目录
设计思路
类的设计
解码过程
模块的实现
私有接口
请求函数
解析函数
公有接口
疑惑点
设计思路
记录每一次请求处理的进度,便于下一次处理。
上下文模块是Http协议模块中最重要的一个模块,他需要记录每一次请求处理的进度,需要保存一个HttpRequest对象,后续关于这个连接的http的处理的信息全部都是在这个上下文中保存。
那既然是记录,肯定就要让它知道当前是在哪个进度了,所以我们就用状态码去表示
//处理状态
enum HttpRecvStatu{RECV_ERR, //接收错误RECV_LINE, //接收请求行RECV_HEAD, //接收头部RECV_BODY, //接收正文RECV_OVER //接收完毕
};注意:这些枚举值通常表示当前正在处理的状态,而不是已经完成的状态。
同时,由于收到的http请求报文可能是会出错的,而出错的话,我们是不会将这个报文进行业务的处理的,而是直接返回一个请求错误的状态码的报文,那么我们的上下文当中不可避免的还需要保存一个变量用来保存状态码。
还需要有一个 HttpRequest 对象来存储从客户端请求中解析出的各种信息。
具体来说,HttpRequest 对象通常会存储以下请求要素:
- 请求方法 (Method):如 GET、POST、PUT、DELETE 等
- 请求的 URL 路径
- HTTP 版本 (如 HTTP/1.1)
- 请求头 (Headers):如 Content-Type、User-Agent、Cookie 等
- 请求参数 (如 URL 中的查询参数)
- 请求体 (Body):POST 请求中包含的数据
- 其他请求相关的元数据
类的设计
既然它需要那么多状态,那说明它肯定是要处理这些状态的,也就是需要处理请求行,处理头部,处理正文,处理错误。那这些报文从哪里来呢?肯定是需要从缓冲区接收过来的,当然接收过来之后,我们还需要把缓冲区的数据的请求行段,请求头部段,请求正文段,分离出来,以便后续我们使用。接下来我们先看一个解码的过程,来加深理解一下流程
解码过程
假设我们收到了以下 HTTP 请求:
GET /my%20documents/report.pdf?search=machine+learning&year=2023 HTTP/1.1第一步:解析请求行
正则表达式匹配结果:
- matches[1] = "GET"(请求方法)
- matches[2] = "/my%20documents/report.pdf"(路径部分)
- matches[3] = "search=machine+learning&year=2023"(查询字符串部分)
- matches[4] = "HTTP/1.1"(HTTP版本)
第二步:解码路径部分
我们对 matches[2] 使用 UrlDecode(matches[2], false) 进行解码:
- 参数 false 表示不将加号(+)转换为空格
- 将 %20 解码为空格字符
- 输入:"/my%20documents/report.pdf"
- 输出:"/my documents/report.pdf"
第三步:处理查询字符串
- 首先拆分查询字符串(matches[3]):
- 输入:"search=machine+learning&year=2023"
- 使用
&作为分隔符拆分 - 结果:["search=machine+learning", "year=2023"]
- 对每个参数进行处理: 对于第一个参数 "search=machine+learning":
- 找到等号(=)位置:pos = 6
- 提取键:str.substr(0, pos) = "search"
- 提取值:str.substr(pos + 1) = "machine+learning"
- 对键进行解码:UrlDecode("search", true) = "search"(无需解码)
- 对值进行解码:UrlDecode("machine+learning", true) = "machine learning" (注意这里使用 true 参数,将加号转换为空格)
- 将键值对保存到请求对象:_request.setParam("search", "machine learning")
- 找到等号(=)位置:pos = 4
- 提取键:str.substr(0, pos) = "year"
- 提取值:str.substr(pos + 1) = "2023"
- 对键进行解码:UrlDecode("year", true) = "year"(无需解码)
- 对值进行解码:UrlDecode("2023", true) = "2023"(无需解码)
- 将键值对保存到请求对象:_request.setParam("year", "2023")
结果
请求对象中现在包含以下数据:
- 路径: "/my documents/report.pdf"
- 查询参数:
- "search" -> "machine learning"
- "year" -> "2023"
所以我们的类声明如下
#define MAX_LINE 8192 // HTTP请求行最大长度// HTTP请求解析上下文类
class HttpContext
{
private:HttpParseStatu _parse_status; // 当前解析状态int _status_code; // 状态码HttpRequest _request; // 存储解析出的HTTP请求信息private:bool RecvLine(Buffer *buf); // 接收请求行bool RecvHead(Buffer* buf); // 接收请求头部bool RecvBody(); // 接收请求正文bool ParseLine(const string &line); // 解析请求行bool ParsesHead(string &line); // 解析请求头部public:HttpContext(); // 构造函数void ReSet(); // 重置解析状态int StatusCode(); // 获取HTTP状态码HttpParseStatu ParseStatus(); // 获取当前解析状态HttpRequest& Request(); // 获取解析完成的HTTP请求void RecvHttpRequest(Buffer *buf); // 接收处理HTTP请求数据
