从 GPS 数据中捕捉城市休闲热点:空间异质性视角下的新框架
原文:Capturing urban recreational hotspots from GPS data: A new framework in the lens of spatial heterogeneity
1. 背景与意义
- 城市娱乐活动的重要性:
- 娱乐活动是城市生活的关键组成部分,对居民生活质量和社会经济文化发展具有深远的影响。
- 合理布局娱乐活动空间有助于提升居民生活品质、促进社会交往、推动城市经济繁荣、增强城市吸引力与竞争力。
- 准确识别城市娱乐热点区域对城市规划者和管理者至关重要,可为城市娱乐设施布局优化、空间品质提升和可持续发展提供决策支持。
- 城市空间异质性:
- 城市空间具有复杂性和多样性,娱乐活动分布呈现出显著的空间异质性,即存在大量低密度区域和少量高密度的娱乐热点区域。
- 这种空间分布特征反映了城市居民在娱乐场所选择上的集中偏好以及城市空间资源的不均衡配置。
- 传统娱乐热点识别方法常忽略空间异质性特征,导致热点界定和分析存在局限性。
- 现有方法的局限性:
- 早期研究依赖统计数据和问卷调查等方式了解居民娱乐行为和偏好,但这些方法在时间和空间分辨率上较低,难以捕捉娱乐活动的精细空间分布。
- 随着技术发展,基于位置的大数据(如GPS轨迹数据、社交媒体签到数据等)为娱乐热点识别提供了新契机。
- 现有基于大数据的热点识别框架多直接套用通用聚类算法(如K-means、DBSCAN等),这些算法处理具有空间异质性的地理数据时,需人工预定义关键参数,缺乏对数据空间特征的自适应性考量,导致热点边界不合理、聚类结果不准确等问题。
- 新框架的提出与优势:
- 该研究提出了结合空间异质性理论和GPS轨迹数据的新框架,以更精准、高效地识别城市娱乐热点。
- 新框架可充分发挥GPS轨迹数据时空分辨率优势,融入空间异质性概念,更好地揭示娱乐活动在城市空间中的聚集模式和分布规律。
- 为城市规划者和决策者提供更科学、准确的娱乐热点分布信息,助力优化城市娱乐设施布局、提升城市空间品质、促进城市可持续发展。
- 理论意义:
- 拓展空间异质性理论在城市娱乐领域的应用,丰富城市地理学和空间分析理论体系。
- 通过与传统聚类方法对比分析,为地理空间数据聚类分析提供新思路和方法,推动地理信息科学等相关学科发展。
- 深入探讨娱乐热点,为理解城市空间中人类活动模式和空间组织规律提供新视角,为相关领域未来研究奠定基础。
- 实践意义:
- 为城市规划者和管理者提供更准确的娱乐热点分布信息,助力优化城市娱乐设施布局和提升城市空间品质。
- 促进城市可持续发展,增强城市吸引力和竞争力,提升居民生活质量。
- 推动城市规划与管理向科学化、精细化方向发展,为城市娱乐系统的重新设计和改进提供新的思路和方法。
2. 研究方法
-
