文章目录
- Embedding
- 1 概念
- 2 Q&A (1)
- 3 Positional Encoding
- 4 Q&A (2)
- ViT样例及Embedding可视化理解
- 1 简化ViT练习
- 2 CLS Token
- 3 Embedding可视化
- 4 多头注意力可视化
- Embedding技术体系结构
- 参考来源
在研究中对特征的编码和解码的原理有一些疑惑,由于我之前研究的一直是计算机视觉问题,所以仍然是以主流的图像+Transformer为例开展研究,进一步讨论如何进行特征处理。
2020年提出了Vision Transformer(简称ViT),将图像分割成多个小块(Patch),每个Patch的大小可以指定,例如16×16,然后对每个Patch进行线性投影,通过一个线性层将其转换为固定维度的向量——嵌入向量(Embedding)。 逆线性投影(线性解码) 的目标是将特征向量恢复为原始图像或其近似表示,用于图像重建或特征解码为图像或文本表示。
Embedding
1 概念
Embedding模型是RAG(Retrieval-Augmented Generation)技术的核心。也是大模型应用落地必不可少的技术。
RAG (Retrieval-Augmented Generation)是一种结合了信息检索和生成模型的技术,用于改善自然语言处理任务中的生成模型表现。
- 这项技术由两部分组成:一个检索系统和一个生成模型。
- 用户给出一个查询或问题 -> 检索系统根据输入查询从文档库中检索出最相关的几个文档片段,这些片段被选择为包含与查询最相关的信息 -> 检索到的文档片段与原始查询一起被送入生成模型,生成模型结合这些信息生成一个响应或文本输出。
Embedding模型是指将高维度的数据(例如文字、图片、视频)映射到低维度空间的过程。简单来说,embedding向量就是一个N维的实值向量,它将输入的数据表示成一个连续的数值空间中的点。大型语言模型可以生成上下文相关的 embedding 表示,可以更好地捕捉单词的语义和上下文信息。
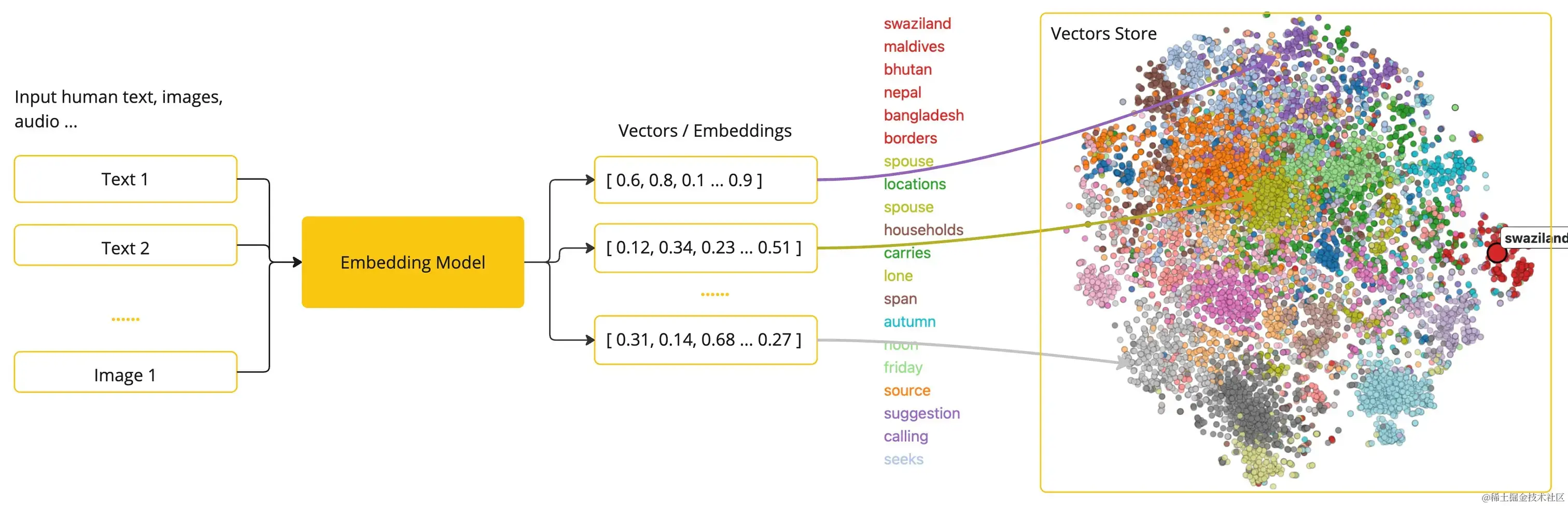
简单来说,embedding就是用一个低维的向量表示一个物体,可以是一个词,或是一个商品,或是一个电影等等。这个embedding向量的性质是能使距离相近的向量对应的物体有相近的含义,比如 Embedding(复仇者联盟)和Embedding(钢铁侠)之间的距离就会很接近,但 Embedding(复仇者联盟)和Embedding(乱世佳人)的距离就会远一些。
2 Q&A (1)
-
Embedding的必要性?
