先说我的观点,我觉得可以,但是应该不是现在。
然后得补个概念,啥是Triton
OpenAI的Triton 是一种专为高效编写深度学习运算而设计的编程语言和编译器。它旨在简化用户编写针对现代GPU(尤其是NVIDIA GPU)的自定义运算代码的过程,从而提升性能和效率。CUDA Toolkit 则是NVIDIA提供的一个全面的GPU计算平台和编程模型,包含了编译器、库、工具和文档,支持开发高性能的GPU应用程序。
Triton与CUDA Toolkit的关系
-
依赖关系:
-
CUDA Toolkit 是Triton运行的基础。Triton依赖于CUDA Toolkit中的编译器(如nvcc)、库(如cuBLAS、cuDNN)以及其他开发工具来生成和执行高效的GPU代码。(需要强调现阶段,其实cuBLAS就可以不太用了,比如我自己写矩阵乘,一会的demo就是)
-
Triton 使用CUDA编译器将其代码转换为高效的GPU内核,因此需要CUDA Toolkit的支持才能正常工作。(需要强调现阶段)
-
-
功能定位:
-
CUDA Toolkit 提供了底层的GPU编程接口和优化工具,适用于各种GPU计算任务。
-
Triton 则专注于简化和优化深度学习相关的GPU运算,提供更高层次的抽象,使得编写高性能GPU代码更为便捷。
-
那我都有CUDA了,这不又造轮子吗?
不是的。
第一:虽然说现阶段的Triton比较高维,脱胎在CUDA之上(其实现在已经很少设计cuda toolkit了,主要是driver和一些特定函数,以后就只会是driver),最终是要跨平台的。
第二:我好多算子可以在triton上写,高维,编辑便捷,同时对下的调用要远好于cuda,好多都可以全自动,比如显存和读取矩阵的方式等等
9月17号Triton大会上,那可是能来站台都来站台了,就不说什么各种chip公司,高通,intel,AMD,连NV自己都来了


这人就是OpenAI 的 Philippe Tillet,Triton 的最hardcore 的contributor

PT也直接拿出大家对Triton的吐槽来说事,其实这也是现在着急要做的,因为现在还没那么通用,离它最重要的工作还差得远。
稍微解释一下主要分支和不同后端的编译流程:
AST:
抽象语法树(Abstract Syntax Tree)。
这是编译器将源代码解析成的树状结构,表示语法结构。
Triton-IR:
Triton 中间表示(Intermediate Representation)。
这是Triton编译器内部使用的一种中间表示,用于将代码转换为 GPU 代码之前的步骤。
TritonGPU-IR:
Triton GPU 中间表示。
专门针对 GPU 的中间表示,用于进一步优化和转换为具体的 GPU 指令。
LLVM-IR:
LLVM 中间表示。
底层系统中间表示,能够被转换为具体目标机器代码。LLVM 就不解释了,看懂的不用解释,看不懂的也不需要解释。。。
一年前 Triton 在代码库设计上的一些缺陷,主要体现在代码的可扩展性和可维护性方面。通过每个步骤(AST → Triton-IR → TritonGPU-IR → LLVM-IR)展示了当前的编译流程如何反映在不同分支上的重复,而这种重复正是导致代码库难以扩展和维护的原因。这张图强调了需要一种更好的方法来简化和统一编译流程,使得代码库更具扩展性和可维护性。所以下一年,Triton 需要在软件结构上加强了“sharing a core infrastructure”的设计