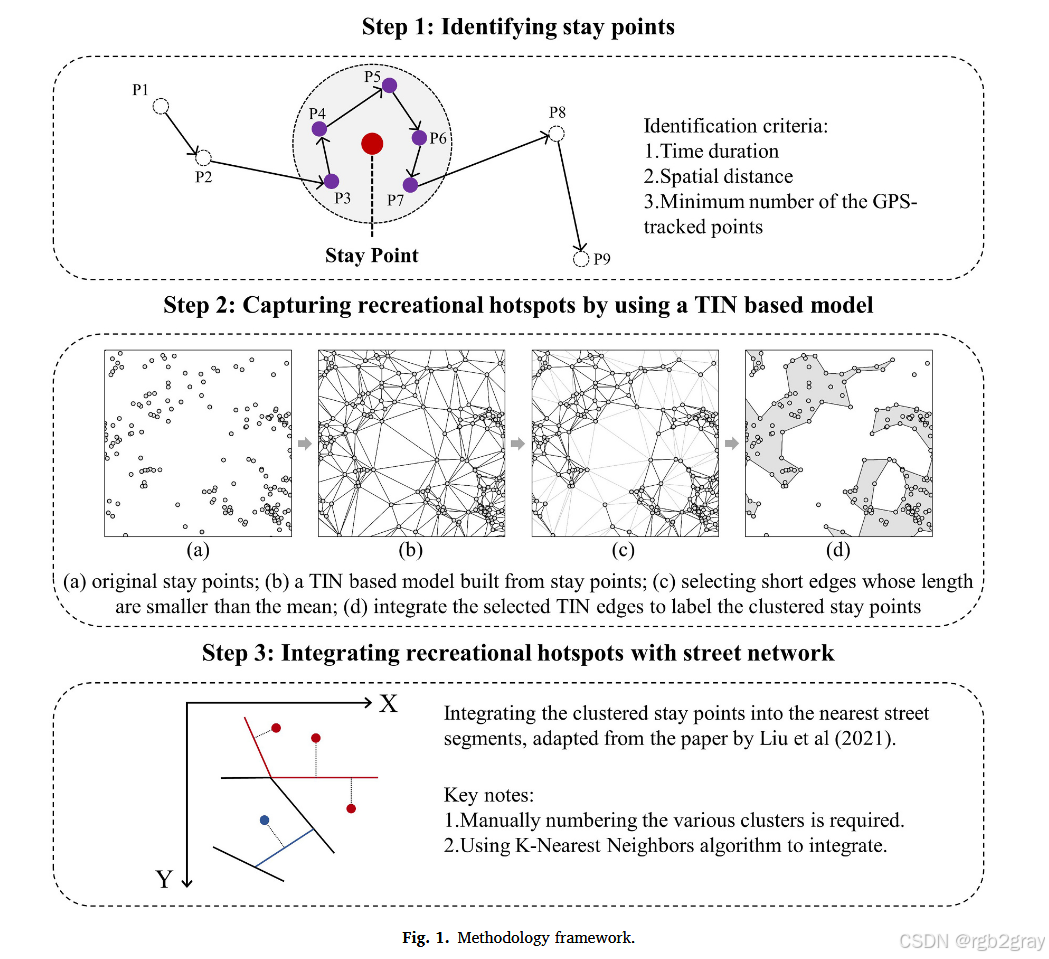
框架建立:基于GPS轨迹数据,构建了一个包含三个步骤的框架来有效捕获娱乐热点。
- 提取停留点:首先从个体的轨迹中提取停留点。停留点是指个体在某个空间内停留较长时间的活动点,它具有时空双重意义。通过特定的算法和条件(如空间距离和时间间隔的阈值)来判断轨迹中的停留点,并计算出这些停留点的坐标和时间戳。
- 基于TIN模型的聚类:将提取出的停留点转换为三角不规则网络(TIN)模型,并利用TIN边长来描述点的密度。根据空间异质性理论,城市中的娱乐活动呈现出重尾分布特征,因此可以通过统计TIN边长的分布来识别高密度区域。具体来说,通过计算边长的平均值,将边长分为“头”(大于平均值)和“尾”(小于平均值)两部分,以此来划分高密度和低密度区域。此外,还采用ht-index等指标来衡量数据的重尾层次,进一步验证空间异质性。
- 生成热点并整合街段:最后,将聚类后的停留点(即热点)与其相邻的街段进行整合。街段作为城市空间的基本单元,能够为娱乐热点的定义提供更符合实际情况的空间载体。通过将热点与街段相结合,可以更准确地反映娱乐活动在城市中的实际分布,并为后续的规划和管理提供依据。
-
关键概念与理论基础:
- 空间异质性:城市空间本质上是异质的,具有非均衡的空间分布特征,如人口分布、建筑密度等。这种空间异质性在娱乐活动中也得到了体现,即娱乐活动在城市中呈现出明显的聚集模式,形成少数高密度的热点区域和大量低密度的区域。这种分布特征可以通过重尾分布(如幂律分布)来描述,因此在识别娱乐热点时需要充分考虑这一特性。
- 停留点提取:停留点的提取是基于个体轨迹数据中的时空信息。通过设定空间距离和时间间隔的阈值条件,判断轨迹中的停留行为,并计算出相应的停留点坐标和时间戳。这一过程有助于从大量的轨迹数据中筛选出与娱乐活动相关的停留点,为后续的聚类分析提供基础数据。
- 基于TIN模型的聚类:TIN模型是一种用于表示不规则地形表面的几何模型,其边长可以反映点之间的密度差异。在娱乐热点识别中,通过构建TIN模型并分析边长的分布特征,可以有效地识别出高密度的停留点区域,即娱乐热点。这种方法不仅考虑了空间异质性,还能够利用几何模型的特性来准确划分热点边界。
- 街段整合:街段整合的目的是将聚类后的热点与城市街道网络相结合,使其更符合真实的城市场景。通过将热点整合到街段中,可以更好地反映娱乐活动与城市空间结构之间的关系,同时也为城市规划和管理提供了更直观、更实用的空间信息。
3. 实验与结果
- 案例选择:在中国的三个典型城市区域开展实证研究,即广州老城区、上海浦东新区核心区和天津滨海新区核心区。这三个区域在城市发展水平、功能布局和娱乐活动类型等方面具有一定的代表性,能够为验证新框架的有效性提供丰富的数据基础。
