1. env-准备环境
2. source-加载数据
3. transformation-数据处理转换
4. sink-数据输出
5. execute-执行
流程图:


DataStream API开发
//nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/datastream/overview/
添加依赖
<properties><flink.version>1.13.6</flink.version>
</properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-shaded-hadoop-2-uber</artifactId><version>2.7.5-10.0</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency></dependencies><build><extensions><extension><groupId>org.apache.maven.wagon</groupId><artifactId>wagon-ssh</artifactId><version>2.8</version></extension></extensions><plugins><plugin><groupId>org.codehaus.mojo</groupId><artifactId>wagon-maven-plugin</artifactId><version>1.0</version><configuration><!--上传的本地jar的位置--><fromFile>target/${project.build.finalName}.jar</fromFile><!--远程拷贝的地址--><url>scp://root:root@bigdata01:/opt/app</url></configuration></plugin></plugins></build>
编写代码
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount01 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类DataStream<String> dataStream01 = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");DataStream<String> flatMapStream = dataStream01.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}});//flatMapStream.print();// Tuple2 指的是2元组DataStream<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1); // ("hello",1)}});DataStream<Tuple2<String, Integer>> sumResult = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}// 此处的1 指的是元组的第二个元素,进行相加的意思}).sum(1);sumResult.print();// 执行env.execute();}
}批处理结果:前面的序号代表分区
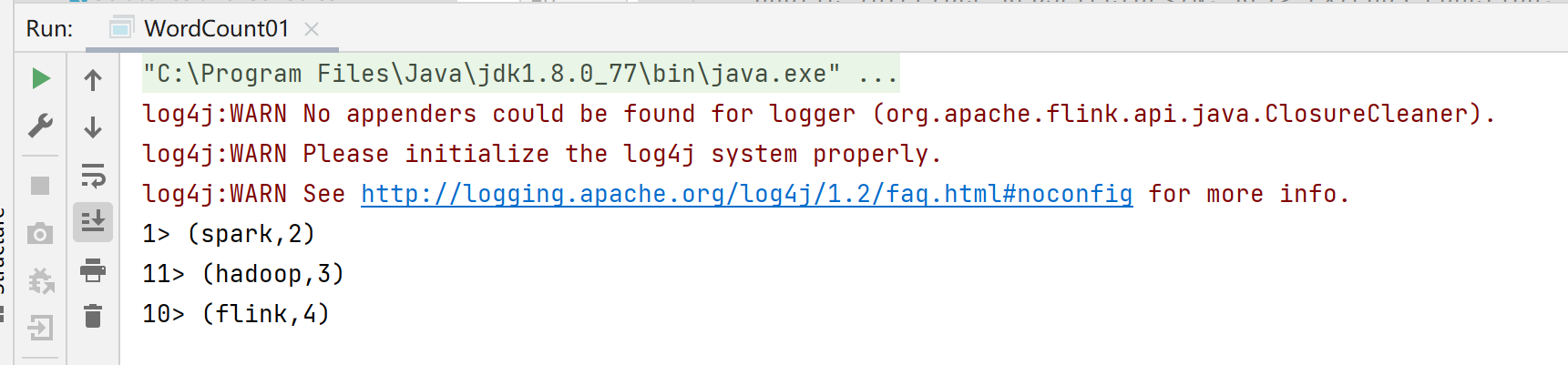
流处理结果:
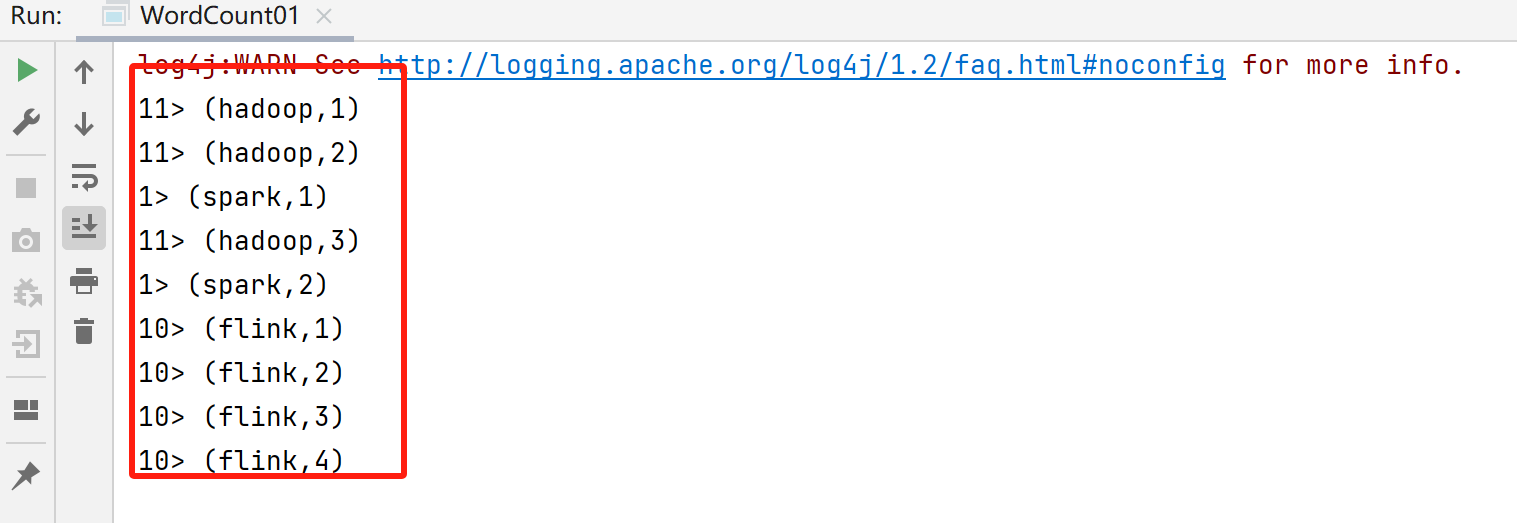
也可以通过如下方式修改分区数量:
env.setParallelism(2);关于并行度的代码演示:
系统以及算子都可以设置并行度,或者获取并行度
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount01 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 将任务的并行度设置为2// env.setParallelism(2);// 通过这个获取系统的并行度int parallelism = env.getParallelism();System.out.println(parallelism);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类DataStream<String> dataStream01 = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");DataStream<String> flatMapStream = dataStream01.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}});// 每一个算子也有自己的并行度,一般跟系统保持一致System.out.println("flatMap的并行度:"+flatMapStream.getParallelism());//flatMapStream.print();// Tuple2 指的是2元组DataStream<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1); // ("hello",1)}});DataStream<Tuple2<String, Integer>> sumResult = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}// 此处的1 指的是元组的第二个元组,进行相加的意思}).sum(1);sumResult.print();// 执行env.execute();}
}- 打包、上传



文件夹需要提前准备好

提交我们自己开发打包的任务
flink run -c com.bigdata.day01.WordCount01 /opt/app/FlinkDemo-1.0-SNAPSHOT.jar 
去界面中查看运行结果:
因为你这个是集群运行的,所以标准输出流中查看,假如第一台没有,去第二台查看,一直点。



)







--队列,数组、链式、优先队列的实现)

RTOS)






(@PatchMapping、@RequestParam、@URL、ThreadLocal线程局部变量))