文章目录
- 华为云云耀云服务器L实例评测|华为云上安装kafka
- 一、kafka介绍
- 二、华为云主机准备
- 三、kafka安装
- 1. 安装什么版本java
- 2. 安装zookeeper服务
- 3. 使用systemctl 管理启动ZooKeeper服务
- 4. 修改kafka配置
- 5. 使用systemctl 管理启动kafka服务
- 6. 创建一个测试 topic
- SASL_PLAINTEXT 和 PLAINTEXT基础
- 创建一个测试 topic
- SASL/PLAIN客户端配置(当服务端配置启用了SASL/PLAIN,那么Client连接的时候需要配置认证信息)
- 7. 发送并消费一条测试消息
- 8. 过程遇到问题
- 创建主题报错:NFO [SocketServer listenerType=ZK_BROKER, nodeId=0] Failed authentication with /127.0.0.1 (channelId=127.0.0.1:9092-127.0.0.1:54982-14) (Unexpected Kafka request of type METADATA during SASL handshake.) (org.apache.kafka.common.network.Selector)
- 四、Kafka图形化工具选型
- 1. EFAK(Eagle For Apache Kafka,以前称为 Kafka Eagle)
- 2. Kafka Manager
- 3. Kafka Monitor
- 参考
华为云云耀云服务器L实例评测|华为云上安装kafka
一、kafka介绍
Kafka是由LinkedIn公司开发的一款开源分布式消息流平台,由Scala和Java编写。主要作用是为处理实时数据提供一个统一、高吞吐、低延迟的平台,其本质是基于发布订阅模式的消息引擎系统。
Kafka具有以下特性:
- 高吞吐、低延迟:Kafka收发消息非常快,使用集群处理消息延迟可低至2ms。
- 高扩展性:Kafka可以弹性地扩展和收缩,可以扩展到上千个broker,数十万个partition,每天处理数万亿条消息。
- 永久存储:Kafka可以将数据安全地存储在分布式的,持久的,容错的群集中。
- 高可用性:Kafka在可用区上可以有效地扩展群集,某个节点宕机,集群照样能够正常工作。
kafka核心组件:
-
Topic
