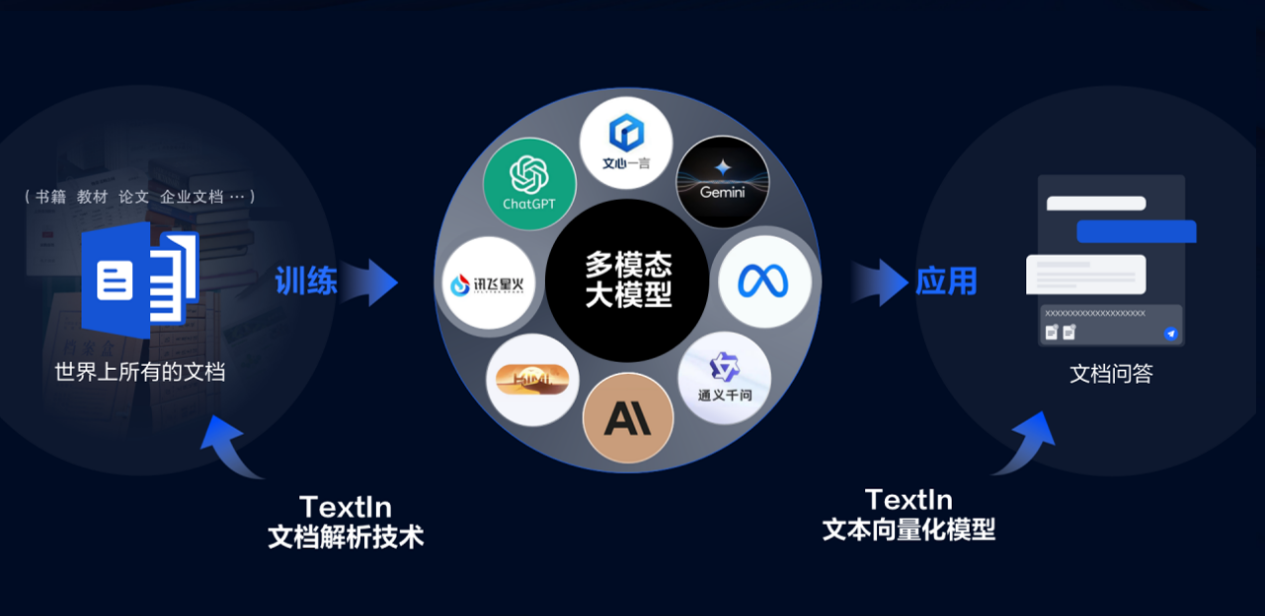
一、文档解析技术
文档解析技术主要负责对各种类型的文档进行结构化处理,提取出文档中的关键信息,并将其转化为计算机可读的格式。在多模态大模型训练中,文档解析技术可以处理包括文本、图像、音频、视频等在内的多种模态数据。
文档解析技术背景
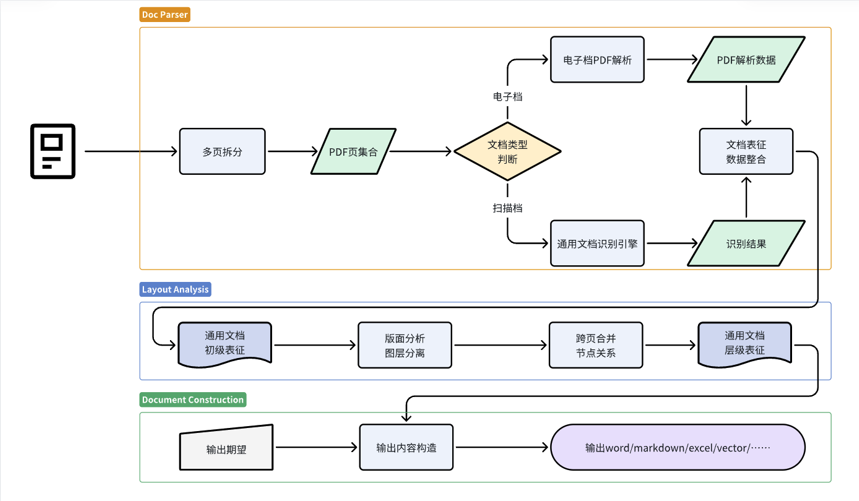
文档解析技术能够自动识别和提取文档中的文字信息,包括段落、句子、单词、标点符号等。通过自然语言处理(NLP)技术,可以进一步对文本进行分词、词性标注、命名实体识别等操作,为后续的数据处理和模型训练提供丰富的语义信息。

核心诉求
- 阅读顺序还原准确
- 元素识别准确,尤其是表格、段落、公式、标题
- 识别速度快
- 支持论文等多种排版文档
现有大模型文档解析问题
- 表格/无线表无法解析/错乱
- 按照阅读顺序解析
- 无法解析扫描版/图片版文档
- 文档编码出错误
典型技术难点
