目录
前言
图的概念
1. 顶点和边
2. 图的分类
3. 图的基本性质
图的存储
邻接矩阵存图
邻接表存图
图的基本遍历
拓扑排序
拓扑排序是如何写的呢?
1. 统计每个节点的入度
2. 构建邻接表
3. 将所有入度为 0 的节点加入队列
4. 不断弹出队头节点,更新其相邻节点的入度
5. 判断是否存在环
结尾:
前言
本文将从最基础的概念讲起,介绍 图的存储方式和怎么遍历图(BFS和DFS基本遍历),并深入 拓扑排序及其应用,帮助你快速入门图论。目标是让你在短时间内掌握图论的核心知识,并具备独立完成 LeetCode 简单及以上难度的图论题目的能力。博客很长,欢迎大家根据目录各取所需.
这是该系列的第一篇,在后面的博客中,笔者还会讲解 最短路径问题(Dijkstra、Bellman-Ford、SPFA) 和 最小生成树(Kruskal、Prim) 等常见算法,帮助你建立图论基础。
笔者自知水平有限, 本博客的质量无法与专业算法书籍相比。但笔者希望通过 通俗易懂的语言,并结合 数据模拟,帮助零基础的读者快速入门图论,并熟悉常见的图论算法模板。对于需要复习的有基础的读者,也可以把该系列博客当成"模板代码托管所",随时备你复习!
目标是让你 不仅能理解算法,还能够在实际中熟练运用,让图论不再只是抽象的概念,而是可以直观感受到的计算过程。
图论是计算机科学中的重要分支,在路径规划、网络流分析、任务调度等多个领域有着广泛应用,学好它对于我们提升代码能力和使用数据结构的能力很有帮助。
好了,前言到此为止,希望您怀揣耐心读下去
博客中出现的参考图都是笔者手画的,代码示例也是笔者手敲的!影响虽小,但请勿抄袭
图的概念
话不多说,首先什么是图?图是由一组顶点(Vertex)和一组边(Edge)组成的结构,通常用于表示事物之间的关系。比如,社交网络中的人和他们之间的关系可以用图来表示;城市之间的道路、交通网络也可以用图来建模。图论研究的就是这些结构以及如何对图进行操作和分析。
1. 顶点和边
-
顶点(Vertex):图中的基本元素,表示对象或节点。比如,在社交网络中,每个用户可以看作一个顶点;在城市的道路网中,每个城市可以看作一个顶点。
-
边(Edge):表示顶点之间的连接关系,通常可以有方向性或者没有方向性。每条边都连接着两个顶点。边可以表示各种关系,比如朋友之间的关系、城市之间的道路等。
2. 图的分类
图的分类可以依据边的方向性、边的权重等多个方面来进行,常见的分类包括:
-
无向图(Undirected Graph):图中的每条边没有方向,表示两个顶点之间的关系是双向的。例如,社交网络中朋友关系就是一种无向图关系。

-
有向图(Directed Graph):图中的每条边都有方向,即每条边从一个顶点指向另一个顶点。例如,网页之间的超链接就是一种有向图关系。

-
加权图(Weighted Graph):图中的边有权重(权值),表示连接两个顶点之间的代价或距离。例如,城市之间的道路距离或者交通时间。

3. 图的基本性质
-
邻接关系:在图中,如果两个顶点通过边相连,就称它们是邻接的。对于无向图,如果顶点 A 和顶点 B 之间有边,则 A 和 B 是邻接的;而对于有向图,如果从顶点 A 到顶点 B 有一条边,则称 B 是 A 的邻接顶点。
-
度(Degree):顶点的度是与该顶点相连的边的数量。对于无向图,顶点的度是其邻接边的数目;对于有向图,分为入度(指向该顶点的边数)和出度(从该顶点出发的边数)。请牢记这个概念,因为拓扑排序需要用到它.
