过犹不及——《论语·先进》
大学考试时,有些老师允许带备cheet sheet(忘纸条),上面记着关键公式和定义,帮助我们快速作答提高分数。传统的检索增强生成(RAG)方法也类似,试图找出精准的知识片段来辅助大语言模型(LLM)。
但这种方法其实有问题。因为:
-
LLM没有"老师划重点",需要自己在海量信息中寻找答案。
-
RAG是两步走:先检索,再生成。如果第一步检索就出错,再好的生成也难以弥补。
-
过分追求精准的知识片段,反而可能限制了模型的发挥空间。
所以,与其苛求检索结果的精准性,不如给模型提供更丰富的上下文信息,让它自己去理解和提炼关键知识。这样可能效果会更好。
那有没有可能让LLM不要cheet sheet,直接参加“开卷考”呢?随着现在长上下文技术(LongContext)日渐成熟,让LLM干脆带着“书”来回答问题开始成为可能。
滑铁卢大学的研究者们就做了这么一个尝试,抛开当前“长上下文党”和“RAG党”之间的争论,把“长上下文”和“RAG”整个地结合了起来,反正就是“我全都要”。至于效果嘛?据说连GPT-4也已经被“吊打”了喔~

论文链接:
https://arxiv.org/pdf/2406.15319.pdf
RAG vs LongContext?
由于LLM往往受到知识时效性和训练知识边界的限制,RAG方法被提出作为大模型的补充,RAG先检索相关信息,再用LLM生成答案。这样可以让模型获取最新外部知识,提高表现。
但是,LLM和RAG都难以处理长文本。随着RoPE和AliBI等位置编码技术,以及各种长文本训练方法的提出,模型处理更长的上下文成为可能。