1. 版面检测

技术难点:文档可能具有复杂的布局和格式,包括文本、图像、图形、表格等多种元素,这些元素的布局和排列方式各不相同,使得版面检测变得复杂。
技术挑战:需要开发先进的图像处理技术和深度学习算法,以准确识别文档中的不同元素,并确定它们在文档中的位置和关系。此外,还需要考虑文档的多样性,包括不同的字体、颜色、大小等。
2.阅读顺序还原
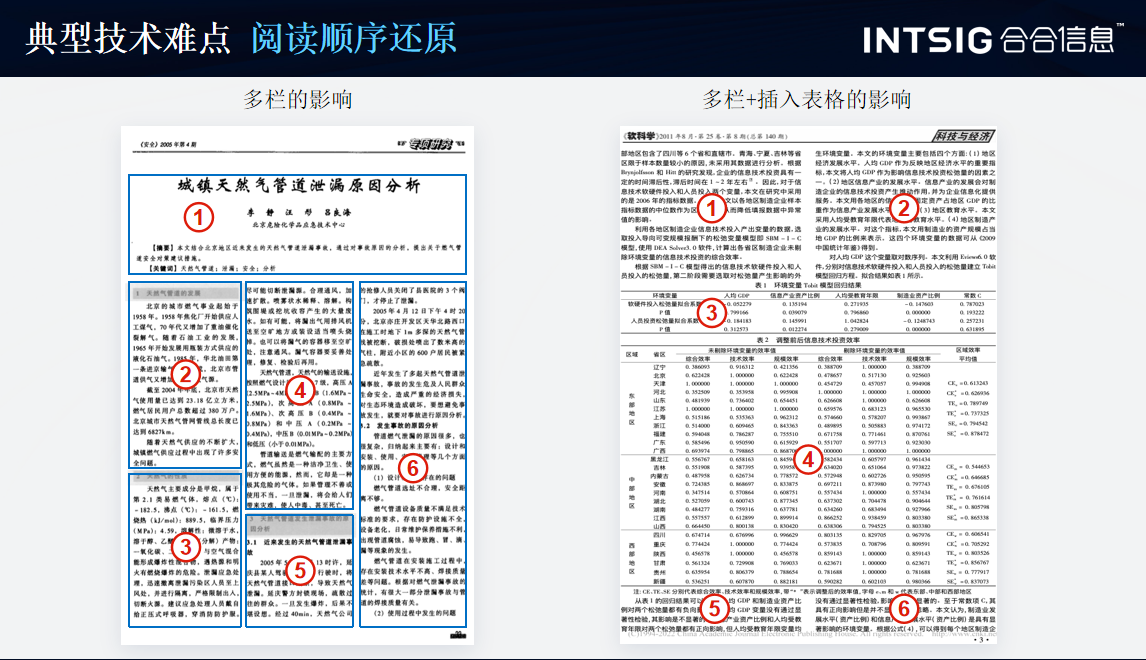
技术难点:在一些复杂的文档中,如古籍或特殊格式的文档,文字的排列方式可能不符合常规的从左到右、从上到下的阅读顺序,这增加了阅读顺序还原的难度。
技术挑战:需要利用自然语言处理技术和上下文信息,结合文档的版面结构和元素关系,来推断出正确的阅读顺序。此外,还需要处理可能存在的噪声和干扰信息。
3.表格还原
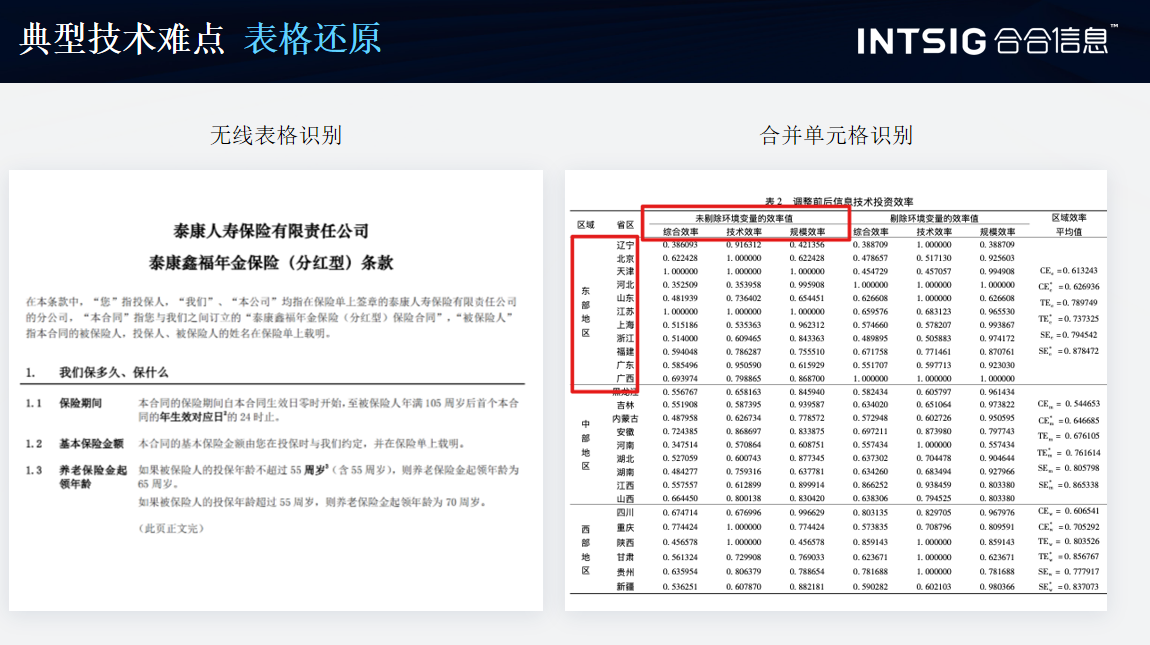
技术难点:表格通常包含大量的数据和结构信息,而且表格的布局和样式各异,这使得表格还原成为一个具有挑战性的任务。