消息根据Topic进行归类,可以理解为一个队列。消息生产者产生消息时会给它贴上一个Topic标签,当消息消费者需要读取消息时,可以根据这个Topic读取特定的数据。 -
Producer
消息生产者,就是向kafka broker发消息的客户端。消息生产者,负责把产生的消息发送到Kafka服务器上。 -
Consumer
消息消费者,向kafka broker取消息的客户端。 -
Consumer Group
消费者群组,每个消息消费者可以划分为一个特定的群组。 -
broker
每个kafka实例(server),一台kafka服务器就是一个broker,一个集群由多个broker组成,一个broker可以容纳多个topic。 -
Zookeeper
依赖集群保存meta信息。
kafka是一个分布式消息队列。具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在架构设计中起到解耦、削峰、异步处理的作用。
二、华为云主机准备
-
购买华为云主机,本次评测系统如下:
 注意:本文我们采用2C4G环境测试,非2C2G~
注意:本文我们采用2C4G环境测试,非2C2G~ -
创建新的安全组,开发所有端口方便测试
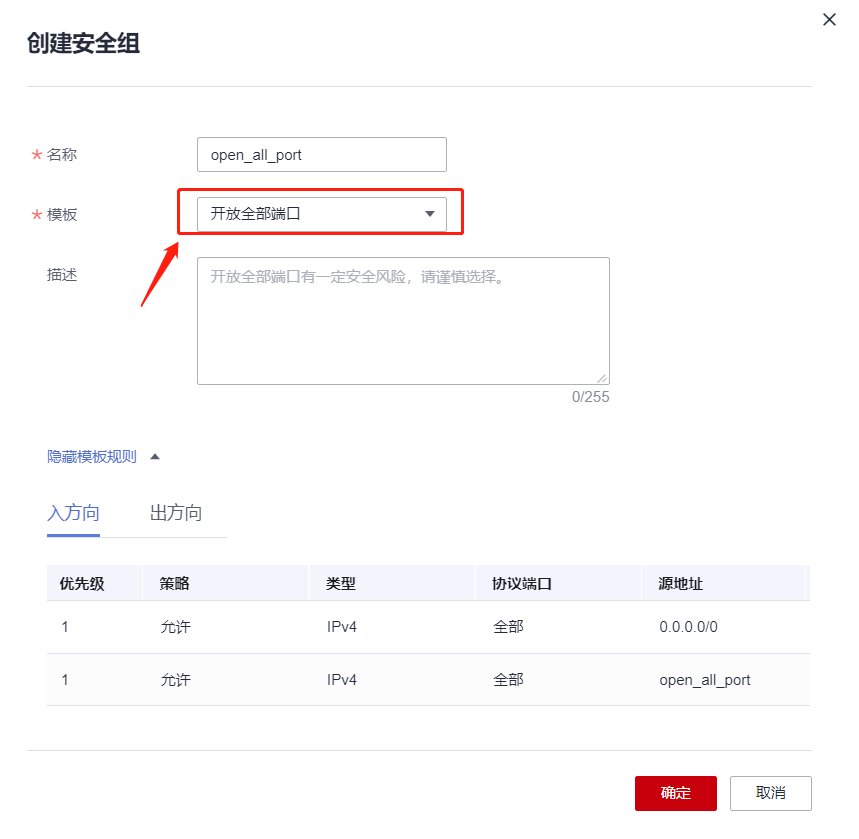
更改安全组,如下,选择我们的开发所有端口的这个安全组:
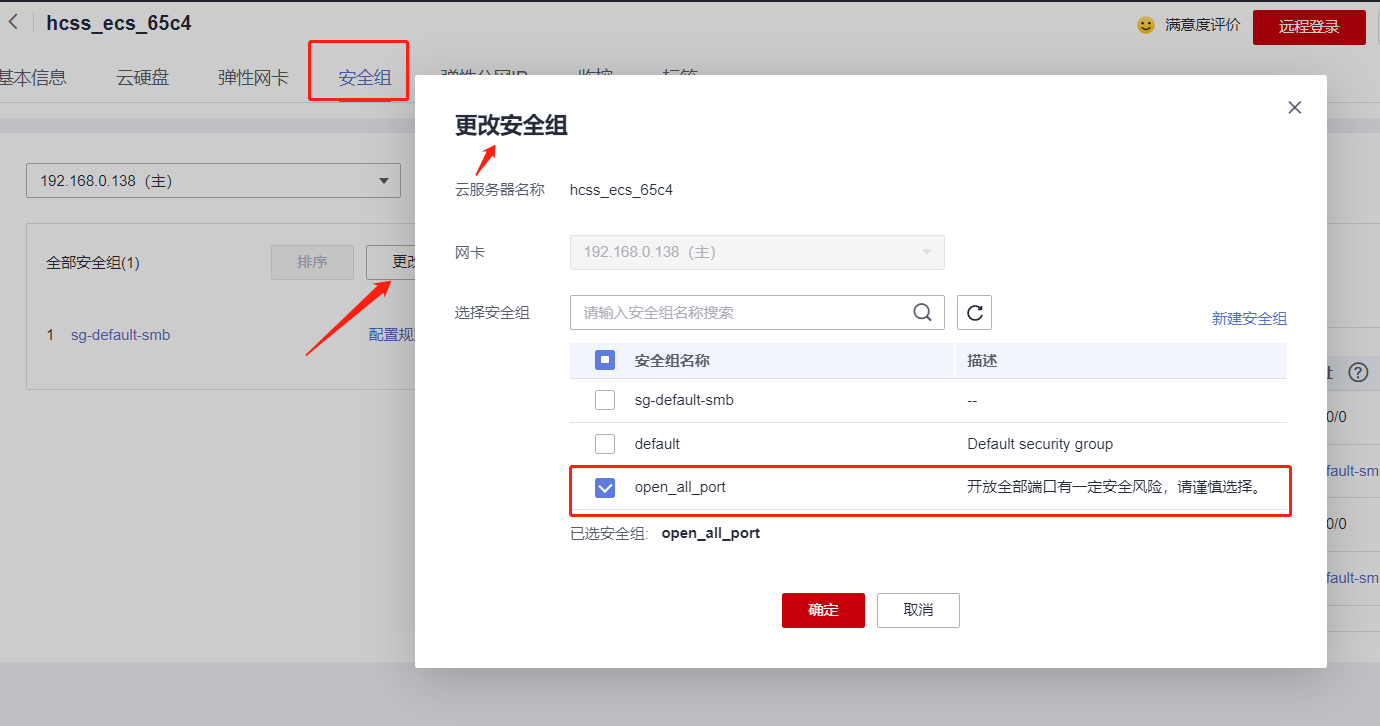
-
开发所有端口后,我们ssh登录上华为云主机即可~
三、kafka安装
官方快速开始:https://kafka.apache.org/quickstart
本文测试验证的版本信息:
kafka_2.13-3.2.3.tgz
openjdk-17.0.1_linux-x64_bin.tar.gz
1. 安装什么版本java
思路:
- 根据Kafka版本需求,下载安装对应版本的Java。
- 配置JAVA_HOME环境变量,指向Java的安装目录。
通过设置JAVA_HOME变量来配置Kafka使用特定的Java版本。
Binary downloads:
Scala 2.12 - kafka_2.12-3.5.0.tgz (asc, sha512)
Scala 2.13 - kafka_2.13-3.5.0.tgz (asc, sha512)
从Kafka的发布说明中,我们可以看到它提供了基于Scala 2.12和2.13两个版本的预编译包。
要确定使用哪个版本的Java来运行Kafka?