};模块的实现
对于私有模块,也就是接收缓冲区的数据,然后把请求行,请求头部,请求正文获取到并且解析出来,然后放入到HttpRequest中存储,以供应用层进行调用
私有接口
请求函数
对于请求函数,基本上就是大差不差,先判断状态是否匹配,然后获取缓冲区数据的一行数据,进行判断是否是完整的数据,然后判断异常,异常有两种,第一种是没有拿到请求数据(请求行,请求头部,请求正文),但是缓冲区的数据已经超过最大值了,但还不是完整的数据,这说明数据是错的,那么我们就不处理,直接修改状态成错误,设置错误状态码就行了。第二种就是拿到了请求数据,但是数据也是巨大,这个时候我们也是不处理,修改状态为错误。设置错误状态码。如果合法了就开始解析请求数据,然后更新数据。这里解析请求数据是不一样的,等会重点讲解析的函数
bool RecvLine(Buffer *buf) // 接收请求行{if (_parse_status != RECV_HTTP_LINE){return false;}string line = buf->GetLineAndPop(); // 根据 HTTP 协议规范,HTTP 请求的结构是固定的,第一行必须是请求行if (line.size() == 0) // 说明出问题了,去缓冲区找问题{if (buf->ReadAbleSize() > MAX_LINE) // 说明此时缓冲区有数据,但是数据太大了还没有结束{_parse_status = RECV_HTTP_ERR;_status_code = 414; // URI TOO LONGreturn false;}// 否则就说明缓冲区的请求行太少,还没发完,再等等return true;}if (line.size() > MAX_LINE) // 说明虽然拿到了请求行,但是肯定是错误的,请求行的数据哪能那么多{_parse_status = RECV_HTTP_ERR;_status_code = 414; // URI TOO LONGreturn false;}//走到这就说明请求行合法了,开始处理bool ret = ParseLine(line);if(ret == false){return false;}//请求行状态结束,更新下一个状态_parse_status = RECV_HTTP_HEAD;return true;}bool RecvHead(Buffer* buf) // 接收请求报头{if (_parse_status != RECV_HTTP_HEAD) //进行判断是否是请求报头的状态了{return false;}//走到这就说明第一行的请求行已经被取走了,现在缓冲区的第一行就是请求报头了while(1)//因为报头的格式每行都是xxxx\n\r,一直到空格行才算结束{string line = buf->GetLineAndPop();if (line.size() == 0) // 说明出问题了,去缓冲区找问题{if (buf->ReadAbleSize() > MAX_LINE) // 说明此时缓冲区有数据,但是数据太大了还没有结束{_parse_status = RECV_HTTP_ERR;_status_code = 414; // URI TOO LONGreturn false;}// 否则就说明缓冲区的请求行太少,还没发完,再等等return true;}if (line.size() > MAX_LINE) // 说明虽然拿到了请求行,但是肯定是错误的,请求行的数据哪能那么多{_parse_status = RECV_HTTP_ERR;_status_code = 414; // URI TOO LONGreturn false;}//走到这就说明拿到了正常的数据if(line == "\n" || line == "\r\n") //如果这一行是报头的结束标志就要退出循环{break;}int ret = ParsesHead(line); //因为每一行都不一样,所以每取一行就要进行保存if(ret == false){return false;}}_parse_status = RECV_HTTP_BODY;return true;}bool RecvBody() // 接收请求正文{if(_parse_status != RECV_HTTP_BODY){return false;}size_t content_size = _request.GetLength(); //这也是固定格式,就是正文中会有一行是表示正文长度的if(content_size == 0) //因为正文可能有也可能没有{_parse_status = RECV_HTTP_OVER;return true;}//因为正文可能会很长int real_size = content_size - _request._body.size();//如果缓冲区数据充足if(buf->ReadAbleSize() >= real_size){_request._body.append(buf->ReadPos(), real_size);buf->MoveReadIndex(real_size);_parse_status = RECV_HTTP_OVER;return true;}//如果缓冲区数据不够,先全拿出,但是不能设置状态_request._body.append(buf->ReadPos(), buf->ReadAbleSize());buf->MoveReadIndex(buf->ReadAbleSize());return true;}对于请求报头来说,因为每行都是xxx: yyyyy\r\n;的格式,但是内容是不同的,所以我们要处理一行就解析一行,不然等你读取完你再处理,你xxx对应的值是yyyy,不还是要把每行再分离出来吗?所以就需要一个循环,取一行就解析一行。一直到读取到空格行,也就是结束的标志。然后把状态更新一下