技术挑战:需要开发高精度的表格检测和识别算法,以准确识别表格的边界、行、列和单元格等元素。同时,还需要考虑表格内部的数据结构和关系,以便将表格还原为可编辑和可分析的形式。
4.公式识别

技术难点:公式通常包含复杂的数学符号、运算符和表达式,而且公式的排版和布局也各不相同,这使得公式识别成为一个困难的任务。
技术挑战:需要开发专门的公式识别和解析算法,以准确识别公式中的各个元素和符号,并理解它们之间的关系和含义。此外,还需要考虑公式的多样性和复杂性,以及可能存在的排版和布局差异。
二、合合信息TextIn文档解析技术
合合信息TextIn文档解析技术采用深度学习、自然语言处理(NLP)和计算机视觉(CV)等先进技术,能够自动从各类文档中提取、识别和理解关键信息。专门用于处理和分析各种格式的文档数据。它为我们展示了一套文档解析方法,包括文档拆分、基础表征和文档重建三部分,旨在将多元异构的文档转化为大模型可理解的形式。
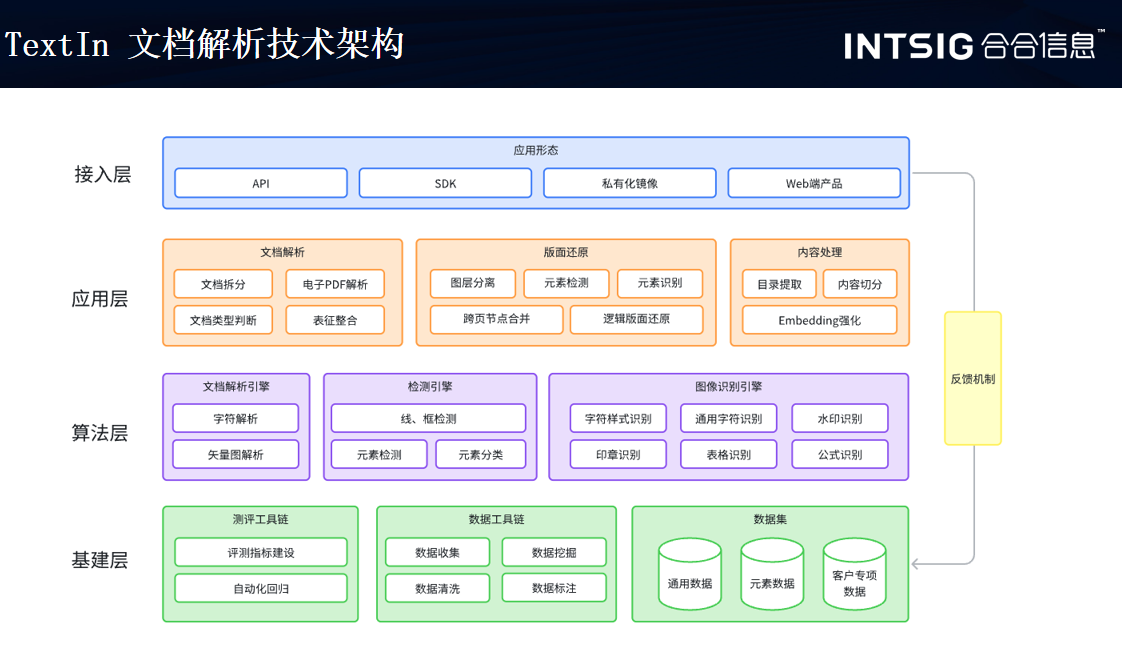
版面分析是文档图像还原的核心,通过解决版面分析的痛点,合合信息基于深度学习的方法将图像文档以数字化的手段更精准地转化为文档数据,应用于多种使用场景、提升工作效率。在文档处理过程中,合合信息的关键技术Layout-engine 和 Catalog-engine 是两个重要的组件,它们各自承担着不同的角色和功能。
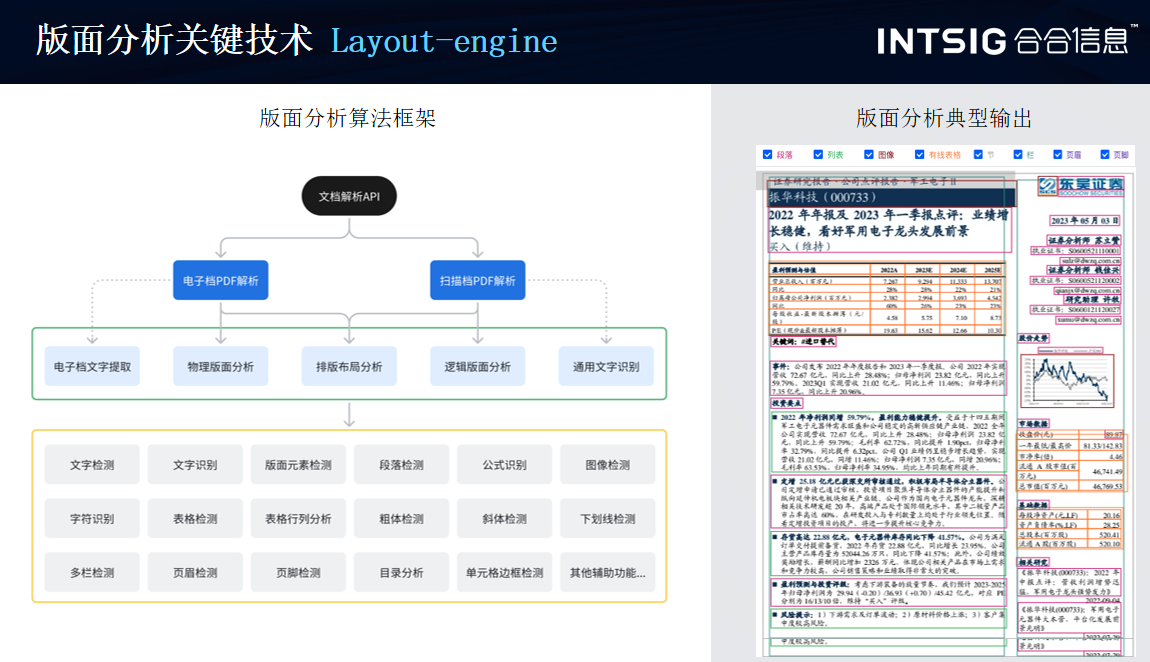
Layout-engine 是版面分析的核心引擎,负责自动检测和识别文档中的版面元素及其布局。
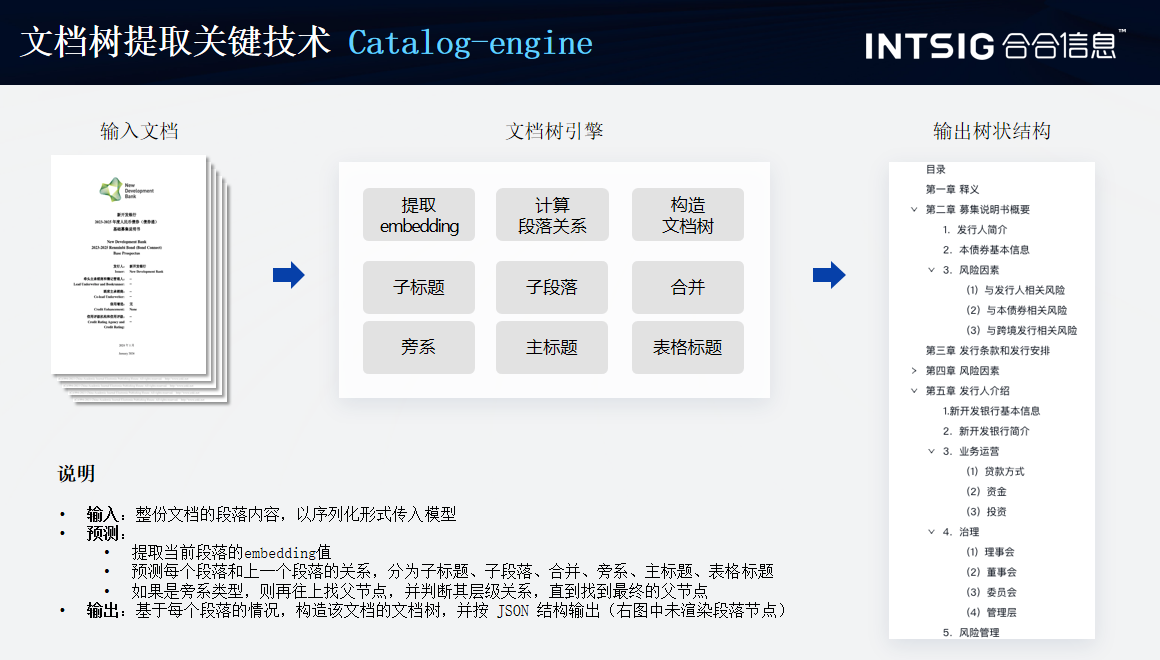
Catalog-engine 在版面分析中扮演着目录或索引的角色,用于管理和组织识别出的版面元素。
技术特点
- 高精度:TextIn采用先进的深度学习模型,对文档的识别和信息提取具有很高的准确率。它能够处理各种复杂场景下的文档数据,确保信息的准确性。