-
连通性:如果图中的每一对顶点都有路径相连,则称图是连通的。无向图中的连通性比有向图更容易理解,因为无向图中不区分边的方向,只要两个顶点之间存在路径就视为连通。图的连通性问题也是一个概念很大的问题,有很多分支,感兴趣的读者们可以自己去了解
图的存储
相信很多初学者在学习图论时,会因为对数据结构理解不够深入而感到困惑,尤其是在理解图的存储方式时可能会遇到不少困难。图的存储方式决定了我们如何在计算机中表示和操作图,因此掌握它至关重要。如果你对数组、链表等基本数据结构还不太熟悉,不用担心,在接下来的内容中,我会用通俗易懂的方式来讲解不同的存储方法,帮助你轻松理解它们的优缺点以及适用场景。
我们主要介绍那么两种,第一种是邻接矩阵,第二种是邻接表,还有一种叫做链式前向星的结构,但是笔者不做介绍.
邻接矩阵存图
首先是邻接矩阵,这是最简单最好理解的存储方法,适用于密度高的图,如果用于稀疏图,那么效果不如邻接表
我们定义二维数组 graph[N][N] 来存图.
如果 图是无向无权值图,那么 graph[i][j] == 1 表示 点 i 到 点 j 有连通
同理 表示 点 j 到 点 i 连通
如果 图是有向无权值图,那么 graph[i][j] == 1 表示 点 i 到 点 j 有连通
graph[j][i] == 1 表示 点 j 到 点 i 有连通
如果两点 a,b之间没有边相连,那么 grapg[a][b] = 0.
如果带权值,二维数组的值就是两点之间的权值,同样分为 无向图与有向图,二维数组的含义与上文同理
例如:


同理,如果矩阵有具体值,那么边就有了权值,这里笔者就不画图了
邻接表存图
不知道各位读者是否对邻接表这个名字很熟悉?是的,之前在介绍哈希表时,笔者就已经介绍过邻接表
[入门JAVA数据结构 JAVADS] 哈希表的初步介绍和代码实现-CSDN博客
邻接表的思想是:每个节点维护一个链表(或数组/列表),记录它连接到的所有节点。对于有权图,我们在记录目标节点的同时,也记录每条边的权值。通俗的说,邻接表就像一个“关系表”,它告诉我们:每个节点直接连接到哪些节点。我们通过这些关系就可以完整地表示出整个图。
以无权有向图为例,假设图如下:
1 → 2
1 → 3
2 → 4
那么在邻接表中,是这么被存储的
1: 2 → 3
2: 4
3:
4:
若这是有权图(比如边的权值分别为 5、7、2),则可以这样表示:
1: (2,5) → (3,7)
2: (4,2)
3:
4:
那么,在JAVA语言中,我们用什么数据结构去组织和描述邻接表呢?