Scala 2.12版本需要Java 8或更高版本。而Scala 2.13版本需要Java 11或更高版本。
Kafka 提供了基于 Scala 2.12 和 2.13 两个版本的打包下载。主要区别如下:
- Scala 版本
Scala 2.12 和 2.13 是 Scala 的两个主要版本,Kafka 使用 Scala 进行开发,所以需要对应不同的 Scala 版本进行编译打包。 - 兼容性
Scala 2.12 版本对老版本的兼容性较好,但是没有 Scala 2.13 新特性。Scala 2.13 删除了一些老特性,但是支持新语法。 - 运行时性能
Scala 2.13 经过优化,运行时性能较 2.12 有提升。 - 编译速度
Scala 2.13 的编译速度比 2.12 更快。 - 社区支持
Scala 2.12 还有更多的库依赖支持,社区更成熟。Scala 2.13 正在得到越来越多的支持。
综合考虑,如果要兼容老项目,需要依赖更多老库,建议选择 Scala 2.12 版本。
如果是新项目,或者需要优化运行性能,可以选择 Scala 2.13 版本。
因此,这里我们选择Scala 2.13 版本,所以这里我们选型的版本信息如下:
kafka_2.13-3.2.3.tgz
openjdk-17.0.1_linux-x64_bin.tar.gz
二进制安装openjdk直接解压即可,例如:
#!/bin/bash
if [ ! -d "/myproject/kafka/jdk-17.0.1/" ];thentar -xf openjdk-17.0.1_linux-x64_bin.tar.gz -C /myproject/kafka/
2. 安装zookeeper服务
kafka需要依赖ZK,安装包中已经自带了一个ZK,也可以改成指定已运行的ZK。如果改成指定的ZK需要修改 kafka 安装目录下的 config/server.properties 文件中的 zookeeper.connect 。这里使用自带的ZK。只需修改配置文件,启动即可。
kafka正常运行,必须配置zookeeper,否则无论是kafka集群还是客户端的生存者和消费者都无法正常的工作的;所以需要配置启动zookeeper服务。
- 首先下载安装kafka:
wget https://archive.apache.org/dist/kafka/3.5.0/kafka_2.12-3.5.0.tgz
tar -xzf kafka_2.12-3.5.0.tgz
cd kafka_2.12-3.5.0
- 修改zookeeper配置
zookeeper.properties:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# the directory where the snapshot is stored.