- 高效率:TextIn具备快速处理大量文档的能力,可以在短时间内完成大量数据的解析和处理。这使得用户能够更快速地获取所需信息,提高工作效率。
- 易用性:TextIn提供了简单易用的API接口和可视化界面,方便用户进行集成和定制。用户可以根据自己的需求快速构建适合自己的文档解析系统。
- 可扩展性:TextIn支持多种语言和字符集,具有良好的可扩展性。用户可以根据需要添加新的语言模型和字符集,以适应不同场景下的文档处理需求。
技术演示
TextIn支持对多种格式的文档进行识别,包括扫描件、图片、PDF等。它能够自动检测文档中的文本、图像、表格等元素,并进行高精度识别。
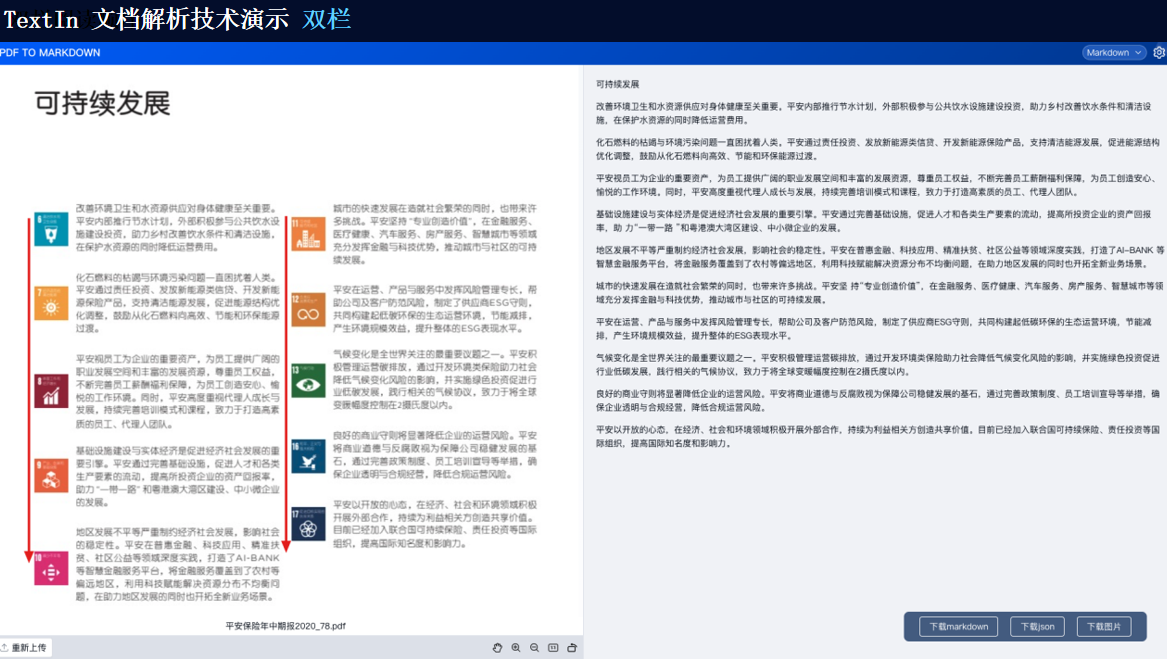
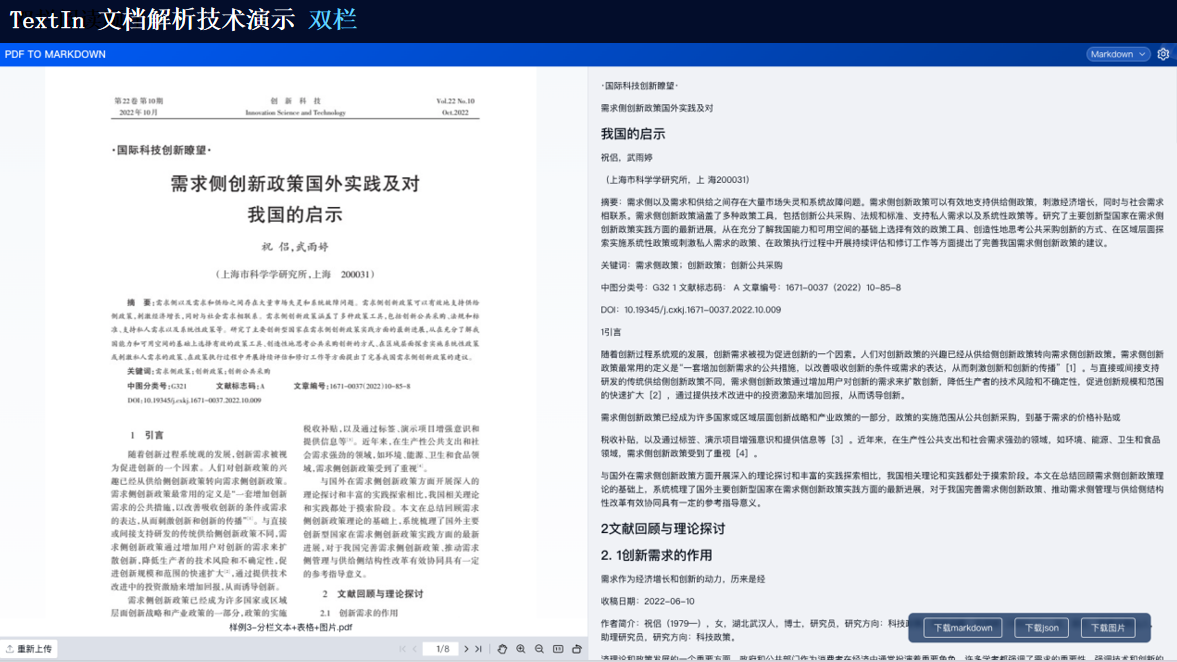
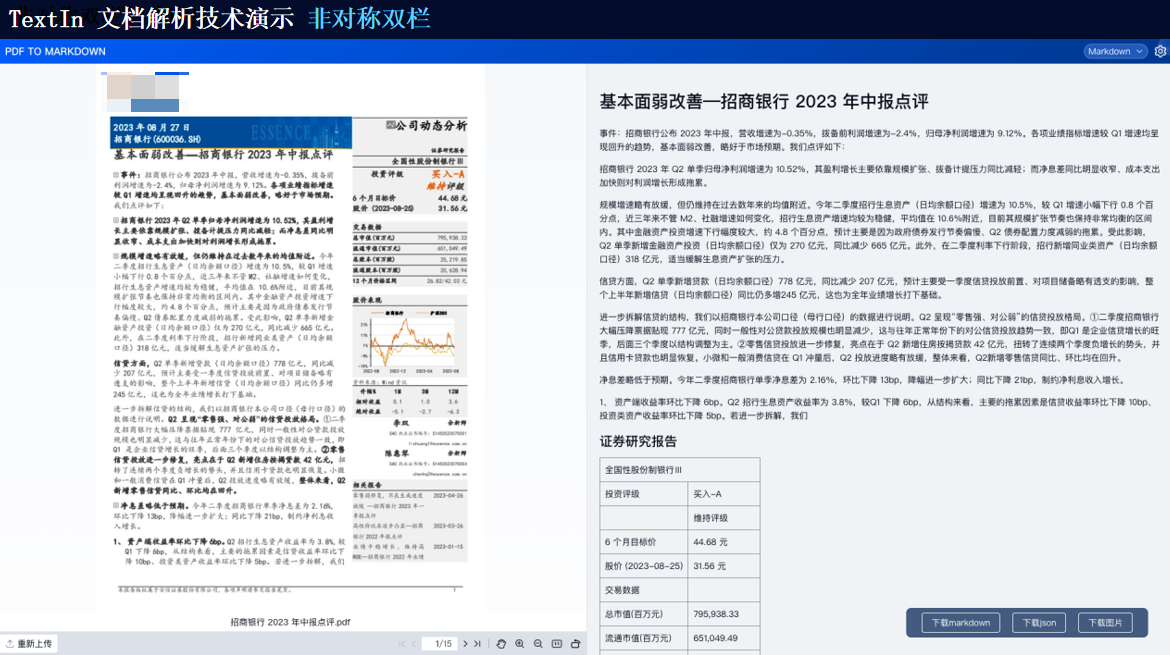