(别忘了初心啊)
然后Pytorch社区更是高举大旗支持Triton(它俩毕竟有共同的利益,就是跨平台的无缝化)
Torch2.4以后,在CUDA free的情况下,在推理上已经能达到CUDA的百分之80左右,以下是上一年的数据
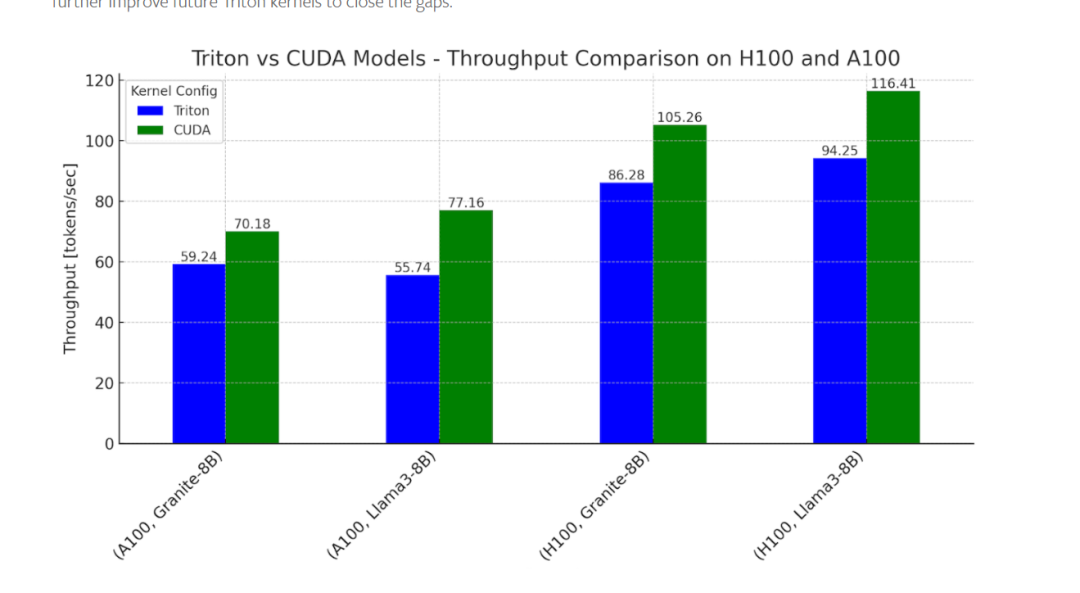

大会上最新的数据,Triton在H100,也就是Hopper架构上,已经干了CuBLAS了(其实我的demo也在局部能生出一些)
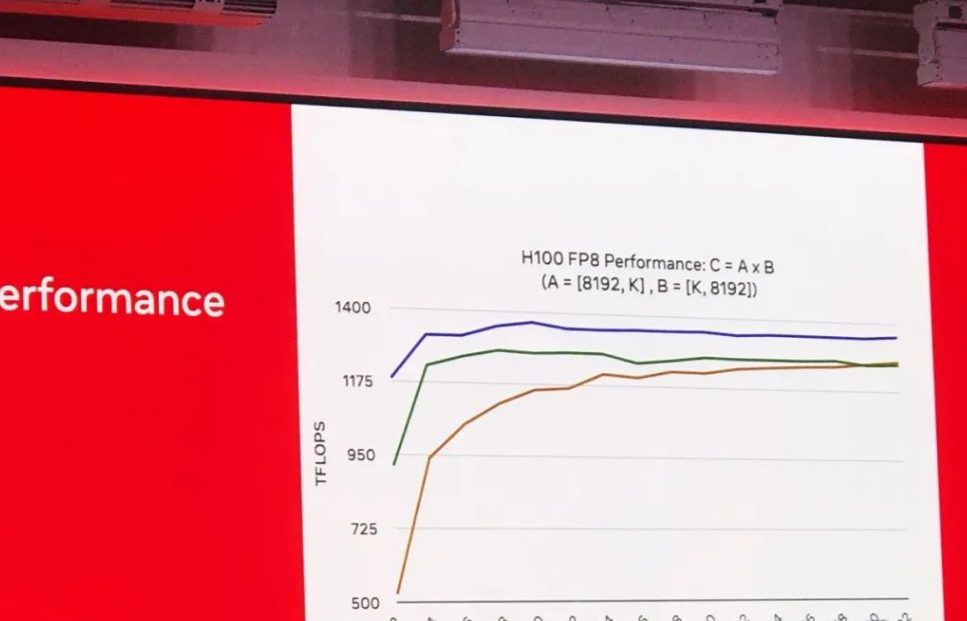
绿色是cuBLAS,黄色是上一年的Triton战绩,蓝色是今年的。
我现在做不了cuda free,因为我环境是A10的(玩不到AMD的卡,我只有MI25,支持不了Triton),但是我的矩阵乘的函数是拿Triton写的,一会看个意思就行
import torch # 导入 PyTorch 库,用于生成张量和调用矩阵乘法函数
import triton # 导入 Triton 库,用于编写和运行自定义 GPU 内核
import triton.language as tl # 导入 Triton 语言模块,用于编写 Triton 内核# 判断当前是否使用 CUDA
def is_cuda():return triton.runtime.driver.active.get_current_target().backend == "cuda"# 定义 CUDA 平台的自动调优配置,拿triton来干这事
def get_cuda_autotune_config():return [triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 64, 'GROUP_SIZE_M': 8}, num_stages=3, num_warps=8),triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),# 如果想加更多配置,就在这triton.Config]# 获取 CUDA 的自动调优配置
def get_autotune_config():return get_cuda_autotune_config()# 设置参考库,CUDA 平台使用 cuBLAS
ref_lib = 'cuBLAS'# 配置基准测试,我是A10就拿FP16就完了
configs = [triton.testing.Benchmark(x_names=["M", "N", "K"], x_vals=[128 * i for i in range(2, 33)], line_arg="provider", line_vals=[ref_lib.lower(), "triton"], line_names=[ref_lib, "Triton"], styles=[("green", "-"), ("blue", "-")], ylabel="TFLOPS", plot_name="matmul-performance-fp16", args={}, )
]# 定义 Triton 的矩阵乘法内核
@triton.jit