-
处理高维或复杂状态时,Embedding能有效降维和提取特征,能提升模型对任务和关系的理解,减少无效探索。
-
RGB形式是否可以看成Embedding后的结果?
-
原始数据RGB存在局限性(如对亮度敏感),高维且包含冗余。图像需要Embedding的根本原因在于,RGB像素数据虽然完整记录了图像的物理信息,但缺乏对语义特征的结构化表达。
-
RGB图像的局限性:
- 高维冗余性:一张1080p的RGB图像包含超过600万个像素点,每个像素点仅记录局部颜色信息,这种原始数据不仅计算成本高昂,还包含大量无关细节(如光照噪声、重复纹理等)。
- 语义断层:RGB像素无法直接反映图像的语义结构。虽然RGB数据精确记录了每个水果的色泽,但无法自动表达“水果”的概念,更无法理解苹果与香蕉的类别关系。
- 跨模态匹配障碍:RGB像素空间与文本、音频等其他模态的表示空间完全割裂,难以直接进行跨模态检索或生成任务。
-
图像Embedding的本质:
图像Embedding是通过深度神经网络对RGB像素的语义蒸馏,生成一个紧凑的数值向量。- 低维稠密性:典型的图像Embedding维度在128-2048之间。
- 语义拓扑结构:Embedding空间中的向量距离反映语义相似性。例如某案例中停车场图像的Embedding与“停车场”文本Embedding的余弦相似度达到0.998,而与“公园”文本的相似度仅为0.001。
- 多层级特征融合:通过卷积神经网络(CNN)或视觉Transformer,Embedding会融合从边缘、纹理到物理部件、场景的多尺度特征。
-
举例说明如何解释Embedding后的图像?
-
输入图像与预处理:假设输入为一张橘猫在草地上的RGB图像,尺寸为224×224×3。将图像切割为16×16×3的像素patch,patch的内容可能是橘猫耳朵的局部纹理、草叶边缘等,将每个patch展平为16×16×3=768维向量。
-
Transformer处理与Embedding生成:
- 添加位置编码(Positional Encoding):每个patch向量叠加可训练的位置编码,保留空间信息。左上角草地的patch编码可能为[0.1, -0.3, 0.5, …],右下角猫爪的patch编码可能为[0.8, 0.2, -0.1, …]。
- Transformer编码:模型通过注意力计算不同patch间的关联。橘猫头部patch与身体patch的注意力权重较高(语义关联),草叶patch之间因重复纹理产生中等权重(局部相似性)。
- 全局汇聚与输出:最终通过分类标识符汇聚全局特征,输出1024维图像Embedding。
embedding = [
0.23, # 维度1:可能与"毛绒质感"正相关
-1.56, # 维度2:抑制"金属反光"特征
3.12, # 维度3:激活"橘色毛发"属性
0.98, # 维度4:绿色背景强度
... # 后续维度编码更抽象语义(如"生物体""自然场景"等)
]
(我理解为输出的每一个维度都表示它的一个特征,所以维度不一定是越高越好,有些东西特征不够没办法表示)
-
Embedding如何捕捉语义信息?
-
Embedding通过神经网络将离散符号(如文字、图像)映射到低维连续向量空间,使得语义相似的实体在空间中距离相近。相似语义的实体在上下文环境中具有共现规律,例如“猫”和“狗”常出现在相似语境中,模型通过统计共现频率或预测上下文捕捉这种关联性。训练过程中,模型通过损失函数调整向量位置,使语义相关项在空间中聚集。
-
实现路径
- 卷积神经网络:通过卷积核滑动扫描图像,激活特定纹理模式,例如浅层网络捕捉边缘、颜色块,深层网络识别物体部件。全连接层将局部特征整合为图像整体表示。
- ViT:分块线性嵌入,添加可学习的位置编码后,通过多头自注意力计算块间关系。例如猫头部位的patch会与躯干patch产生高注意力权重,形成生物体结构理解。
-
监督信号设计:
- 分类任务通过标签监督驱动语义分离。
- 自监督任务通过掩码预测(BERT)、图像补全(MAE)挖掘内在结构。
-
为什么不同的卷积核和层能自动学习不同的特征而无需人为干预?