对于请求正文来说,也有一些不同,因为一般情况下,正文的数据会非常的多,一次性会处理不完,处理不完怎么办呢,那么我们就读取一点拿过来一点,然后记录下这个读取长度。在请求头部中,会有个记录请求正文长度的,我们获取到这个长度之后,然后减去这个已经存储的长度,就是剩余我们还需要的长度,然后下次再进行判断,如果缓冲区的数据大于了还需要的长度,就说明已经有充足的数据了,然后就直接把剩余的数据追加到之前的数据后面就可以了,接着更新状态
解析函数
首先,我们最先从缓冲区获取的数据也就是请求行数据,那肯定最先用的就是解析请求行函数了
解析请求行的时候我们使用的正则表达式是这个:
(GET|HEAD|POST|PUT|DELETE) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?在这个正则表达式的匹配结果中,如果我们的url中没有携带参数,那么参数部分的匹配结果就是一个空串,他也是在matches里面的,这一点我们不需要关心,因为后续我们解析参数的时候会将这种情况给他处理了。
然后我们用 bool ret = regex_match(line, matches, e); 去把获取到的数据放在maches中,然后通过matches[1],[2],[...]放到我们定义的HttpRequest对象中存储起来。
query 变量存储的是从HTTP请求URL中提取的查询字符串(query string)部分。
具体来说,当HTTP请求有如下形式时:
GET /path/to/resource?name=value&another=data HTTP/1.1
query 变量会存储 name=value&another=data 这部分内容。
在正则表达式匹配中,matches[3] 对应的是第三个捕获组 (?:\\?(.*))? 中的 (.*) 部分,也就是问号 ? 后面的所有内容,直到空格之前。
之后的代码会进一步处理这个查询字符串:
- 使用
&分隔符将查询字符串分割成多个键值对 - 对每个键值对,查找
=的位置来分离键和值 - 对键和值进行URL解码(处理百分号编码和特殊字符)
- 将解码后的键值对存储到请求对象中
最后就是
- 从已经找到的每个查询字符串部分(如"name=value")中,使用等号("=")的位置将字符串分割成两部分
string key = Util::UrlDecode(str.substr(0, pos),true);- 提取等号前面的部分作为键(key)
- 使用
str.substr(0, pos)获取从字符串开始到等号位置的子字符串 - 然后用
Util::UrlDecode进行URL解码,true参数表示将加号(+)转换为空格
string val = Util::UrlDecode(str.substr(pos+1),true);- 提取等号后面的部分作为值(value)
- 使用
str.substr(pos+1)获取从等号后一个位置到结尾的子字符串 - 同样进行URL解码,
true参数表示将加号转换为空格
_requset.SetParam(key,val);- 将解码后的键值对添加到HTTP请求对象中
- 这样应用程序就可以通过HTTP请求对象访问这些查询参数
bool ParseLine(const string &line) // 解析请求行{smatch matches;std::regex e("(GET|HEAD|POST|PUT|DELETE) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?");bool ret = regex_match(line, matches, e);if(ret == false){_parse_status = RECV_HTTP_ERR;_status_code = 400; // BAD REQUESTreturn false;}//存储请求的方法,资源路径,协议版本_request._method = matches[1];_request._path = Util::UrlDecode(matches[2],false); //资源路径需要解码,但是只有查询字符串才要空格转加号_request._version = matches[4];string query = matches[3];//分三步:1.分割&前后的内容放入vector中 2.循环查找=的位置,分割=前后的内容,前面是key,后面是val 3.存储kvvector<string> query_array;Util::Spilt<query, "&", &query_array>;for(auto &str : query_array){size_t pos = str.find("=");if(pos == string::npos) //这个是固定格式,如果没有找到=就说明是错误的{_parse_status = RECV_HTTP_ERR;_status_code = 400; // BAD REQUESTreturn false;}string key = Util::UrlDecode(str.substr(0, pos),true);string val = Util::UrlDecode(str.substr(pos+1),true);_requset.SetParam(key,val);}return true;}接下来就是解析报头了,先把每行中的最后\n\r给删掉,然后去找每行的固定格式: 找到之后更新状态就行了
bool ParsesHead(string &line) // 解析请求报头{//先删除末尾无用字符if(line.back() == "\n"){line.pop_back();}if(line.back() == "\n"){line.pop_back();}size_t pos = line.find(": "); //这个也是固定格式if(pos == string::npos){_parse_status = RECV_HTTP_ERR;_status_code = 400; // BAD REQUESTreturn false;}}为什么会没有解析正文这个函数呢?