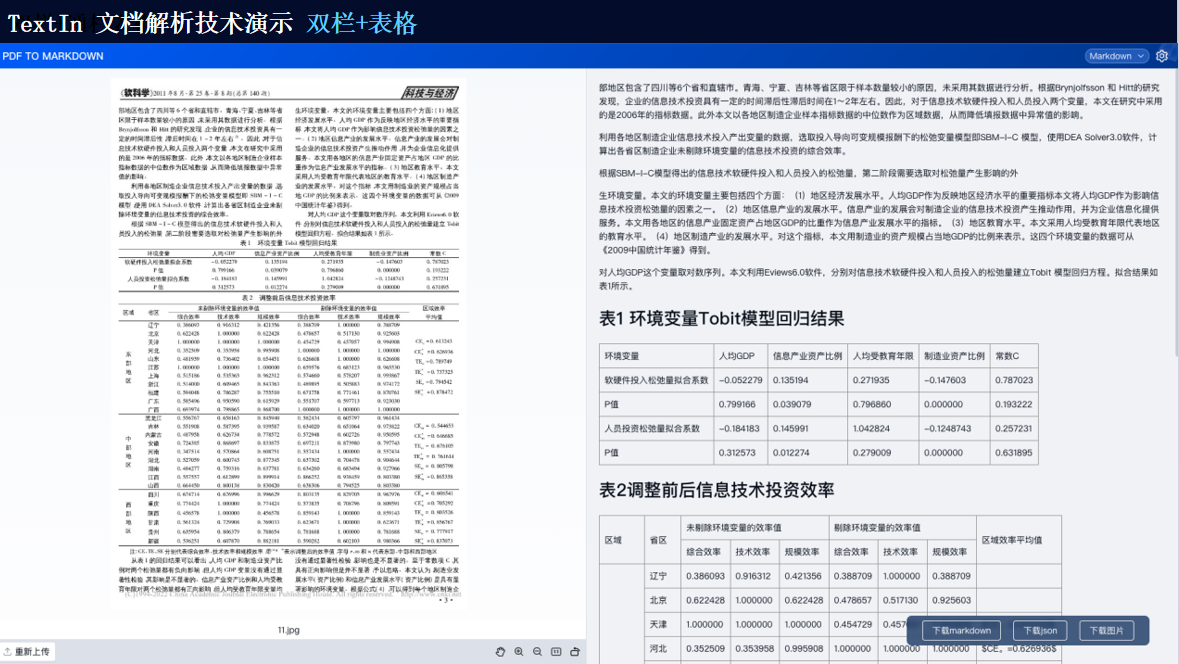
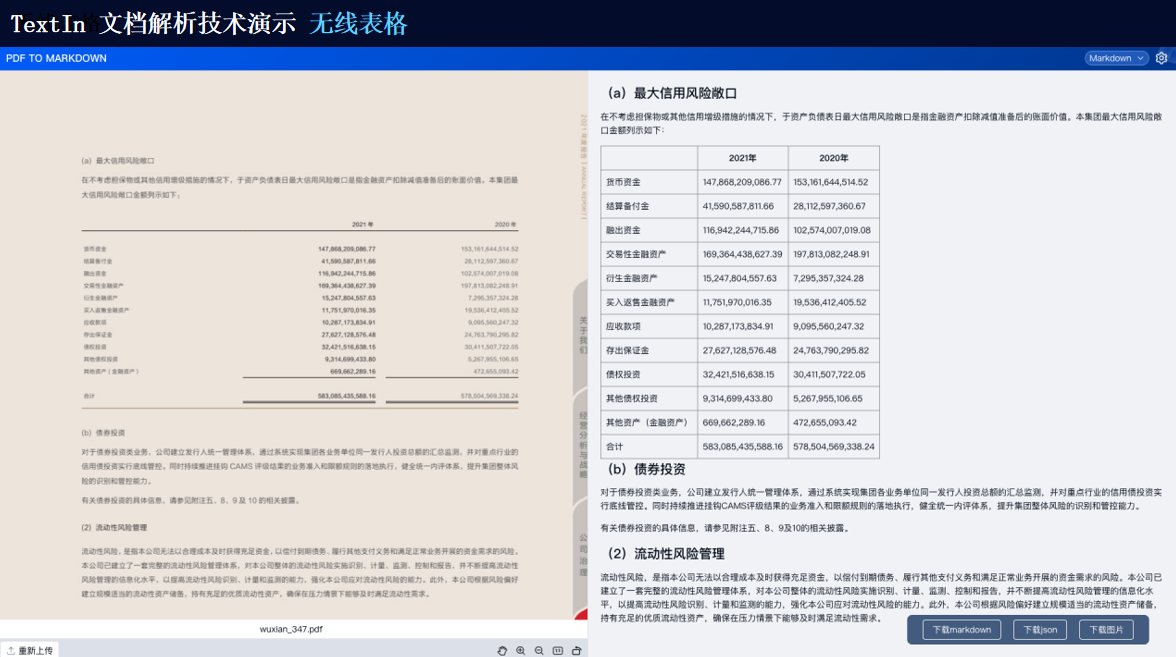
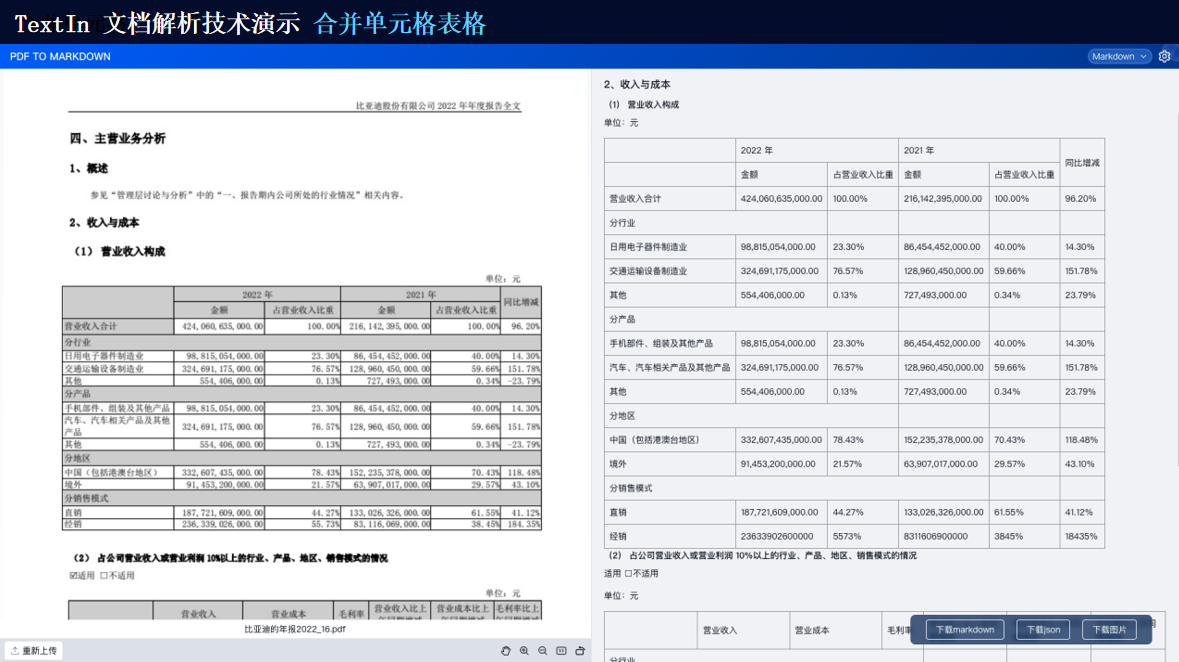
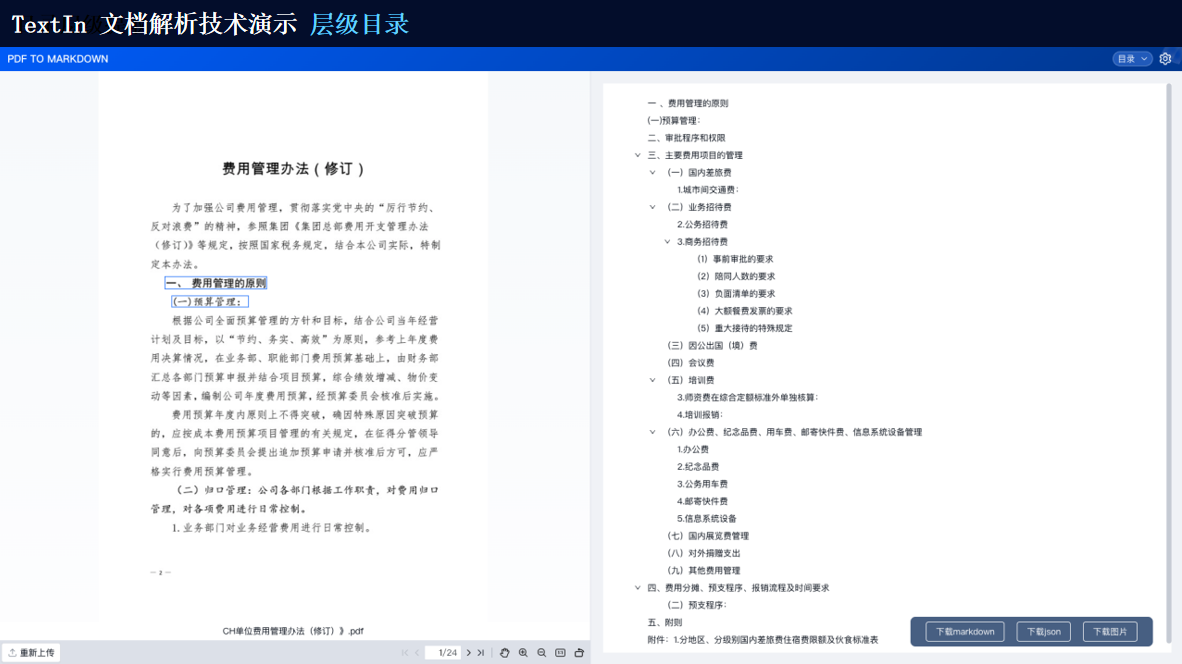
由此可见,TextIn能够处理多种类型的复杂格式文档以及跨语言文档等。通过先进的图像识别、自然语言处理和深度学习技术,它能够为我们提供高效、准确的文档处理和分析服务,满足各种应用场景的需求。
文档解析技术+大模型演示
将文档解析技术与大模型结合使用,可以充分发挥两者的优势,实现更高效、更准确的文档处理。

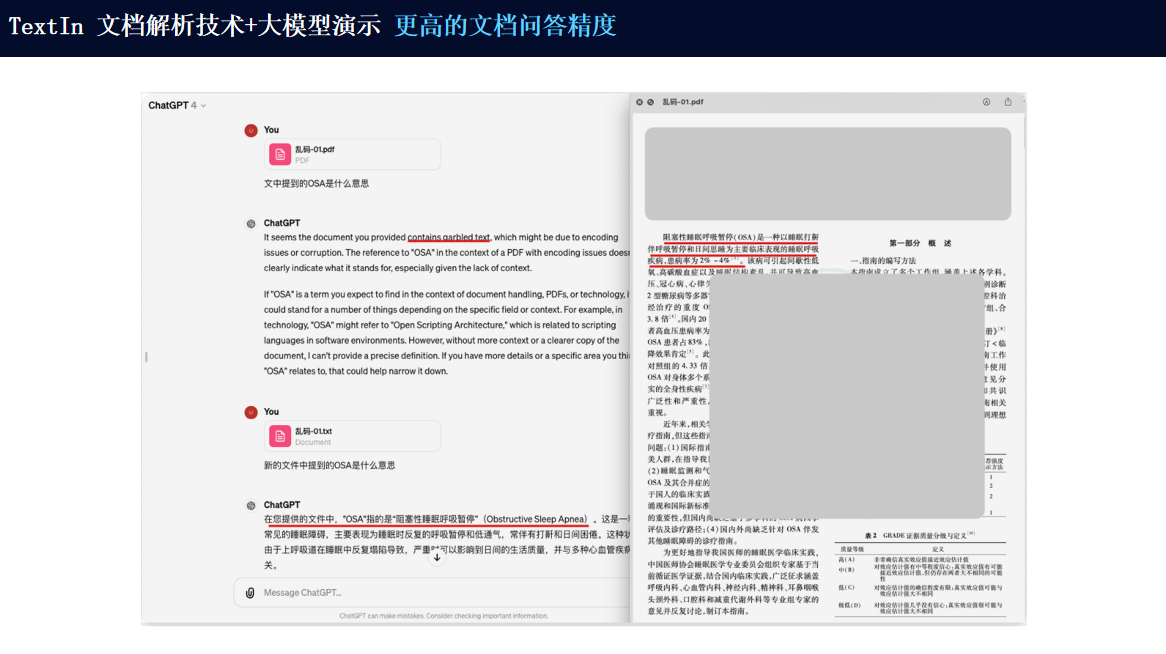
由此看来,无论您是在哪个行业领域工作,都可以考虑使用强大的TextIn来提高您的工作效率和质量。
三、文本向量化技术
向量化技术是将文本、图像、音频等模态数据转化为数值向量的过程。这些数值向量可以作为机器学习模型的输入,从而实现多模态数据的融合和处理。