-
局部感知:不同的卷积核的初始权重不同,导致对输入图像的不同区域产生差异化响应。例如,某些核可能对垂直边缘敏感,另一些对水平边缘敏感。同一卷积核在不同位置使用相同权重,迫使该核专注于检测特定模式。
-
权值共享:通过反向传播,梯度更新促使不同核分别优化为边缘检测器(如Sobel算子)、颜色斑点检测器等低级特征提取器。深层网络通过组合低级特征学习复杂模式。冗余核(重复检测统一特征的核)可能在正则化(如L2权重衰减)下被淘汰,可以减少过拟合风险。
-
层次化网络结构:
| 网络层级 | 特征类型 | 分工机制 | 示例(以动物识别为例) |
|---|---|---|---|
| 浅层 | 边缘、纹理、颜色 | 小尺寸卷积核(如3×3)捕捉局部细节,多个核并行提取不同方向或类别的边缘。 | 毛发纹理、眼睛轮廓等 |
| 中层 | 局部结构、部件 | 大感受野卷积核(如5×5)整合多个低级特征,形成部件级表示。 | 耳朵形状、鼻子局部特征 |
| 深层 | 语义对象、全局关系 | 全连接层或全局池化聚合空间信息,结合非线性激活表达高阶语义。 | 动物类别、姿态 |
- 关键组件协同作用:
| 组件 | 功能 | 对特征分工的影响 |
|---|---|---|
| 激活函数 | 引入非线性,允许网络学习复杂函数 | 增强特征响应差异性,促进核间分工。 |
| 池化层 | 降维并保留显著特征 | 提升平移不变性,使高层核关注语义而非位置。 |
| BatchNorm | 标准化特征分布,加速训练收敛 | 稳定不同核的学习速度,避免部分核“死亡”。 |
-
如何理解池化层在特征提取中的作用?
-
平移不变性指的是当输入图像中的物体发生微小位移时,池化后的输出特征不会发生显著变化。例如数字“1”在图像中稍微平移后,经过池化层得到的特征矩阵仍然相同,这说明池化确实有助于保持特征的一致性,即使位置变化了。池化操作通过下采样减少了特征图的空间尺寸,使得后续的高层网络在处理时,感受野更大,能够捕捉更全局的信息。例如,最大池化选择局部区域的最大值,这样无论特征在区域内的具体位置如何,只要最大值存在,就会被保留。这样,高层核不再需要精确追踪每个特征的位置,而是关注这些特征的存在与否及其组合,从而更专注于语义信息。另外,池化层对微小位置变化具有鲁棒性,即使输入数据有轻微偏差,池化结果仍可能保持一致。这是因为池化窗口内的最大值或平均值并不依赖特征的具体位置,只要该特征存在于窗口内,就会被捕捉到。
-
Patch Embedding和Encoder有何区别?