- 数据来源与预处理:所使用的GPS数据主要来自一个名为“2bulu”的户外娱乐网站/应用程序,该平台包含大量由用户分享的轨迹数据。在数据预处理阶段,研究者对数据进行了筛选和清洗,以确保数据的准确性和相关性。具体步骤包括:选择与娱乐活动相关的轨迹类型或标签;对选定的轨迹进行人工复查;校准GPS定位信息等。
- 空间异质性验证:在进行热点识别之前,对三个案例的停留点进行重尾分布检查。结果表明,所有案例的TIN边长均呈现出厚尾分布特征,ht指数均远大于阈值3,这验证了娱乐停留点在空间分布上具有显著的异质性,符合研究的预期和理论基础。
- 热点识别结果:
- 广州老城区:娱乐热点主要集中在中西部区域,而靠近珠江新城的东部区域热点相对较少。此外,珠江北岸的热点密度高于南岸,除了南岸的中山大学校园内有一些明显的热点。这反映出广州老城区的娱乐活动主要集中在传统商业区和文化教育机构附近。
- 上海浦东新区核心区:娱乐热点形成了沿黄浦江东岸的娱乐“带”,包括多个热点,如滨江公园、陆家嘴金融区等。同时,在上海国际旅游度假区内也有几个相邻的热点,如迪士尼乐园及其周边设施。这显示出上海浦东新区的娱乐活动与城市滨水空间和大型旅游项目的分布密切相关。
- 天津滨海新区核心区:娱乐热点分布较为集中,主要集中在新区的商业CBD,形成明显的单中心模式。核心区域外的热点则较为稀疏。这表明天津滨海新区的娱乐活动主要围绕着核心商务区展开,可能与其城市规划和功能布局有关。
- 结果验证:通过将识别出的热点与实际城市功能区进行叠加分析,发现大部分娱乐热点位于大型公共空间内,如公园、广场、游乐园、历史文化街区和商业综合体等。这与城市居民对娱乐空间的偏好一致。同时,研究还与其他学者在同一地区的研究结果进行对比,发现具有一致性,进一步证明了新框架的可靠性和有效性。此外,相关政府文件和发展规划也为研究结果提供了支持,例如上海国际旅游度假区的发展规划等。
4. 方法比较
- 对比方法:为了验证新框架的有效性和优越性,研究者将其与三种常用的聚类方法——K-means、DBSCAN和CFSFDP进行了比较。这些方法都是基于密度的聚类算法,在数据聚类分析中具有广泛的应用。
- 对比结果:
-
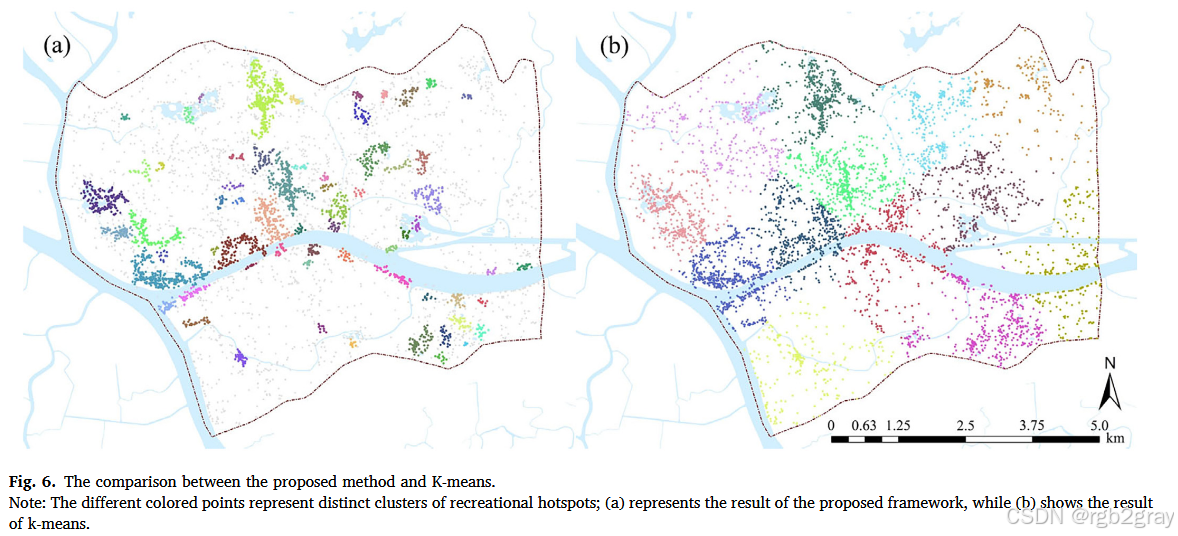
与K-means相比:K-means算法虽然能够成功将停留点分组并标记每个簇的中心,但它的主要缺点在于无法定义热点的空间范围。这是因为K-means侧重于将数据点划分为不同的簇,而不考虑簇的形状和边界。因此,它无法准确地反映娱乐热点的实际空间覆盖范围,与本研究的目的不符。
-
与DBSCAN相比:在DBSCAN算法的推荐距离阈值下,其聚类结果难以清晰地展示娱乐热点的结构。例如,在距离阈值为150米或220米时,DBSCAN会将大部分中央区域的停留点识别为一个整体的巨大热点,而无法区分出其中的细节结构。相比之下,新框架的S_Dbw指数显著优于DBSCAN,表明新框架能够更准确地捕捉热点的空间分布特征。

-