通过图示我们可以看到,这种数据结构要求
能够按“节点编号”快速访问;
每个节点后面还要挂一串“与它相连的边”。
显然,我们可以这么写
List<List<Edge>> graph = new ArrayList<>();
外层
List的下标表示当前节点编号;内层
List<Edge>保存当前节点连接的所有边(每条边都有终点和权值);
Edge是我们自己定义的一个类,表示一条边。这三个结合起来,我们就可以有效的存储图了,第一层的List下标代表起点,第二层
List<Edge>是一个存储Edge的链表,里面有终点坐标和权值,如果是无权图也可以用
List<Integer>.你可以理解成是一个“数组 + 链表”的组合体,既能快速定位每个节点,又能灵活添加边。
我们再定义一个Edge类
class Edge {int to; // 目标节点编号int weight; // 边的权值Edge(int to, int weight) {this.to = to;this.weight = weight;}
}
举个例子,有个图如下所示:

1 → 2 (权值3)
1 → 3 (权值5)
2 → 4 (权值2)
他在邻接表中就长这样
graph[1] -> [(2, 3), (3, 5)]
graph[2] -> [(4, 2)]
graph[3] -> []
graph[4] -> []
我们写一个代码简单构建一下
int n = 4; // 4 个节点,从 1 开始编号
List<List<Edge>> graph = new ArrayList<>();
for (int i = 0; i <= n; i++) {graph.add(new ArrayList<>());
}// 添加边
graph.get(1).add(new Edge(2, 3));
graph.get(1).add(new Edge(3, 5));
graph.get(2).add(new Edge(4, 2));
值得注意的是,上述的例子都是单向图的构建方法, 因为这只是存储了起点和终点,有并不代表终点也可以通往起点,因此,如果是双向图,就要构建两次
例如: 假设 a 点和 b 点是双边互通的,那么就应该这么构建
graph.get(a).add(new Edge(b, w)); // a → b
graph.get(b).add(new Edge(a, w)); // b → a
看到这里的你,哪怕是一名刚刚接触图论的小白,相信也已经不再对“图”这个概念感到陌生了。我们已经了解了图的基本概念、常见分类,以及如何用邻接表在 Java 中高效地存储图结构。
为了节省大家的阅读时间成本,避免重复讲解一些过于基础、但实际中不太常用的内容,接下来的图论部分,我们默认所有图都使用邻接表进行存储。这种方式在实际中应用广泛,简单高效
图的基本遍历
图的遍历是图论中的基本操作之一。无论你是在求连通块、寻找路径,还是在实现更复杂的图算法(比如最短路径、拓扑排序),都绕不开遍历操作。
常见的图遍历方式有两种:
-
DFS(深度优先搜索)
-
BFS(广度优先搜索)
这两种遍历中DFS更强调一条路走到黑,而BFS是层层递进的遍历
以下是我给出的代码
import java.util.*;public class GraphTraversal {static int n, m;static final int N = 505;static List<List<Edge>> graph = new ArrayList<>();static boolean[] vis = new boolean[N];// 定义一个边的类 (u->v, 权值w)static class Edge {int v, w;Edge(int v, int w) {this.v = v;this.w = w;}}// 