文本向量化技术可以将文本数据转化为数值向量。常见的文本向量化方法包括词袋模型(Bag of Words)、TF-IDF、Word2Vec、BERT等。这些方法能够将文本中的单词或句子转化为高维向量空间中的点,从而方便进行相似度计算、分类、聚类等操作。
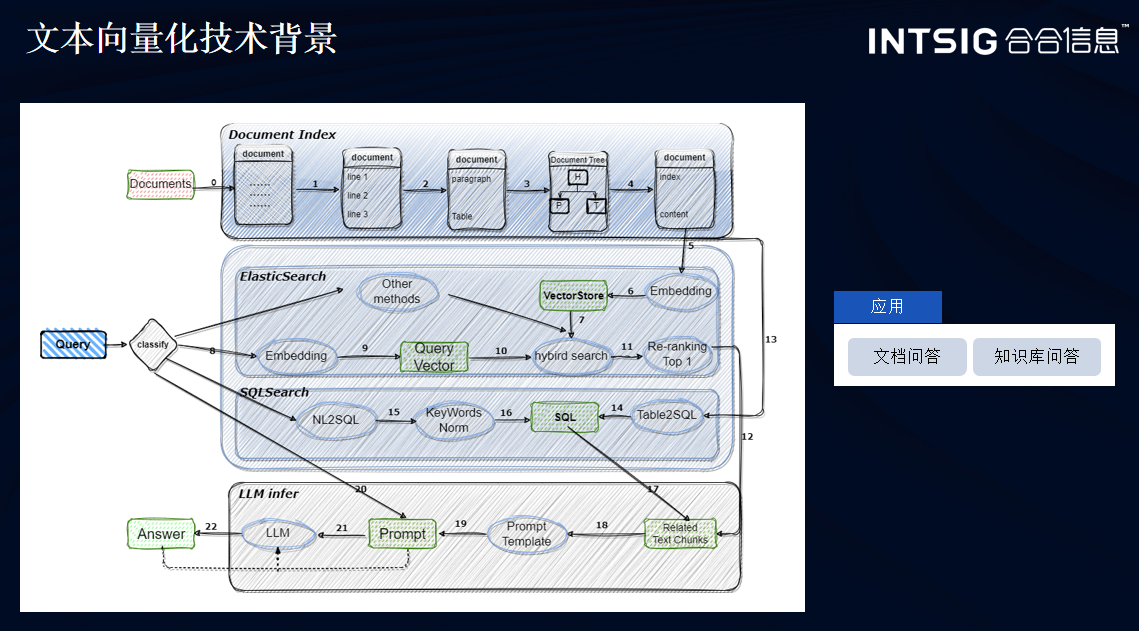
文本向量化模型
文本向量化模型是自然语言处理(NLP)中的一项核心技术,它可以将单词、句子或图像特征等高维的离散数据转换为低维的连续向量,从而将文本数据转换为计算机能够处理的数值型向量形式。
近期,合合信息发布了文本向量化模型acge_text_embedding(简称“acge模型”),获得MTEB中文榜单(C-MTEB)第一的成绩,从 Chinese Massive Text Embedding Benchmark 中可以看到目前最新的针对中文海量文本embedding的各项任务的排行榜,针对不同的任务场景均有单独的排行榜。