def matmul_kernel(a_ptr, b_ptr, c_ptr, M, N, K, stride_am, stride_ak, stride_bk, stride_bn, stride_cm, stride_cn,BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr, BLOCK_SIZE_K: tl.constexpr, GROUP_SIZE_M: tl.constexpr):pid = tl.program_id(axis=0) # 获取程序 IDnum_pid_m = tl.cdiv(M, BLOCK_SIZE_M) # 沿 M 轴的线程块数量num_pid_n = tl.cdiv(N, BLOCK_SIZE_N) # 沿 N 轴的线程块数量num_pid_in_group = GROUP_SIZE_M * num_pid_n # 每组线程块的数量group_id = pid // num_pid_in_group # 计算当前块所属的组 IDfirst_pid_m = group_id * GROUP_SIZE_M # 当前组中第一个线程块的 M 轴 IDgroup_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M) # 当前组的实际大小pid_m = first_pid_m + ((pid % num_pid_in_group) % group_size_m) # 当前线程块在 M 轴的 IDpid_n = (pid % num_pid_in_group) // group_size_m # 当前线程块在 N 轴的 IDoffs_am = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M # A 矩阵的行偏移offs_bn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N # B 矩阵的列偏移offs_k = tl.arange(0, BLOCK_SIZE_K) # K 维度的偏移a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak) # A 矩阵块的指针b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn) # B 矩阵块的指针accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32) # 初始化累加器for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)): # 遍历 K 维度的块a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k * BLOCK_SIZE_K, other=0.0) # 加载 A 块b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k * BLOCK_SIZE_K, other=0.0) # 加载 B 块accumulator = tl.dot(a, b, accumulator) # 计算并累加结果a_ptrs += BLOCK_SIZE_K * stride_ak # 更新 A 块指针b_ptrs += BLOCK_SIZE_K * stride_bk # 更新 B 块指针c = accumulator.to(tl.float16) # 将结果转为 float16offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M) # C 