添加一条 u -> v, 权值为 w 的边static void addEdge(int u, int v, int w) {graph.get(u).add(new Edge(v, w));}// BFS 遍历static void BFS(int start) {Arrays.fill(vis,false);Queue<Integer> queue = new LinkedList<>();queue.offer(start);vis[start] = true;System.out.print("BFS :");System.out.print(start+" ");while(!queue.isEmpty()){int temp = queue.poll();for(Edge edge : graph.get(temp)){if(!vis[edge.v]){vis[edge.v] = true;queue.offer(edge.v);System.out.print(edge.v+" ");}}}}// DFS 遍历static void DFS(int node){if(vis[node]){return;}System.out.print(node+" ");vis[node] = true;for(Edge x : graph.get(node)){if(!vis[x.v]){DFS(x.v);}}}public static void main(String[] args) {Scanner scanner = new Scanner(System.in);n = scanner.nextInt();m = scanner.nextInt();// 提前创建 n+1 个 ArrayList,避免越界for (int i = 0; i <= n+1000; i++) {graph.add(new ArrayList<>());}for (int i = 0; i < m; i++) {int a = scanner.nextInt();int b = scanner.nextInt();int c = scanner.nextInt();addEdge(a, b, c);}scanner.close();// 从 1 号节点开始遍历(你可以改成 0)BFS(1);Arrays.fill(vis, false); // 重新初始化 vis 数组System.out.print("DFS: ");DFS(1);System.out.println();}
}分别是DFS遍历和BFS遍历,通过vis数据去判断结点是否被遍历过,代码很简单
我们给一组示例,如图所示:

我们分别通过DFS和BFS遍历,默认1为起始点
6 8
1 2 4
1 3 2
2 4 3
3 4 1
3 5 2
4 6 5
5 6 1
2 5 7结果如下:
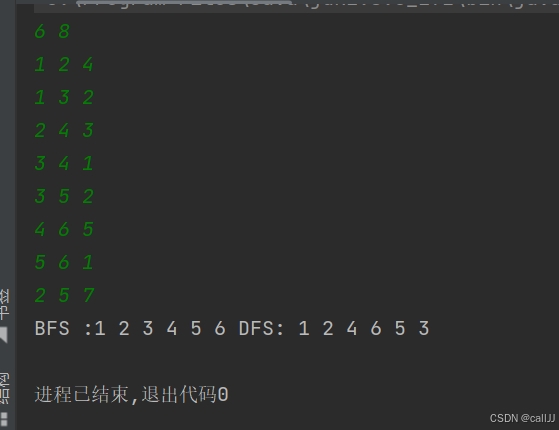
可以看到:
在 BFS(广度优先搜索)中,我们从节点
1开始遍历。由于 BFS 的特点是按层次逐层访问图的节点,因此它的遍历过程是按照节点距离起点的“层数”来进行的。具体来说:
首先输出起始节点
1,这是第一层。然后访问与
1相邻的节点2和3,这就是第二层。接着,访问与
2和3相邻的节点4、5,这是第三层。最后,访问与
4和5相邻的节点6,这是第四层。BFS 的核心在于通过队列来保证节点是按照层次顺序被访问的。它总是先访问当前层的所有节点,然后再访问下一层的节点。因此,BFS 是“逐层”访问的。
而 DFS(深度优先搜索)则不同,它的遍历方式是“沿着一条路径一直走到底,然后再回溯”。因此,它会先访问某个节点的所有相邻节点,直到不能再继续为止,然后再回溯到上一个节点,继续访问其他未访问的邻接节点。
首先输出起始节点