# 数据快照文件存储的目录
dataDir=/opt/lighthouse/server/env/kafka/zookeeper
# the port at which the clients will connect
# clientPort
# 客户端连接的端口
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
# 最大客户端连接数,这里设置为0表示无限制
maxClientCnxns=0
# Disable the adminserver by default to avoid port conflicts.
# Set the port to something non-conflicting if choosing to enable this
# 默认情况下该功能是关闭的。如果设置为true,则会启动一个嵌入式的 Jetty 服务器,默认端口号为8080。
# admin.enableServer 主要目的是提供便捷的监控和管理功能。在需要调试查看服务器状态或者管理集群时开启使用。但正常运行时开启该功能会增加一些系统开销。
admin.enableServer=false
# 初始化连接时的最长时间,单位TickTime。TickTime 指定了 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是定时心跳(heartbeat)的周期。默认情况下 TickTime 是 2000 毫秒,也就是 2 秒。
initLimit=5
# 发送请求和接收响应之间的最长时间,单位TickTime
syncLimit=2
# admin.serverPort=8080
# 允许所有四字命令 四字命令(Four Letter Words)是 Zookeeper 提供的一些简单的命令,用于查询服务器的状态。
# 这些命令全部是4个字母的字符串,通过 telnet 或 nc 向 Zookeeper 服务器的客户端端口(默认2181)发送四字命令
# Zookeeper 支持的四字命令包括:
# - conf:输出相关服务配置的详细信息。
# - cons:列出所有连接到服务器的客户端连接/会话的详细信息。
# - crst:重置当前这台服务器所有连接/会话的统计信息。
# - dump:列出未完成的会话和临时节点。
# - envi:输出关于服务器环境的详细信息。
# - ruok:测试服务是否处于正确运行状态,如果正常返回"imok",否则不做任何响应。
# - stat:输出关于客户端连接数,接收/发送包数量等的简要信息。
# - srst:重置 server stat 中的统计信息。
# - wchs:列出服务器 watch 的简单信息。
# - wchc:通过 session 列出服务器 watch 的详细信息。
# - wchp:通过路径列出服务器 watch 的详细信息。
4lw.commands.whitelist=*# 集群中参与的服务器,每一行配置一个
# server.id=host:port:port
# 其中第一个port是 follower 与 leader 通信的端口,第二个port是 leader选举的端口。
# 这里配置的是Zookeeper集群,所以使用了同一个IP,不同的端口号(12888和13888)来区分不同的Zookeeper节点。实际生产环境中,不同的Zookeeper服务器应该使用不同的IP地址,而不是同一个IP。
# 配置文件中的ip地址主要用于集群模式,让集群中的其他zookeeper节点能够互相访问。
# 但在单机模式下,它用不到这个配置的ip地址,直接使用当前进程的主机ip就可以了。
# 即使配置的ip地址不正确,也不会影响单机模式下zookeeper的启动。# 12888端口在Zookeeper中用于follower与leader之间的通信。13888端口用于leader选举过程中的通信。这两类通信在单机模式下都是不需要的。
# follower与leader通信在单机模式下不需要,因为只有一个server,不存在follower和leader的概念。 这两类通信在单机模式下都是不需要的。
server.1=10.248.172.114:12888:13888
server.1=10.248.172.114:12888:13888
server.1=127.0.0.1:12888:13888
3. 使用systemctl 管理启动ZooKeeper服务
kafka_zookeeper.server,这里直接使用Kafka中包含的脚本即可,封装在systemd配置文件中~
[Unit]
Description=Apache Zookeeper server (Kafka)
Documentation=http://zookeeper.apache.org
Requires=network.target remote-fs.target
After=network.target remote-fs.target[Service]
Environment="KAFKA_HEAP_OPTS=-Xmx256M -Xms256M"
Type=simple
Restart=always
Environment=JAVA_HOME=/opt/lighthouse/server/env/kafka/jdk-17.0.1
WorkingDirectory=/opt/lighthouse/server/env/kafka
ExecStart=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/bin/zookeeper-server-start.sh /opt/lighthouse/server/conf/zookeeper/zookeeper.properties
ExecStop=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/bin/zookeeper-server-stop.sh
CPUQuota=25%
MemoryMax=512M
MemoryLimit=512M[Install]
WantedBy=multi-user.target
sudo rm -rf /etc/systemd/system/kafka_zookeeper.servicesudo cp $SERVER_CONF_PATH/kafka_zookeeper.service /etc/systemd/system/kafka_zookeeper.service
sudo systemctl daemon-reload
sudo systemctl enable kafka_zookeeper
sudo systemctl restart kafka_zookeeper
4. 修改kafka配置
server.propertiesn:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.# see kafka.server.KafkaConfig for additional details and defaults############################# Server Basics ############################## The id of the broker. This must be set to a unique integer for each broker.