有趣的是,虽然RAG和长文本LLM已经同时存在一段时间,但很少有人尝试把它们结合起来。如果能用长文本LLM来理解和提炼RAG检索到的大段信息,应该会有不错的效果。这样做可以减轻检索环节的压力,提高整体性能。
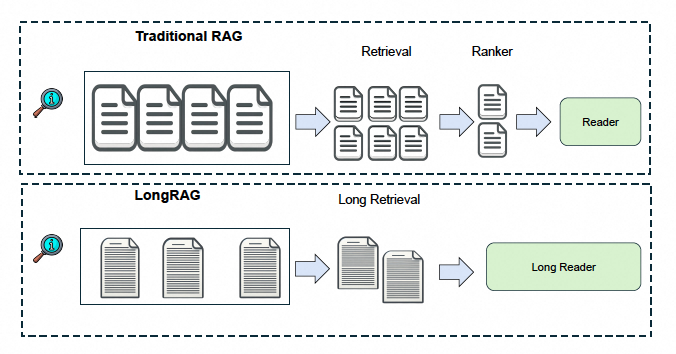
LongRAG
长上下文检索器
在传统的RAG框架中,检索器通常使用较小的检索单元,如短文本段落,并侧重于检索包含答案的精确细粒度上下文。然而,LongRAG框架中的长上下文检索器(Long Retriever)更加注重召回率,目标是检索与问题相关的上下文,但不一定是精确的答案。这种设计选择将更多的负担从检索器转移到生成器,让生成器从相关上下文中提取确切的答案。
长上下文检索的构建过程分为三个步骤:
-
首先,通过将整个维基百科文档或多个相关文档组合成一个长检索单元,形成M个检索单元。这些长检索单元通过文档内插入的超链接进行分组,确保了每个检索单元的语义完整性,并为需要多文档信息的任务提供了丰富的上下文。
-
其次,使用编码器将输入问题映射到d维向量,并使用不同的编码器将检索单元映射到相同的d维空间。通过计算问题向量和检索单元向量之间的点积来定义它们之间的相似度,并通过在检索单元内的所有块中最大化分数来近似这个相似度,从而有效地检索与给定查询最接近的top k检索单元。
-
最后,将这些检索单元串联成长上下文作为检索结果,为下一步的生成器处理提供输入。
长阅读器
长阅读器(Long Reader)是LongRAG框架中的另一个核心组件,它负责从长上下文检索器检索出的长上下文中提取答案。与传统RAG框架中的生成器不同,长阅读器处理的是大约30K tokens的长文本,这要求它能够理解和推理更长的上下文信息。