1。然后,DFS 会优先选择一个与
1相邻的节点进行深入。在这个例子中,它会先访问节点2。接下来,DFS 会沿着节点
2的相邻节点继续深入,直到没有新的节点可以访问。此时会回溯到节点2,然后继续访问其他未访问的相邻节点。然后回溯到节点
1,访问与1相邻的节点3,并重复相同的过程,直到所有节点都被访问。
我们来看一道例题:1971. 寻找图中是否存在路径 - 力扣(LeetCode)
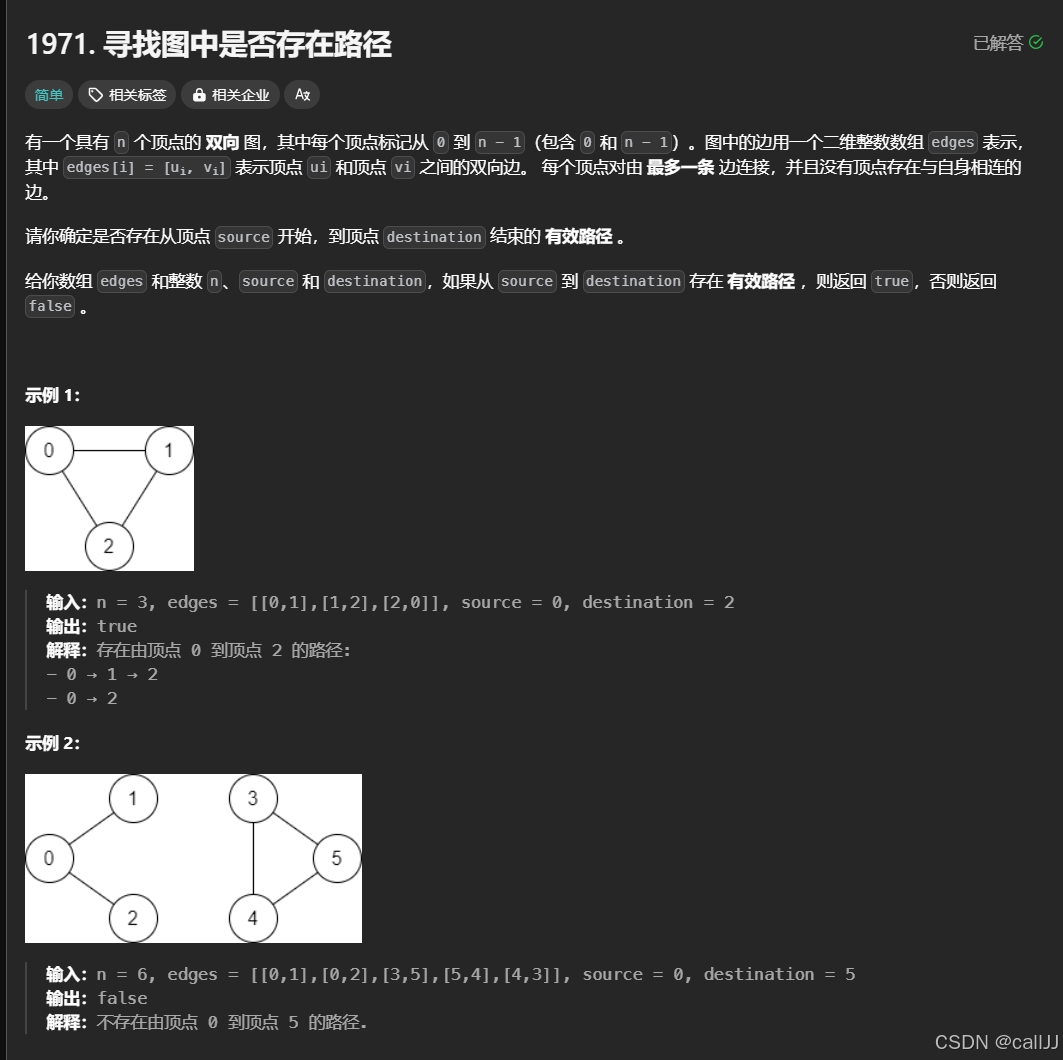
这道题就要求我们去遍历图,来判断是否联通
首先我们构建邻接表,然后去遍历判断
首先对于构建邻接表,因为这道题是双向无权图,所以我们可以构建
List<List<Integer>> graph = new ArrayList<>() 来存储图
BFS写法:
class Solution {public boolean validPath(int n, int[][] edges, int source, int destination) {List<List<Integer>> graph = new ArrayList<>();for (int i = 0; i < n; i++){graph.add(new ArrayList<>());}for (int[] edge : edges) {int u = edge[0], v = edge[1];graph.get(u).add(v);graph.get(v).add(u);}boolean[] vis = new boolean[n];Queue<Integer> queue = new LinkedList<>();queue.offer(source);vis[source] = true;while(!queue.isEmpty()){int temp = queue.poll();if(temp == destination){return true;}for(Integer num : graph.get(temp)){if(!vis[num]){vis[num] = true;queue.offer(num);}}}return false;}
}
首先构建双向邻接表,然后遍历
DFS写法: 和上述同理
class Solution {static boolean[] vis;public boolean DFS(List<List<Integer>> graph,int st,int ed){if(st == ed){return true;}vis[st] = true;for(Integer num:graph.get(st)){if(!vis[num]){boolean pd = DFS(graph,num,ed);if(pd == true){return true;}}}return false;}public boolean validPath(int n, int[][] edges, int source, int destination) {List<List<Integer>> graph = new ArrayList<>();for (int i = 0; i < n; i++){graph.add(new ArrayList<>());}for (int[] edge : edges) {int u = edge[0], v = edge[1];graph.get(u).add(v);graph.get(v).add(u);}vis = new boolean[n];boolean pdf = DFS(graph,source,destination);return pdf==true?true:false;}
}
当然,这不是该题的最优解法,但是我们可以通过这题了解BFS与DFS是如何遍历图的.