- 灵活性考虑 - HTTP请求正文有多种格式(JSON、XML、表单数据、二进制数据等),不同应用需要不同的解析方式。如果在库中内置特定的解析方法,可能会限制库的通用性。
- 分离关注点 - 这符合"关注点分离"的软件设计原则,网络库负责网络通信和基本协议解析,应用层代码负责特定业务逻辑和数据格式解析。
- 避免依赖膨胀 - 如果实现各种正文格式的解析,可能需要引入额外的依赖库(如JSON解析库),这会使muduo库变得臃肿。
- 性能考虑 - 通用的解析方法可能无法满足特定应用的性能需求,让用户自行实现可以针对特定场景进行优化。
在实际使用中,muduo的这种设计让开发者可以根据自己的需求选择适合的请求正文解析方式,比如对于JSON格式可以使用rapidjson,对于表单数据可以自行实现解析逻辑等。这提供了更大的灵活性,也符合C++库的设计理念。
公有接口
HttpContext() - 构造函数,初始化解析状态为接收请求行(RECV_HTTP_LINE),状态码为200(成功)。
void ReSet() - 重置函数,将状态恢复到初始状态: 重置状态码为200
重置解析状态为接收请求行
清空请求对象
int StatusCode() - 返回当前HTTP状态码。
HttpParseStatu ParseStatus() - 返回当前的解析状态(如接收请求行、接收头部等)。
HttpRequest& Request() - 返回已解析的HTTP请求对象的引用,供上层访问。
void RecvHttpRequest(Buffer *buf) - 核心解析函数,根据当前解析状态调用相应的处理函数: 如果是接收请求行状态,调用RecvLine
如果是接收头部状态,调用RecvHead
如果是接收正文状态,调用RecvBody
HttpContext():_parse_status(RECV_HTTP_LINE),_status_code(200){}void ReSet(){_status_code(200);_parse_status(RECV_HTTP_LINE);_request.Reset();}//返回状态码int StatusCode(){return _status_code;}//返回解析状态HttpParseStatu ParseStatus(){return _parse_status;}//返回已经解析并处理的请求信息HttpRequest& Request(){return _request;}void RecvHttpRequest(Buffer *buf){switch (_parse_status){case RECV_HTTP_LINE:RecvLine(buf);case RECV_HTTP_HEAD:RecvHead(buf);case RECV_HTTP_BODY:RecvBody(buf);default:break;}}疑惑点
读取请求的接口,为什么不要break?
- 提高解析效率 - 允许在一次函数调用中尽可能多地解析数据。例如,如果缓冲区中同时包含了请求行和请求头部的数据,这种设计可以一次性处理完所有可用数据,而不必等待下一次调用。
- 状态机连续处理 - HTTP解析是一个状态机过程,当一个状态处理完成后,如果有更多数据可以处理,应该立即进入下一个状态进行处理。
- 最大化缓冲区利用 - 充分利用每次
RecvHttpRequest调用处理尽可能多的数据,减少处理延迟。
解析和接收两个意思一样吗?
接收(Receiving):
- 指的是从网络中获取原始数据(字节流)的过程
- 属于网络 I/O 操作,涉及到套接字读取
- 关注的是"如何获取数据"
- 例如:从 TCP 连接读取字节流到缓冲区
解析(Parsing):
- 指的是将已接收的原始数据转换为结构化信息的过程
- 属于数据处理操作,涉及到语法分析
- 关注的是"如何理解数据"
- 例如:将 HTTP 原始报文分解为请求行、头部字段、请求体等
在 HTTP 服务器的工作流程中:
- 首先接收原始的 HTTP 请求报文(字节流)
- 然后解析这些字节流,提取出各种 HTTP 请求组件
- 最后基于解析结果进行业务处理
为什么需要设置单个接收函数,比如接收请求行,接收请求报头,难道不能设置一个函数用于接收整个报文吗?