矩阵的行偏移offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N) # C 矩阵的列偏移c_ptrs = c_ptr + stride_cm * offs_cm[:, None] + stride_cn * offs_cn[None, :] # C 矩阵块的指针c_mask = (offs_cm[:, None] < M) & (offs_cn[None, :] < N) # 计算 C 块的有效掩码tl.store(c_ptrs, c, mask=c_mask) # 存储结果到 C 块# 定义 matmul 函数,用于调用 Triton 内核
def matmul(a, b):M, K = a.shape # 获取 A 矩阵的维度K, N = b.shape # 获取 B 矩阵的维度c = torch.empty((M, N), device=a.device, dtype=a.dtype) # 创建空的 C 矩阵stride_am, stride_ak = a.stride() # 获取 A 矩阵的步长stride_bk, stride_bn = b.stride() # 获取 B 矩阵的步长stride_cm, stride_cn = c.stride() # 获取 C 矩阵的步长grid = lambda META: (triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(N, META['BLOCK_SIZE_N']),) # 定义网格大小matmul_kernel[grid](a, b, c, M, N, K, stride_am, stride_ak, stride_bk, stride_bn, stride_cm, stride_cn,BLOCK_SIZE_M=128, BLOCK_SIZE_N=128, BLOCK_SIZE_K=64, GROUP_SIZE_M=8) # 调用内核return c# 基准测试函数,使用装饰器添加自动性能报告功能
@triton.testing.perf_report(configs)
def benchmark(M, N, K, provider):a = torch.randn((M, K), device='cuda', dtype=torch.float16) # 生成随机 A 矩阵b = torch.randn((K, N), device='cuda', dtype=torch.float16) # 生成随机 B 矩阵quantiles = [0.5, 0.2, 0.8] # 性能衡量的分位数if provider == ref_lib.lower():# 使用参考库进行基准测试,这个是调torch+cuBLASms, min_ms, max_ms = triton.testing.do_bench(lambda: torch.matmul(a, b), quantiles=quantiles)if provider == 'triton':# 使用 Triton 进行基准测试,这个就是调的triton写的矩阵乘方法ms, min_ms, max_ms = triton.testing.do_bench(lambda: matmul(a, b), quantiles=quantiles)perf = lambda ms: 2 * M * N * K * 1e-12 / (ms * 1e-3) # 计算性能(TFLOPS)return perf(ms), perf(max_ms), perf(min_ms)# 运行基准测试并显示结果