长阅读器的操作相对直接。它接收相关的指令、问题以及长上下文检索器检索出的长上下文结果,然后将这些信息输入到一个能够处理长上下文的LLM中。这个LLM需要具备处理长文本的能力,并且在处理位置信息时不应表现出明显的偏差。本文选择了在处理长上下文输入方面表现出色Gemini1.5-Pro和GPT-4o作为长阅读器。
对于不同的上下文长度,长阅读器采用了不同的策略。对于短上下文(通常少于1K tokens),它指导阅读器直接从检索到的文本中提取答案。而对于长上下文(通常超过4K tokens),直接提取答案的方法可能会导致性能下降。因此,最有效的方法是将LLM作为一个聊天模型来使用。首先,它输出一个较长的答案,可能包含几个词到几句话。然后,通过进一步的提示,引导它从长答案中提取出更短的答案。这个过程涉及到两阶段的提示。
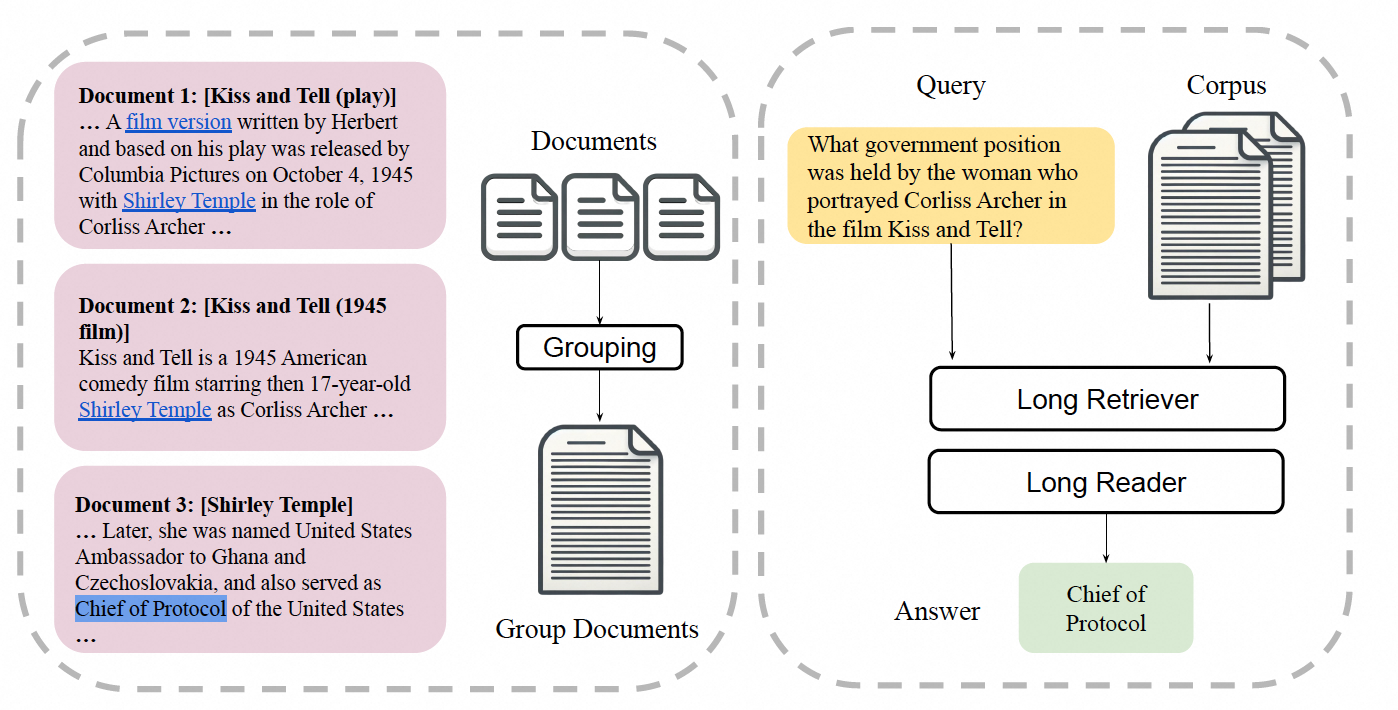
实验
数据
本文提出的LongRAG框架在两个与维基百科相关的问答数据集上进行了测试:Natural Questions(NQ)和HotpotQA。Natural Questions数据集专为端到端问答任务设计,包含3610个问题,这些问题是从真实的谷歌搜索查询中挖掘出来的,答案则是由标注者在维基百科文章中确定的文本片段。HotpotQA数据集包含多跳问题,需要两个维基百科段落来回答问题。由于测试集的目标段落不可获取,研究者遵循先前的工作,在包含7405个问题的验证集上进行评估。
对于知识源,即维基百科的不同版本,被用于不同的数据集。对于NQ,使用了2018年12月20日转储的维基百科,包含大约300万篇文档和2200万个段落。对于HotpotQA,使用了2017年10月1日转储的摘要段落,包含约500万篇文档。在处理文档时,只提取纯文本,并从文档中剥离了所有结构化数据部分,如列表、表格和图表。