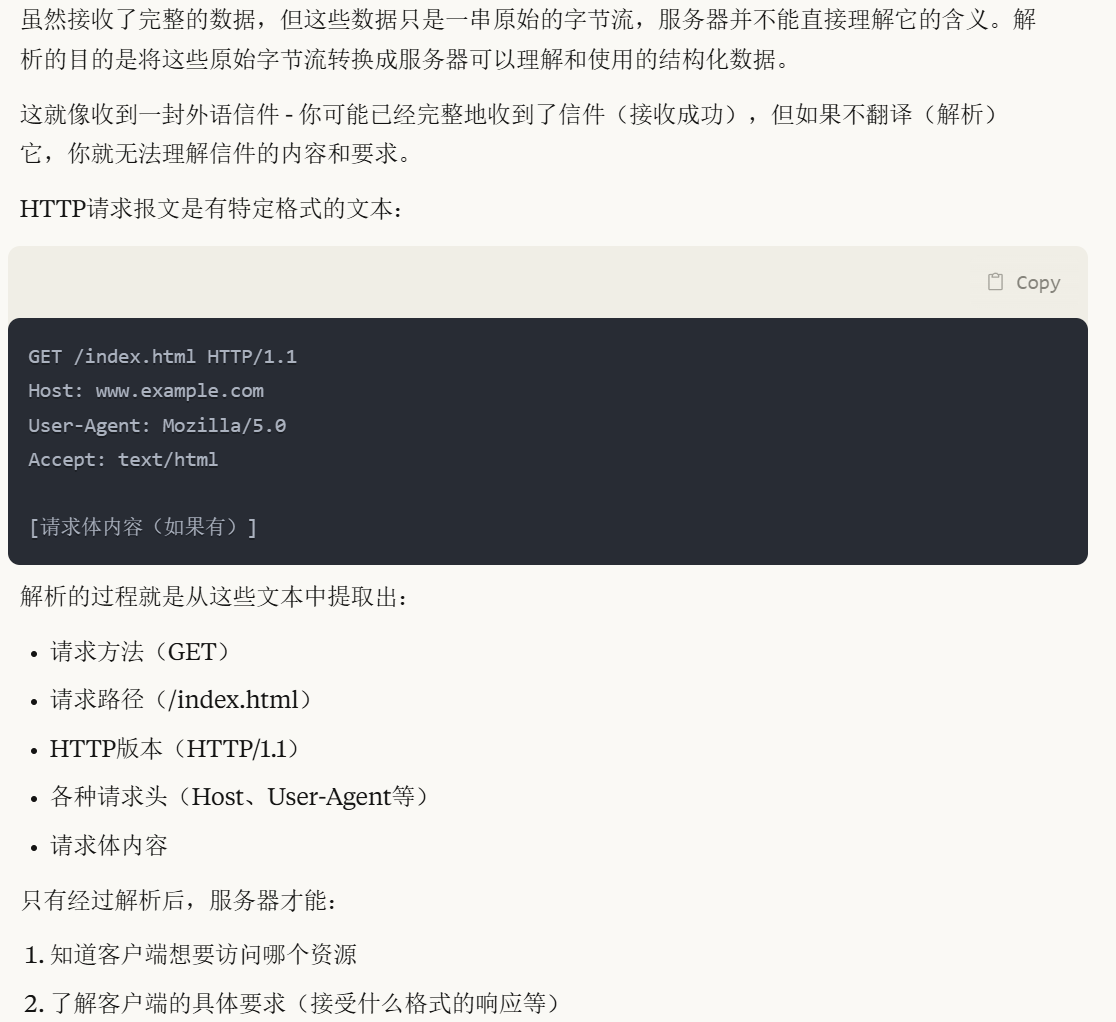
为什么要解析呢 它既然接收成功了不就说明是一个完整的吗?
解析就好比翻译,你收到了一封外国友人的信,他是用他们国家的语言写的,你虽然有一个完整的信,但是你读不懂内容,所以就需要翻译信的内容了
std::regex e("(GET|HEAD|POST|PUT|DELETE) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?"); 这个是什么?

_request._path = Util::UrlDecode(matches[2],false); //资源路径需要解码,但是只有查询字符串才要空格转加号





)


)



)
![P7453 [THUSC 2017] 大魔法师 Solution](http://pic.xiahunao.cn/P7453 [THUSC 2017] 大魔法师 Solution)

—— DDL)



鼠标节流处理、throttle、限制触发频率(setTimeout、clearInterval))