# broker.id 配置 broker id,要求每个 broker 的 id 唯一
broker.id=0############################# Socket Server Settings ############################## The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092security.inter.broker.protocol=SASL_PLAINTEXT
sasl.mechanism.inter.broker.protocol=PLAIN
# sasl.enabled.mechanisms - 启用的 SASL 机制,比如 PLAIN、SCRAM
sasl.enabled.mechanisms=PLAIN# - SASL 表示启用了 SASL(Simple Authentication and Security Layer)机制的安全连接。SASL 提供了 Kafka 客户端与 broker 之间的安全认证。
# - PLAINTEXT 表示未加密的 claro 连接。这主要用于开发环境,生产环境更推荐使用 SSL 加密连接。
listeners=SASL_PLAINTEXT://127.0.0.1:9092# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
# 这个配置的作用是让客户端能够连接到 broker 的外网地址,而不是只能连接到内网地址。
# 原因是 Kafka broker 在集群内部的地址(listeners 配置)可能是一个不可路由的内网地址,如 192.168.0.1。这样外部客户端无法连接。
# 为了让外部客户端可以连接,需要配置一个外网可路由的地址,如公网 IP,然后通过 advertised.listeners 把这个地址暴露给客户端。
advertised.listeners=SASL_PLAINTEXT://127.0.0.1:9092# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the network
# 配置网络线程数
num.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/O
# 配置 IO 线程数
num.io.threads=8# socket.send.buffer.bytes 和 socket.receive.buffer.bytes 配置 socket 发送/接收缓冲区大小
# The send buffer (SO_SNDBUF) used by the socket server
# 配置日志存放目录
socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log files
# log.dirs 指定的是 Kafka broker 的消息日志(log)所在的目录。Kafka 的消息数据是以日志文件的形式保存在这个目录下的。
# 注意:log.dirs 这与 Kafka 自身的运行日志是不同的,指定的路径是用来存储 Kafka 中主题和分区的日志数据。 log.dirs 配置的目录可以视为 Kafka 的“数据目录”,而不是“日志目录”。
log.dirs=/opt/lighthouse/server/env/kafka/kafka-logs# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
# 配置 topic 的默认分区数
num.partitions=12# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
# 配置每个数据目录恢复线程数
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
# 配置内部 offsets topic 的副本数
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk
# 这个配置项用于控制 Kafka 将消息日志 flush 到磁盘的频率
# 它的作用是配置每累积多少条消息,Kafka 就将消息日志 flush 到文件系统一次。
# 默认值为 9223372036854775807,即最大 long 值。这意味着不会按消息条数进行 flush。
#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=2
# 日志段滚动的时间间隔。当达到这个时间,会创建一个新的日志段。默认是168小时,这里设置为1小时。
log.roll.hours = 1
retention.ms = 3600000
log.retention.check.interval.ms = 120000
log.cleanup.interval.mins = 5
log.segment.delete.delay.ms = 60000
# 是否启用日志压缩。默认true。压缩可以减少磁盘使用。
log.cleaner.enable=true# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.
# 根据日志总大小保留日志的策略。当前日志段总和大于该值时,会删除旧的段。默认是-1,即不限制大小。这里是150GB。
log.retention.bytes = 16106127360
# 每个日志段的大小,达到该值时会创建新段。默认1GB,这里是500MB。
log.segment.bytes = 536870913# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
# 检查日志是否可以被删除的时间间隔。默认5分钟。
log.retention.check.interval.ms=300000############################# Zookeeper ############################## Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=127.0.0.1:2181# Timeout in ms for connecting to zookeeper
# 连接Zookeeper的超时时间,默认6秒。
zookeeper.connection.timeout.ms=60000############################# Group Coordinator Settings ############################## The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0# 控制 replica 在从 leader 中 fetch 消息时,每次能拉取的最大字节数。