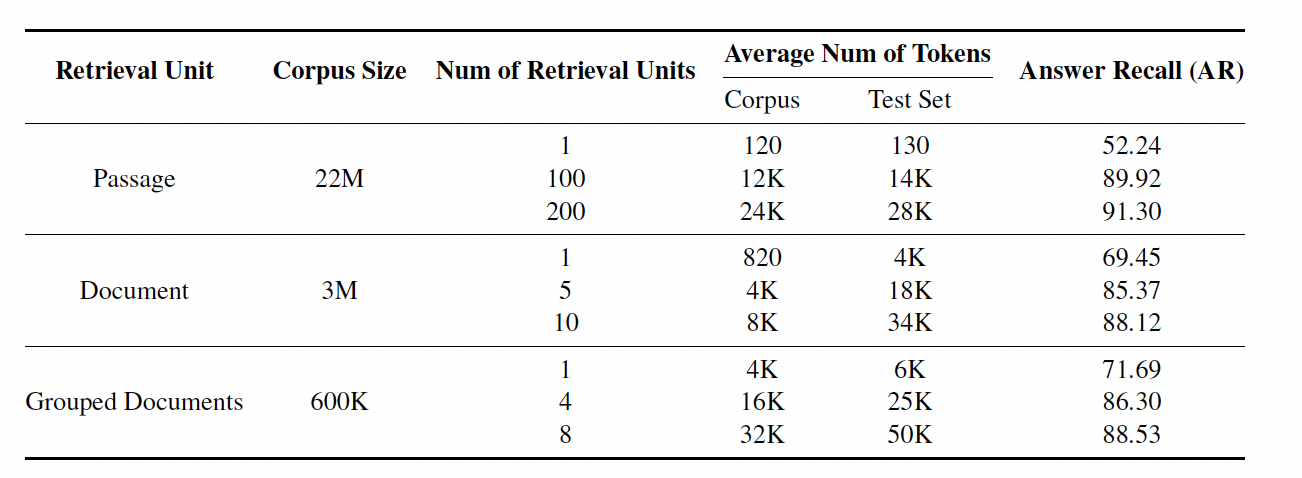
长上下文检索效果
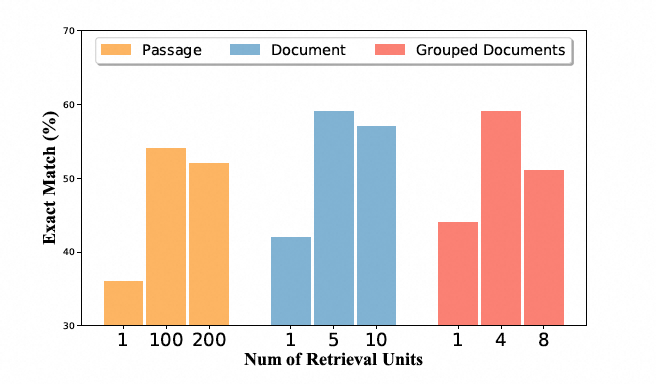
在NQ数据集中,研究者采用了三种不同长度的检索单元:段落、文档和分组文档。检索单元的长度从短到长不等,其中包括整个文档或多个相关文档的组合,平均包含4K个tokens。通过使用长上下文检索,LongRAG框架显著减少了语料库的大小,从22M减少到600K文档单元,同时显著提高了检索器的答案召回率,从52.24%提高到71.69%。此外,长检索单元的使用还显著减少了为达到可比性能所需的检索单元数量。例如,在分组文档级别,仅使用8个检索单元就可以达到与100个段落级别检索单元相似的召回率。
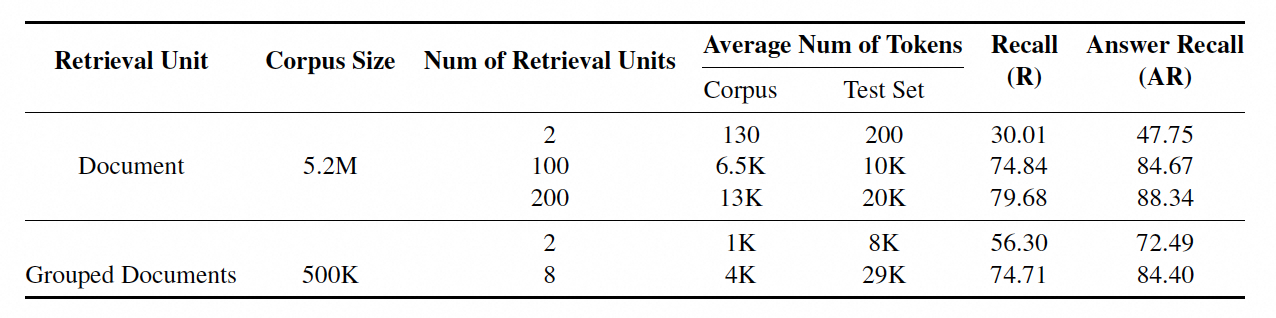
对于HotpotQA数据集,检索单元仅限于文档级别和分组文档级别。在HotpotQA中,研究者观察到类似的结果,长上下文检索显著减轻了检索组件的负担。例如,在文档级别和分组文档级别,召回率和答案召回率都有所提高。
完整表现
在NQ数据集上,LongRAG实现了62.7%的精确匹配率(Exact Match Rate),与最强的经过微调的RAG模型之一Atlas相当。
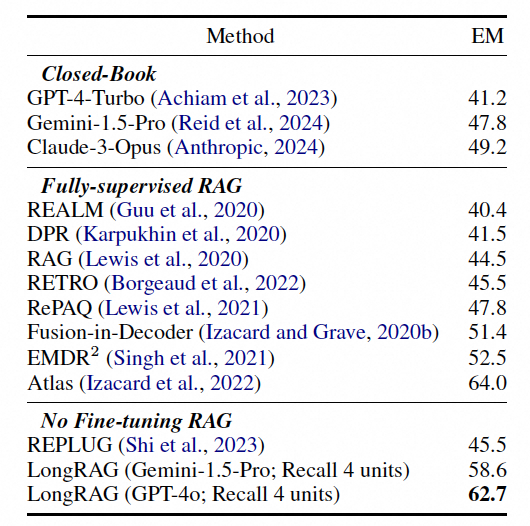
在HotpotQA数据集上,LongRAG实现了64.3%的精确匹配率,接近于最先进的全监督RAG框架。
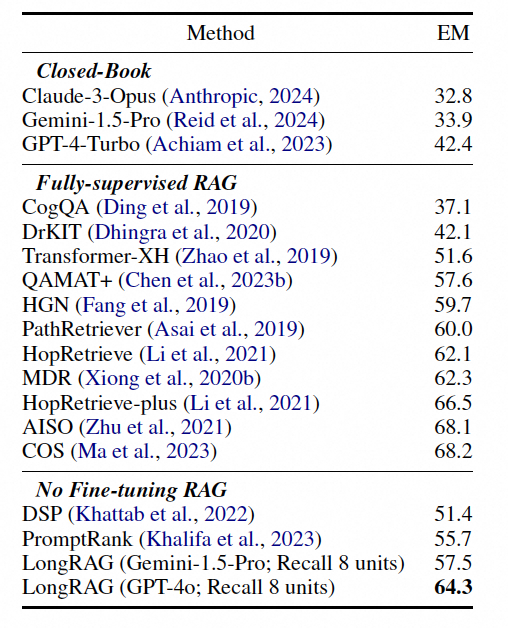
而对比GPT-4,都实现了50%的效果提升!