与CFSFDP相比:CFSFDP算法在三种场景下均不如新框架。在高密度簇中,CFSFDP会将自然属于一个簇的停留点分为多个簇;而在低密度簇中,其检测范围较大,导致一些停留点被误分类。此外,CFSFDP在定义簇边界方面也存在不足,无法像新框架那样清晰地划分娱乐热点的范围。通过S_Dbw测量结果也进一步证实了新框架在聚类准确性方面的优势。
-
- 讨论:综合来看,新框架在目的适用性、聚类速度和准确性方面均优于三种传统方法。其优势主要归因于对城市空间异质性的深入理解和利用。由于城市活动的聚集性,城市空间往往呈现出极不均匀的分布模式,即空间异质性。新框架通过结合空间异质性理论,能够更有效地识别出娱乐热点的分布特征,而传统的聚类方法在处理具有空间异质性的地理数据时可能存在一定的局限性。
5. 结论与未来工作
- 研究贡献:本研究提出了一种新的基于GPS轨迹数据和空间异质性理论的娱乐热点识别框架,通过在广州、上海和天津三个城市的实证研究,验证了该框架的有效性和可靠性。与传统聚类方法相比,新框架在多个方面表现出优越性,为城市娱乐系统的重新设计和改进提供了新的思路和方法。这一研究不仅拓展了空间异质性理论在城市娱乐领域的应用,还为城市规划和管理提供了更有价值的决策支持。
- 研究局限:尽管新框架在实证研究中表现出色,但研究中所使用的数据并不完全代表所有城市居民。例如,“2bulu”平台的数据可能主要集中在年轻人群体,而对老年人等其他群体的关注度不足。因此,研究结果可能存在一定的偏差。然而,需要指出的是,本研究的重点在于提出一种方法论框架,而非进行全面的实证调查。如果能够采用更全面的GPS数据源,新框架的准确性有望进一步提高,从而更好地服务于城市规划和管理实践。
- 未来研究方向:未来的研究可以从以下几个方面展开:一是深入探讨环境特征对娱乐热点空间质量的影响,例如地形、植被、气候等因素如何影响娱乐活动的分布和质量;二是引入Alexander的“生活结构”理论,从更深层次解释娱乐热点的空间分布和形成机制,为城市娱乐空间的优化提供更丰富的理论支持;三是探索新框架在其他具有空间异质性特征的地理空间主题中的应用潜力,如城市交通流量分析、土地利用变化研究等,以进一步验证和拓展该框架的适用性和有效性。
6. 其他
import pandas as pd
import numpy as np
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt# 读取GPS轨迹数据
# 假设数据包含经度、纬度、时间戳等列
columns = ['time', 'latitude', 'longitude']
data = pd.read_csv('gps_data.csv', names=columns)# 数据预处理
# 转换时间为时间戳
data['time'] = pd.to_datetime(data['time'])