-
Embedding的作用是将图像块转换为向量表示,并加入位置信息。这一步是线性的,没有复杂的交互。Embedding模块完成从像素空间到语义向量的初步映射,并为模型提供基础的局部特征表示和空间位置信息。
-
Encoder的作用是通过自注意力机制,让这些向量之间进行全局交互,提取更高层次的语义信息。通过多头自注意力(MHSA)计算图块间的关联权重,建立全局依赖关系。例如,猫耳朵图块可能与躯干图块形成高注意力权重,从而捕捉生物体结构信息。
3 Positional Encoding
位置编码(Positional Encoding)其核心目的是将位置信息注入无位置感知的自注意力机制中,使模型能够区分不同位置的元素。
Transformer的自注意力机制本质上是无序的,无法区分序列中元素的顺序。例如,输入序列“[猫, 在, 屋顶]”和“[屋顶, 在, 猫]”可能被模型视为等价。位置编码通过显式标记每个元素的位置,解决这一问题。在ViT中,图像被分割为图块(patch)序列,位置编码需保留原始图像的空间布局信息(如相邻图块的上下左右关系)。
位置编码主要分为绝对和相对两种类型。绝对位置编码包括可学习的和预定义的(如正弦函数),而相对位置编码则考虑元素之间的相对距离。
-
可学习的绝对编码(Learnable Position Embedding):ViT和BERT的默认方式,将位置编码作为可训练参数。例如,ViT中每个图块的位置编码通过随机初始化并在训练中优化。
-
正弦/余弦编码(Sinusoidal Encoding):对于序列中的每个位置 p o s pos pos、隐藏层维度 d m o d e l d_model dmodel、隐藏层中的每个维度索引 i i i、位置编码向量的第 i i i个元素 P E ( p o s , 2 i ) PE_{(pos,2i)} PE(pos,2i)和 P E ( p o s , 2 i + 1 ) PE_{(pos,2i+1)} PE(pos,2i+1)分别通过正弦和余弦函数计算:
P E ( p o s , 2 i ) = s i n ( p o s 1000 0 2 i d m o d e l ) PE_{(pos,2i)}=sin(\frac{pos}{10000^\frac{2i}{d_{model}}}) PE(pos,2i)=sin(10000dmodel2ipos)
P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i d m o d e l ) PE_{(pos,2i+1)}=cos(\frac{pos}{10000^\frac{2i}{d_{model}}}) PE(pos,2i+1)=cos(10000dmodel2ipos)
使用 2 i 2i 2i和 2 i + 1 2i+1 2i+1来区分偶数和奇数的维度, i i i应该是维度索引的一半。10000是一个常数,用来控制不同维度之间的频率差异,使得不同维度的正余弦函数具有不同的周期。
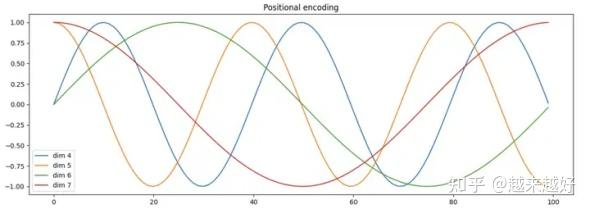
- 随位置的变化:对固定的维度 i i i来说,位置 p o s pos pos的变化将影响 P E PE PE的值。正弦和余弦函数将随着位置呈现出周期性变化,这意味着模型能够区分输入序列中token的不同位置。
- 随维度的变化:对固定位置 p o s pos pos,随着维度 i i i的增加,正弦和余弦函数的频率会降低,周期会变长。因此,较低维度具有短的周期,即在较小的位置范围内完成一个周期,换句话说其变化迅速,对小的位移敏感,也就是即使是相邻位置,位置编码的差异也会很大,这有助于模型识别相邻位置间的细微差异。相反,较高维度具有较长的周期,在较大的位置范围内才完成一个周期。变化缓慢,对小的位移不敏感,这能帮助模型感知全局位置关系,捕获长距离依赖。这种多尺度的编码使得Transformer模型能够同时捕捉全局和局部的位置信息。
- 远程衰减:对于两个相同的词向量,如果它们之间的距离越近,则他们的内积分数越高反之则越低。(词向量的内积分数就是两个词每个维度PE乘积之和) 我们随机初始化两个向量 x x x和 y y y,将 x x x固定在位置0上, y y y的位置从0开始逐步变大,依次计算内积。我们发现随着 x x x和 y y y的相对距离的增加,它们之间的内积分数震荡衰减。
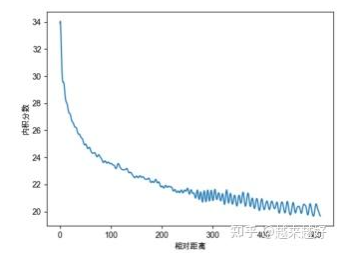
- 外推能力:指模型在处理比训练时更长的序列时仍能保持一定的性能。正余弦函数的周期性使得位置编码在超出训练长度时仍能生成合理的编码值。内积的震荡衰减特性减少了远距离噪声干扰,使模型更关注局部上下文,同时保留对长距离依赖的微弱信号。这种平衡增强了模型对未见过序列长度的适应性。

- 图像相对位置编码(iRPE):编码元素间的相对距离,而非绝对位置。使用分段函数(Piecewise Function)映射相对距离到有限索引,减少计算量;避免远距离位置信息丢失,例如,通过指数或对数函数对不同距离的像素分配差异化的注意力权重,增强长程依赖的捕捉能力。通过交叉法(Cross)和乘积法(Product)编码水平和垂直方向,提升对物体结构的理解。
- 无向方法:
- 欧氏距离法:计算像素间的欧氏距离并映射到编码空间。
- 量化法:对欧氏距离四舍五入后离散化,减少近邻位置映射冲突。
- 有向方法:
- 交叉法(Cross Method):分别计算水平(x轴)和垂直(y轴)方向的相对位置编码,再进行加性融合。
- 乘积法(Product Method):直接对二维坐标进行联合编码,生成更细粒度的位置特征。
- 无向方法:
4 Q&A (2)
- Embedding和PE直接相加不会导致冲突吗?