# 默认是 1048576 bytes,这里增加到 20MB。增大这个值可以减少 follower 频繁地向 leader 发起复制请求。
replica.fetch.max.bytes=20971520# 控制 kafka 中消息体的最大大小,默认是1000012 bytes。这里增加到20MB,允许发送更大的消息。但消息不能超过这个最大值。
message.max.bytes=20971520
5. 使用systemctl 管理启动kafka服务
kafka.service:
[Unit]
Description=Apache Kafka server (broker)
Documentation=http://kafka.apache.org/documentation.html
Requires=network.target remote-fs.target
After=network.target remote-fs.target kafka_zookeeper.service[Service]
CPUQuota=200%
MemoryMax=4G
MemoryLimit=4G
Environment="KAFKA_HEAP_OPTS=-Xmx2048M -Xms2048M"
Environment="KAFKA_JVM_PERFORMANCE_OPTS=-XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80 -XX:+ExplicitGCInvokesConcurrent"
Environment="KAFKA_OPTS=-Djava.security.debug=jaas -Djava.security.auth.login.config=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/config/kafka_server_jaas.conf"
Type=simple
Restart=always
LimitNOFILE=1024768
LimitNOFILE=1024768
Environment=JAVA_HOME=/opt/lighthouse/server/env/kafka/jdk-17.0.1
WorkingDirectory=/opt/lighthouse/server/env/kafka
ExecStart=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/bin/kafka-server-start.sh /opt/lighthouse/server/conf/kafka/server.properties
ExecStop=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/bin/kafka-server-stop.sh[Install]
WantedBy=multi-user.target
启动kafka:
sudo rm -rf /etc/systemd/system/kafka.service
sudo cp $SERVER_CONF_PATH/kafka.service /etc/systemd/system/kafka.servicesudo systemctl daemon-reload
sudo systemctl enable kafka
sudo systemctl restart kafka
注意: Environment="KAFKA_OPTS=-Djava.security.debug=jaas -Djava.security.auth.login.config=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/config/kafka_server_jaas.conf"
对于kafka服务我们用配置 kafka_server_jaas.conf,kafka客户端我们用配置kafka_client_jaas.conf
这个配置比较重要~
6. 创建一个测试 topic
SASL_PLAINTEXT 和 PLAINTEXT基础
SASL(Simple Authentication and Security Layer)即简单认证和安全层,是一种用于添加认证支持的应用层网络协议。
JAAS(Java Authentication and Authorization Service)是Java的认证和授权服务。Kafka使用JAAS来实现SASL认证和授权。
kafka配置如下:
listeners=SASL_PLAINTEXT://127.0.0.1:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
# 这个配置的作用是让客户端能够连接到 broker 的外网地址,而不是只能连接到内网地址。
# 原因是 Kafka broker 在集群内部的地址(listeners 配置)可能是一个不可路由的内网地址,如 192.168.0.1。这样外部客户端无法连接。
# 为了让外部客户端可以连接,需要配置一个外网可路由的地址,如公网 IP,然后通过 advertised.listeners 把这个地址暴露给客户端。
advertised.listeners=SASL_PLAINTEXT://127.0.0.1:9092 是这样配置的呀
SASL_PLAINTEXT是启用了SASL鉴权的PLAINTEXT协议,这会导致不使用SASL的客户端无法连接。
如果你只需要内部使用,推荐还是使用PLAINTEXT协议,配置起来简单,无需SASL设置。 只有在需要验证客户端身份的时候,才需要用SASL_PLAINTEXT。
可以这样修改Kafka配置来关闭SASL认证:
# 注释或者删除与SASL相关的配置
#security.inter.broker.protocol=SASL_PLAINTEXT
#sasl.mechanism.inter.broker.protocol=PLAIN
#sasl.enabled.mechanisms=PLAINlisteners=PLAINTEXT://0.0.0.0:9092
advertised.listeners=PLAINTEXT://localhost:9092# 删除sasl.jaas.config
这里我们主要演示有账号密码的情况:
Kafka 服务器端的 SASL 认证配置是通过JAAS机制来管理的,主要是通过kafka_server_jaas.conf文件进行配置。
kafka_server_jaas.conf 内容:
KafkaServer {org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="admin"password="elkeid"user_admin="elkeid"user_alice="elkeid";
};