在评估过程中,本文还比较了不同检索单元的选择和不同数量的检索单元对性能的影响。本文发现,无论选择哪种检索单元,当向阅读器提供过多的检索单元时,性能都会达到一个转折点,之后性能会下降。这是因为过多的信息会超出阅读器的处理能力,使其无法有效地理解和提取长上下文中的相关信息。例如,在NQ数据集中,段落级别的检索单元的转折点在100到200个单元之间,而分组文档级别的检索单元的转折点在4到8个单元之间。这表明,向阅读器提供大约30K tokens的上下文长度是最适合的。
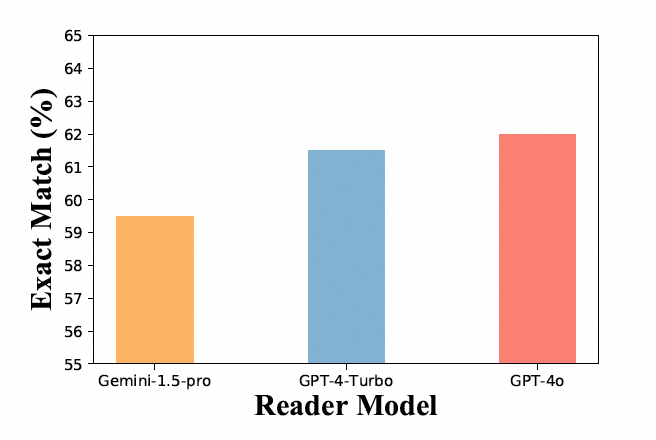
此外,本文还比较了不同的阅读器模型。在NQ数据集上,GPT-4o在200个测试问题上实现了最高的精确匹配得分,显示出其在LongRAG框架中作为长阅读器角色时最为有效。GPT-4o之所以表现出色,归功于其处理和理解长文本的能力,确保了关键信息的准确提取。
最后,研究者还提出了对精确匹配率(Exact Match, EM)评估标准的改进,以更公平地评估LongRAG的性能。由于LongRAG的长检索上下文可能包含地面真实答案的别名或不同形式,因此研究者放宽了精确匹配的定义,将预测结果与真实答案之间的差异在五个token以内的情况也视为精确匹配。
总结
LongRAG框架的核心优势在于:
"长上下文检索器"就像带着重点笔记进考场,能快速定位相关信息,"长阅读器"则像学霸,能准确从长文本中提取关键答案。两者配合,让AI在回答复杂问题时更高效准确。
虽然LongRAG表现不错,但仍有提升空间:
-
检索器处理超长文本的能力可以进一步增强。
-
阅读器对长文本的理解还需优化。
总的来说,LongRAG为AI问答系统开辟了新方向。随着技术进步,它有望在处理复杂问题方面发挥更大作用。


路由v5.x(13)源码(5)- 实现 Switch)








【密钥生成介绍及算法规格】)





视频画面)

)