data['timestamp'] = data['time'].astype(np.int64) // 10**9# 提取停留点
def extract_stay_points(data, dr=250, tr=600): # tr单位为秒stay_points = []i = 0while i < len(data):j = i + 1while j < len(data):# 计算两点之间的距离(这里简化为欧氏距离,实际应用中建议使用Haversine公式计算地理坐标距离)distance = np.sqrt((data.loc[i, 'latitude'] - data.loc[j, 'latitude'])**2 + (data.loc[i, 'longitude'] - data.loc[j, 'longitude'])**2)if distance > dr:breakj += 1# 计算停留时间duration = (data.loc[j-1, 'timestamp'] - data.loc[i, 'timestamp'])if duration >= tr and (j - i) >= 4: # 至少有4个连续点# 计算平均坐标和时间avg_lat = data.loc[i:j, 'latitude'].mean()avg_lon = data.loc[i:j, 'longitude'].mean()avg_time = data.loc[i:j, 'timestamp'].mean()stay_points.append([avg_lat, avg_lon, avg_time])i = jstay_points = pd.DataFrame(stay_points, columns=['latitude', 'longitude', 'timestamp'])return stay_pointsstay_points = extract_stay_points(data)# 聚类分析
# 使用DBSCAN算法进行聚类
coordinates = stay_points[['latitude', 'longitude']].values
db = DBSCAN(eps=0.001, min_samples=5).fit(coordinates) # eps可根据具体坐标单位调整# 可视化结果
plt.scatter(coordinates[:, 1], coordinates[:, 0], c=db.labels_, cmap='viridis', marker='o', s=50)
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.title('Clustering of Stay Points')
plt.show()

















)

