前置知识
robots.txt是机器人协议,在使用爬虫爬取网站内容时应该遵循的协议。协议并不能阻止爬虫爬取,更像是一种道德规范。
假设robots.txt中写道 Disallow: /admind.php,那我就暴露了自己的后台,这属于信息泄漏,攻击者可进入相应页面检查是否存在可利用的漏洞。
信息收集
根据题目提示:总有人把后台地址写入robots,帮黑阔大佬们引路。
我们直接访问url/robots.txt,url指的是也就是类如http(s)://www.xxx.com这样的地址,所以我获得的题目地址是:
https://a508babb-b6fb-4919-a531-09ea25a44266.challenge.ctf.show
我将访问
https://a508babb-b6fb-4919-a531-09ea25a44266.challenge.ctf.show/robots.txt

这里我们获得了另一个网站入口url/flagishere.txt,很有可能flag就在这里,我们尝试访问一下,反正又不会有什么损失。
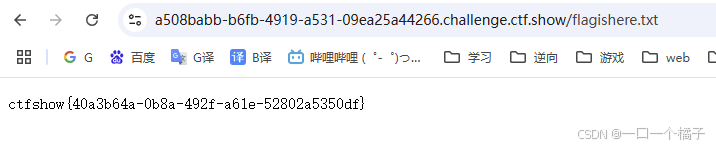
果然,拿到了flag
web3 目录 web5

超详细!!!!)





:广告验证与反作弊实战技巧)

 下载与安装教程)


![Muduo网络库实现 [十五] - HttpContext模块](http://pic.xiahunao.cn/Muduo网络库实现 [十五] - HttpContext模块)




)