(Q&A里所有PE问题的解答如果看不明白需要先看下一节关于Positional Encoding的介绍) - 在之前Transformer的学习中我已经了解到输入Attention的是位置编码和嵌入向量直接相加,它们的维度相同,所以可以逐元素相加,相加后的向量既包含语义信息又包含位置信息。词嵌入表示语义信息,位置编码表示顺序信息,二者属于正交特征空间。相加操作相当于将两种信息线性叠加,是信息融合而非混淆。
(关于正交向量详见【机器学习】强化学习(3)——深度强化学习的数学知识 )
两个向量相加后形成的新向量在正交特征空间中依然保持明确的几何和物理意义。例如,在物理中的力或速度的合成,正交分量的相加不会导致信息混乱,而是通过线性组合保留各自方向的独立贡献。
- 是否会出现不同向量相加结果相同的情况?比如,两个不同的词嵌入加上不同的位置编码,结果却一样。高维空间中的概率问题,当嵌入维度过高时,这种碰撞的概率极低。
- 是否会出现位置编码的周期性导致相同编码码的问题?正弦和余弦函数的设计通过不同频率的组合,确保每个位置有唯一的编码。虽然周期函数会有重复,但不同维度的频率是几何级数分布的,最小公倍数非常大,所以实际应用中几乎不会出现重复。
以单词“wolf”为例,假设通过Embedding生成了3维向量Embedding(wolf) = [0.5, -1.2, 0.8],这一向量由模型训练生成,捕捉了“wolf”的语义特征(如动物、野外、肉食等)。假设“wolf”在句子中的位置是第5位(从0开始计),使用Transformer的正弦/余弦位置编码公式生成3维PE值:
PE(pos=5, d_model=3) = [sin(5 / 10000^(0/3)) = sin(5) ≈ 0.4,cos(5 / 10000^(0/3)) = cos(5) ≈ 0.9,sin(5 / 10000^(2/3)) = sin(5/21.54) ≈ 0.2
]
简化后为:PE(5) = [0.4, 0.9, 0.2]。将词嵌入与位置编码逐元素相加,Embedding(wolf) + PE(5) = [0.5 + 0.4, -1.2 + 0.9, 0.8 + 0.2] = [0.9, -0.3, 1.0],两个向量内积为0。
-
生成编码的时候如何保证两者正交?
-
正弦和余弦交替排列,使相邻维度的位置编码变化显著(如红白交替的竖条可视化),增强正交性。
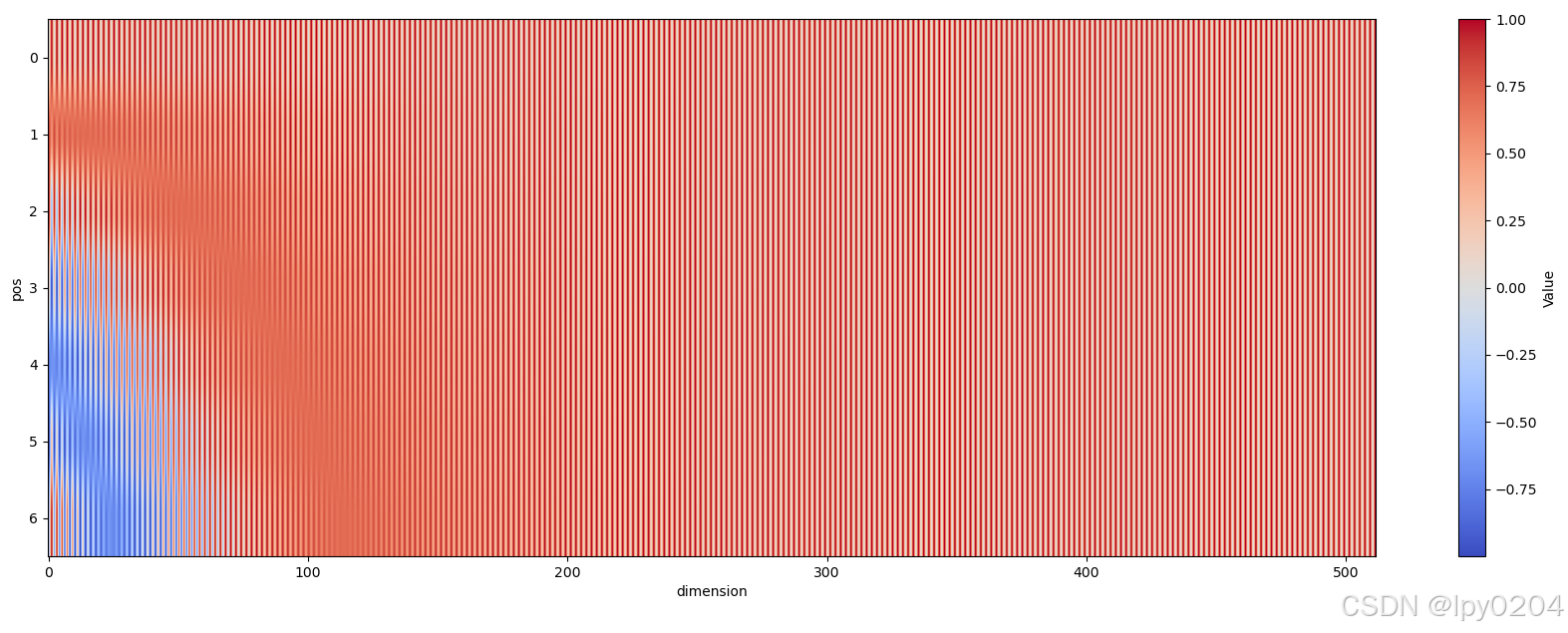
从可视图中也可以看出,当从左向右看时,会有交替出现的红白竖条,这便是正弦函数和余弦函数交替出现的结果,能帮助模型更加清晰地分辨相邻两个维度。如果只采用正弦函数,那么相邻维度之间的界限就被模糊了。 -