benchmark.run(show_plots=True, print_data=True)这个代码的目的是使用 Triton 和 cuBLAS 在 NVIDIA A10 GPU 上进行矩阵乘法的性能基准测试,比较两者的计算效率。:总体流程和概念 1. 导入库:导入需要的 PyTorch (他就是直接调cuda的cuBLAS了)和 Triton 库。
2. 定义配置和判定函数: - 为 CUDA 平台定义自动调优配置。 - 确定参考库为 cuBLAS。
3. 配置基准测试:设置基准测试参数,定义不同库(cuBLAS 和 Triton)的测试配置。
4. 定义矩阵乘法内核:编写 Triton 的矩阵乘法内核,通过自动调优,优化内核性能。
5. 定义矩阵乘法函数:调用 Triton 定义的内核实现矩阵乘法。
6. 定义基准测试函数:通过对比 cuBLAS 和 Triton 的矩阵乘法性能,测量各自的执行时间和性能(TFLOPS)。这样可以整体地对比 Triton 和 cuBLAS 矩阵乘法性能
主要PK的就是这块
if provider == ref_lib.lower():# 使用参考库进行基准测试,这个是调torch+cuBLASms, min_ms, max_ms = triton.testing.do_bench(lambda: torch.matmul(a, b), quantiles=quantiles)if provider == 'triton':# 使用 Triton 进行基准测试,这个就是调的triton写的矩阵乘方法ms, min_ms, max_ms = triton.testing.do_bench(lambda: matmul(a, b), quantiles=quantiles)
深度学习玩啥啊?说来说去,要涉及性能的,不就是玩矩阵乘么(当然激活函数啥也算,triton也一样都行,我在这就展示矩阵乘就可以了)
显存占的不多,我的矩阵M*K和K*N也没多大,但是GPU的tflops打上去了,虽然也打不满,毕竟维度太小,看个意思。
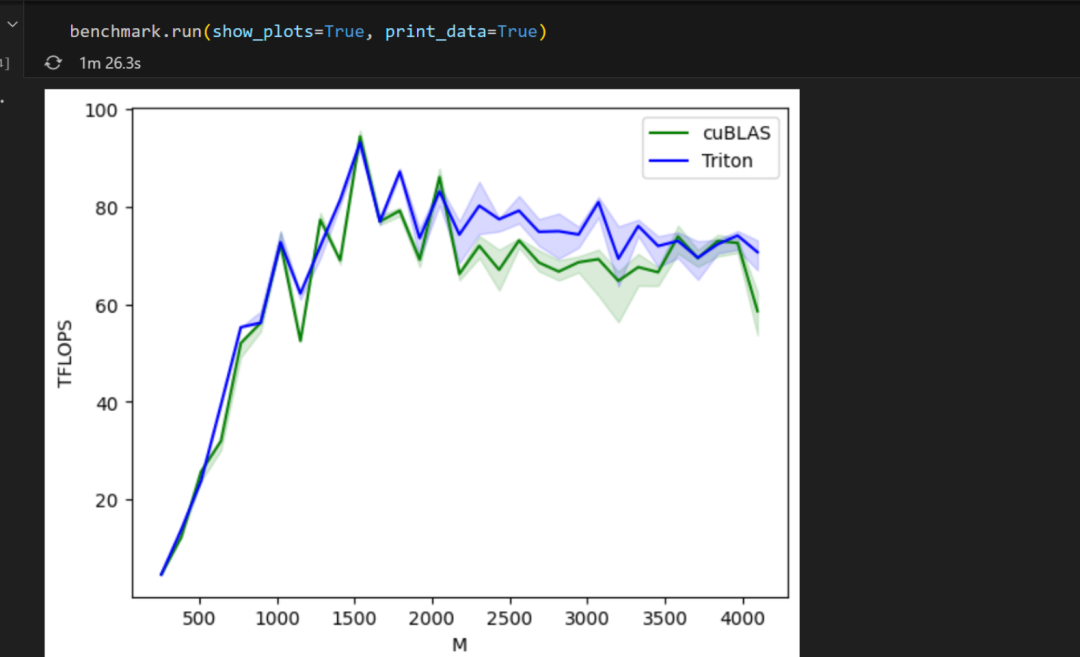
-
低维矩阵(M < 1000):
-
Triton 和 cuBLAS 性能差不多,二者的线条几乎重合。
-
-
中间区域(1000 < M < 3000):
-
在这一范围内,Triton 的蓝线稍高于 cuBLAS 的绿线,说明 Triton 的性能略高于 cuBLAS。
-
特别是在 M 达到 2000 左右时,Triton 的性能达到峰值,接近 100 TFLOPS。
-
-
高维矩阵(M > 3000):
-
在这个范围内,两者的性能开始趋于稳定,Triton 和 cuBLAS 的性能非常接近。
-
性能的微小波动可能是由于硬件和算法的微小差异导致的。
-
在A10这种破烂卡上面,都能咬住CUDA在矩阵乘上面的实力,我还是挺震惊的,之前那个Hopper架构上今年已经超过CUDA了,应该所言非虚,那剩下的,我们就指望着Triton能在非NV的卡上,能跑出同等级NV卡的能力,哪怕差点不多,那个时候可能真的就要变天了,因为天下苦NV久矣,不是苦它的sm数量和hbm速度,这玩意都能弄,主要是编算子太难了,又费劲,又少,OpenAI的Triton之所以以后一定能行,就因为它是OpenAI的项目,你觉得它缺算子么?





进程通信演示 c++(2))