我们需要修改官方自带脚本 kafka-run-class.sh 添加如下配置,指定使用kafka_server_jaas.conf文件:
我们自定义一个 KAFKA_SASL_OPTS 环境变量
KAFKA_SASL_OPTS 这个环境变量是用于指定 Kafka 进程的 SASL 相关 JAAS 配置的。
- -Djava.security.auth.login.config:这是设置JAAS登录配置文件的Java系统属性。
- /xxx/kafka/kafka_2.13-3.2.3/config/kafka_server_jaas.conf:这是JAAS配置文件的路径。
这个环境变量的效果是: - 为Kafka进程指定JAAS配置文件路径为/xxx/kafka/kafka_2.13-3.2.3/config/kafka_server_jaas.conf
- Kafka进程启动时会加载这个JAAS配置文件来获取SASL认证相关的配置。
KAFKA_SASL_OPTS=“-Djava.security.auth.login.config=/xxx/kafka/kafka_2.13-3.2.3/config/kafka_server_jaas.conf”

思路总结:通过修改官方的kakfa启动脚本 kafka-run-class.sh 为 Kafka 指定 JAAS 配置文件了。在启动 Kafka 进程的命令中,添加这个变量。
经过测试验证,不推荐这个实现方案。如果你不用官方客户端其他脚本,你可以这么改,因为
最好也不要在 kafka-run-class.sh 中硬编码其他配置,而是通过环境变量传递,保持脚本的通用性。
思路1:这里可以模仿
if [ -z "$KAFKA_OPTS" ]; thenKAFKA_OPTS=""
fi
通过在 kafka-run-class.sh 脚本中添加类似的逻辑,可以实现自定义 JAAS 配置文件路径的功能:
# JAAS configuration
if [ -z "$KAFKA_SASL_OPTS" ]; thenKAFKA_SASL_OPTS=""
fi
然后在启动 Kafka 时,如果需要使用非默认的 JAAS 配置:
export KAFKA_SASL_OPTS="-Djava.security.auth.login.config=/custom/jaas.conf"
过 export KAFKA_SASL_OPTS 就可以轻松地切换不同的 JAAS 配置文件了。相比于硬编码指定 JAAS 文件路径,这样实现起来更加灵活通用。
思路2:完全不用改造官方脚本,官方的脚本的 KAFKA_OPTS 环境变量就可以满足我们需求。
export KAFKA_OPTS="-Djava.security.debug=jaas -Djava.security.auth.login.config=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/config/kafka_client_jaas.conf"
注意:这里使用 kafka_client_jaas.conf
这里 我推荐 使用思路2。
创建一个测试 topic
加载java环境变量,让可以找到java
export JAVA_HOME=/opt/lighthouse/server/env/kafka/jdk-17.0.1
进入kafka安装目录:
cd /opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/
./bin/kafka-topics.sh --create --topic test --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092
如果没有错误,表明可以成功创建 topic。
但是我们kafka服务其实配置了SASL/PLAIN是基于账号密码的认证方式,所以这里应该会报错。
因此,我们需要配置修改官方客户端操作相关脚本,让其支持账号密码访问kafka。
SASL/PLAIN客户端配置(当服务端配置启用了SASL/PLAIN,那么Client连接的时候需要配置认证信息)
客户端连接启用了 SASL 认证的服务端时,需要在客户端配置中指明:
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
这两个参数分别指定:
- 使用 SASL_PLAINTEXT 协议进行通信
- 采用 PLAIN 机制进行用户名密码验证
可以在客户端的配置文件(比如 consumer.properties, producer.properties 等)中添加
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
具体操作步骤如下:
- 在kafka/config目录下新增
jaas.properties配置文件,配置SASL,指明客户端使用的安全协议和验证机制,与服务端保持一致。
vi jaas.properties
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
一旦客户端和服务端的 SASL 参数一致后,在有了正确的 Jaas 配置的情况下,客户端应该就可以成功地通过 SASL/PLAIN 方式与服务端建立连接了。
- 在kafka/config目录下新增
kafka_client_jaas.conf配置文件,指定用户登录账号信息
KafkaClient {org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="admin"password="elkeid";
};
注:此处的用户需要按照服务端kafka-server-jaas.conf配置文件中配置的用户配置,否则会报错
- kafka-topics.sh,kafka-console-producer.sh,kafka-console-consumer.sh文件操作kafka
kafka/bin目录下的kafka-topics.sh,kafka-console-producer.sh,kafka-console-consumer.sh文件,增加如下配置
此处以kafka-topics.sh 作为示例,指定kafka_client_jaas.conf配置文件目录
以 kafka-topics.sh 为例,我们创建一个主题:
export JAVA_HOME=/opt/lighthouse/server/env/kafka/jdk-17.0.1
cd /opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/