拓扑排序
拓扑排序可以被看作是BFS,DFS的简单应用,从代码模板上看也是这样的.
"拓扑排序"是图论中一个非常经典的问题,常用于解决“有依赖关系的任务排序问题”。比如学习技术栈,如果我要成为一个合格的JAVA开发工程师,我需要学习很多技术栈
在学习 SpringBoot 之前,必须先掌握 JavaSE 和 JavaEE 的基础;
在学习 MyBatis 前,需要具备一定的数据库基础,比如 SQL;
想要理解分布式系统,还得先了解网络通信、RPC 原理、消息队列等内容;
构建前后端分离项目,也依赖于对前端基础、后端 API 编写等知识的掌握。
但是拓扑排序的前提是图必须是有向且无环的图,如果图中存在环,那么就无法构建出合法的拓扑序列 —— 比如课程 A 依赖课程 B,B 又依赖 A,这样就永远无法开始任何课程。
举个例子:

它拓扑排序的结果应该是:
1 3 2 4 5 6
拓扑排序是如何写的呢?
大概有这么几个步骤
1. 统计每个节点的入度
每个节点的入度是指:有多少条边指向它。我们需要用一个数组来记录每个点的入度。这个在前面也提到了
static int [] ingrade;//存储入度public static void addEdge(int u,int v){graph.get(u).add(v);// 表示 u 到 v 有一条边ingrade[v]++;}2. 构建邻接表
我们用邻接表来表示图中每个节点的出边(即它连接到哪些后续节点):
for(int i = 0;i<=n;i++){graph.add(new ArrayList<>());}for(int i = 0;i<m;i++){int a = scanner.nextInt();int b = scanner.nextInt();addEdge(a,b);}3. 将所有入度为 0 的节点加入队列
这些节点说明它们没有前置依赖,可以作为起点。我们使用一个队列来进行 BFS
4. 不断弹出队头节点,更新其相邻节点的入度
遍历过程中,每访问一个节点,就“移除”它的影响,也就是把它连接的边都删掉,同时更新这些目标节点的入度。
5. 判断是否存在环
如果最终输出的拓扑序列长度少于
n,说明存在环(即有任务间形成了“循环依赖”)public static void BFS(){PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();for(int i =1;i<=n;i++){if(ingrade[i]==0)//入度为0{priorityQueue.offer(i);}}while(!priorityQueue.isEmpty()){int node = priorityQueue.poll();result.add(node);for(Integer neighbor : graph.get(node)){ingrade[neighbor]--;//相邻结点入度--if(ingrade[neighbor]==0){priorityQueue.add(neighbor);}}}}
完整代码如下:
import java.util.ArrayList;
import java.util.List;
import java.util.PriorityQueue;
import java.util.Scanner;
//拓扑排序是一种 用于有向无环图(DAG,Directed Acyclic Graph) 的排序方法,它将图中的所有节点排成一个线性序列,使得对于 每一条有向边
//𝑢→𝑣,节点 u 在序列中出现在 v 之前。
public class TopoSortBFS
{static int n,m;static List<List<Integer>> graph = new ArrayList<>(); // 用邻接表存储图static List<Integer> result = new ArrayList<>();public static void addEdge(int u,int v){graph.get(u).add(v);// 表示 u 到 v 有一条边ingrade[v]++;}public static void BFS(){PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();for(int i =1;i<=n;i++){if(ingrade[i]==0)//入度为0{priorityQueue.offer(i);}}while(!priorityQueue.isEmpty()){int node = priorityQueue.poll();result.add(node);for(Integer neighbor : graph.get(node)){ingrade[neighbor]--;//相邻结点入度--if(ingrade[neighbor]==0){priorityQueue.add(neighbor);}}}}static int [] ingrade;//存储入度public static void main(String[] args) {Scanner scanner = new Scanner(System.in);n = scanner.nextInt(); // 读取节点数m = scanner.nextInt(); // 读取边数ingrade = new int[n+1];for(int i = 0;i<=n;i++){graph.add(new ArrayList<>());}for(int i = 0;i<m;i++){int a = scanner.nextInt();int b = scanner.nextInt();addEdge(a,b);}BFS();if(result.size()==n){for(Integer i : result){System.out.print(i+" ");}}else{System.out.println(-1);}}
}
我们可以看一道例题:0恋爱通关游戏 - 蓝桥云课

在这个例题中,我们需要在一个无环图(DAG)中,从起点出发,依次经历多个关卡,根据不同选择提升好感度,直到到达终点关卡,并判断最终好感度是否达到目标值(≥100)。
从图论的角度来看:
每个关卡可以看成是一个图中的节点;
每个选项可以看成是有向边,带有一个权值(即好感度提升值);
整个游戏流程构成了一张有向无环图(DAG),因为题目明确说明“不会再遇到已结束关卡”,即不存在回环;
最终目标是从起点到某个终点路径中,累积最大好感度,看是否能达到通关标准。
因此,这道题本质上就是在一张 DAG 上找最大路径和 的问题。
为什么是拓扑排序?