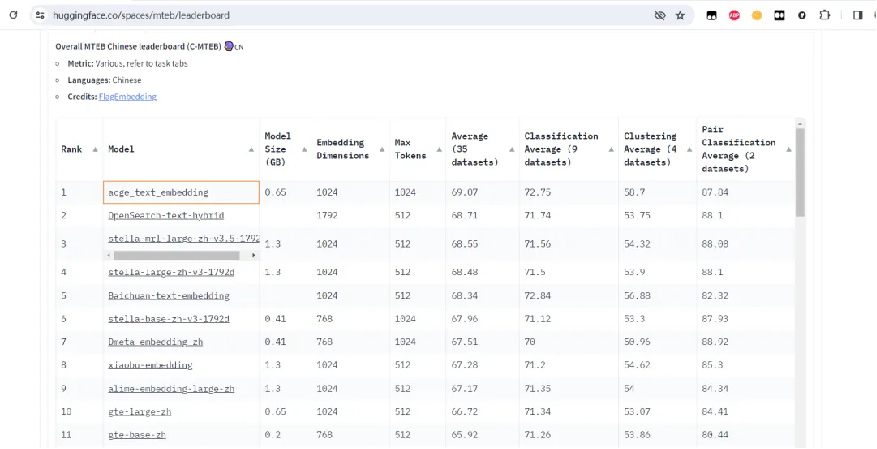
此次合合信息的acge模型,荣获的就是C-MTEB榜单的第一。 相关成果将有助于大模型更快速地在千行百业中产生应用价值。
结语
文档解析与向量化技术在加速多模态大模型训练与应用中发挥着重要作用。通过这些技术,我们可以更高效地处理多模态数据,提高模型的性能和准确性,并推动人工智能技术的发展和应用。
合合信息是一家人工智能及大数据科技企业,基于自主研发的智能文字识别及商业大数据核心技术,为全球C端用户和多元行业B端客户提供数字化、智能化的产品及服务。
欢迎各位感兴趣的朋友访问 合合信息旗下的OCR云服务产品——TextIn的官方网站,了解更多关于智能文字识别产品和技术的信息,体验智能图像处理、文字表格识别、文档内容提取等产品,更多惊喜等着你哦,快来试试吧:合合信息TextIn智能文字识别产品
销售数据分析)


 文件上传)