export KAFKA_OPTS="-Djava.security.debug=jaas -Djava.security.auth.login.config=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/config/kafka_client_jaas.conf"./bin/kafka-topics.sh --create --topic test --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092 --command-config=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/config/jaas.properties
注:这里我不用自定义的KAFKA_SASL_OPTS,直接利用官方脚本中的 KAFKA_OPTS 环境变量即可,覆盖指定kafka_client_jaas.conf配置文件目录。
7. 发送并消费一条测试消息
至此,我们已经启动了kafka并且成功创建了一个topic,接下来, 我们发送并消费一条测试消息。
进入kafka安装目录:
export JAVA_HOME=/opt/lighthouse/server/env/kafka/jdk-17.0.1
cd /opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/
export KAFKA_OPTS="-Djava.security.debug=jaas -Djava.security.auth.login.config=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/config/kafka_client_jaas.conf"
生产消息:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test --producer.config=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/config/producer.properties
消费消息:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning --consumer.config=/opt/lighthouse/server/env/kafka/kafka_2.13-3.2.3/config/consumer.properties
注:producer.properties、consumer.properties默认存在, 同之前的 jaas.properties 一样, 我们追加添加配置
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
如果可以发送和接收到消息,则 Kafka 可以基本工作。
8. 过程遇到问题
创建主题报错:NFO [SocketServer listenerType=ZK_BROKER, nodeId=0] Failed authentication with /127.0.0.1 (channelId=127.0.0.1:9092-127.0.0.1:54982-14) (Unexpected Kafka request of type METADATA during SASL handshake.) (org.apache.kafka.common.network.Selector)
问题分析:
这些 “Failed authentication” 的错误表示在创建 Kafka topic 时,客户端与 broker 之间的 SASL 认证失败。
主要原因:Kafka broker 启用了 SASL 认证,但客户端连接时没有进行相应的配置。
创建 Kafka topic 时使用的是 kafka-topics.sh 这个命令行客户端。
而这个客户端默认是不会开启 SASL 认证的,所以与启用了 SASL 认证的 Kafka broker 之间无法正常认证,导致了这个问题。
问题解决:
要解决这个问题,需要在使用 kafka-topics.sh 等命令行客户端时,通过 Jaas 配置来开启 SASL 认证,步骤如下:
- 在 Kafka 配置目录下,增加 Jaas 配置文件,例如 kafka_client_jaas.conf:
KafkaClient {org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="admin"password="admin-secret";
};
- 在运行 kafka-topics.sh 命令时,添加 Jaas 配置参数:
./bin/kafka-topics.sh --create --topic test --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092 --command-config /path/to/kafka_client_jaas.conf
四、Kafka图形化工具选型
1. EFAK(Eagle For Apache Kafka,以前称为 Kafka Eagle)
源码: https://github.com/smartloli/kafka-eagle/
下载: http://download.kafka-eagle.org/
官方文档:https://www.kafka-eagle.org/articles/docs/documentation.html
EFAK(Eagle For Apache Kafka,以前称为 Kafka Eagle)是一款由国内公司开源的Kafka集群监控系统,可以用来监视kafka集群的broker状态、Topic信息、IO、内存、consumer线程、偏移量等信息,并进行可视化图表展示。独特的KQL还可以通过SQL在线查询kafka中的数据。
看了一下,代码活跃度比较高,文档也比较详尽,推荐选择该方案~
2. Kafka Manager
Kafka Manager 是由 Yahoo 开发的一个开源项目,用于管理和监控 Kafka 集群。它提供了一个用户友好的 Web UI,可以查看和管理 Kafka 的主题、消费者组、分区和偏移量等信息。
这是Yahoo开源的Kafka管理工具,更偏重于对Kafka集群指标采集,同时也有一些主题管理功能。
3. Kafka Monitor
这是LinkedIn开发的一个监控工具,可以监控Kafka集群的健康和性能,并提供基于Web的用户界面。
LinkedIn开发的Kafka监控工具非常强大,可以帮助Kafka管理员快速发现Kafka集群中的问题,并及时采取措施进行修复。
参考
kafka 安装部署配置
参考URL:https://www.cnblogs.com/yb38156/p/15978055.html
大数据Hadoop之——Kafka 图形化工具 EFAK(EFAK环境部署)
参考URL: https://blog.csdn.net/qq_35745940/article/details/124764824

用法详解)







:有序序列合并)

算法分析)







)