Embedding+PE如何分离?
词嵌入与位置编码相加得到新的向量后,模型在学习特征和位置的时候需要再把它们还原到两个正交空间中吗?如果不还原,如何拆分特征编码和位置编码?如果还原,怎么确定是哪两个正交空间?所有词的两个正交空间最后都会一样吗?那会不会导致误差? -
词嵌入和位置编码相加后,输入到模型中,通过自注意力机制进行处理。模型在训练过程中通过线性变换 W Q / W K / W V W_Q/W_K/W_V WQ/WK/WV自动学习将相加后的向量分解到不同的特征空间,而不需要显式还原。例如,自注意力机制中的 Q Q Q、 K K K、 V V V矩阵的投影可能隐式地将混合后的向量分解到不同的子空间,捕捉语义和位置信息。
ViT样例及Embedding可视化理解
1 简化ViT练习
详见【深度学习】计算机视觉(14)——Transformer
2 CLS Token
练习中注意到有一个CLS Token,即Class Token。我们将原始图像切分成共8个小图像块,最终的输入序列长度却是9,这里增加的一个向量就是cls_token。
在 Vision Transformer(ViT)中,CLS Token 用于提取全局图像的特征表示,替代了 CNN 中常用的全局池化操作。
将8个向量输入Transformer结构中进行编码,我们最终会得到8个编码向量,可对于图像分类任务而言,我们应该选择哪个输出向量进行后续分类呢?这8个向量都只能代表对应的patch,但是如果嵌入向量Class Token(向量0)与8个向量一起输入到 Transformer结构中,输出9个编码向量,然后用这个Class Token进行分类预测即可。
这样做有以下好处:
- 该token随机初始化,并随着网络的训练不断更新,它能够编码整个数据集的统计特性;
- 该token对所有其他token上的信息做汇聚(全局特征聚合),并且由于它本身不基于图像内容,因此可以避免对sequence中某个特定token的偏向性;
- 对该token使用固定的位置编码能够避免输出受到位置编码的干扰。ViT中作者将class embedding视为sequence的头部而非尾部,即位置为0。
3 Embedding可视化
4 多头注意力可视化
Embedding技术体系结构
Word2Vec等
[欢迎指正]
参考来源
@AIGC
大模型入门:Embedding模型概念、源码分析和使用示例
什么是embedding?详解
正弦-余弦位置编码
Transformer中的位置编码
vit 中的 cls_token 与 position_embed 理解







)


)


)



:从源码出发,探索多模态VL模型的推理全流程)