这是一个非常典型的拓扑排序应用场景:
只有当一个节点的所有前驱节点都已经被处理完,才能开始计算它的最优值。
换句话说,我们必须尝试过所有能到达该节点的路径,才能确定哪一条路径带来的值最大(或最小)。
所以,我们需要先对整个图进行 拓扑排序,然后按照拓扑序去“刷新”每个点的最大好感度。
题解代码:
import java.util.ArrayList;
import java.util.List;
import java.util.PriorityQueue;
import java.util.Scanner;
import java.util.*;
public class Demo46 {// Edge 用于存边,a->b好感度为c;b就是达到的关卡,c为好感度static class Node{int b, c;public Node(int b, int c){this.b = b; this.c = c;}}static final int N = (int)2e5+10;static int[] dis = new int[N]; // 用于存储到达当前关卡的好感度 cArr[i] 表示到 i 点的好感度static List<List<Node>> list = new ArrayList<>();static Queue<Integer> queue = new LinkedList<>(); // 入度为0的关卡加入到order列表中,以用于拓扑排序static int[] inDegree = new int[N]; // 记录每个关卡的当前入度static int res = 0;public static void addEdge(int a,int b,int c){list.get(a).add(new Node(b,c));inDegree[b]++;}public static void BFS() {Arrays.fill(dis, (int) -2e8);// 入度为 0 的点,初始化for (int i = 0; i < n; i++) {if (inDegree[i] == 0) {queue.offer(i);dis[i] = 0; // 所有入度为 0 的点,都要初始化为 0}}while (!queue.isEmpty()) {int st = queue.poll();// 终点判断:出度为 0 的节点if (list.get(st).isEmpty() && dis[st] >= 100) {res++;}for (Node temp : list.get(st)) {int ed = temp.b;inDegree[ed]--;if (inDegree[ed] == 0) {queue.offer(ed);}dis[ed] = Math.max(dis[ed], dis[st] + temp.c);}}}static int n,m;public static void main(String[] args) {Scanner scanner = new Scanner(System.in);n = scanner.nextInt();m = scanner.nextInt();for(int j = 0;j<=n;j++){list.add(new ArrayList<>());}while(m!=0){m--;int a = scanner.nextInt();int b = scanner.nextInt();int c = scanner.nextInt();addEdge(a,b,c);}BFS();System.out.println(res);}
}结尾:
又是一篇万字长文,好久没有花这么长时间(大概写了120-140min)去写一篇博客了,感谢能读到这里的读者!
欢迎大佬私信来拷打我!



![MySQL基础 [一] - Ubuntu版本安装](http://pic.xiahunao.cn/MySQL基础 [一] - Ubuntu版本安装)















