
文章目录
- 创建Spring Boot项目
- 配置数据库连接信息
- 编写MyBatis Mapper接口
- 使用XML文件编写SQL映射
- 配置数据源切换
- 引入Druid依赖
- 配置Druid数据源
- 配置MyBatis支持事务管理
在使用Spring Boot创建新项目或新模块时,如果需要使用MyBatis来进行数据库操作,可以按照以下步骤来快速配置项目,并利用Druid数据源提高性能和管理数据库连接:
创建Spring Boot项目
- 打开Spring Initializr网站(start.spring.io)。
- 填写项目的基本信息,比如Group、Artifact、Name等。
- 在Dependencies中选择以下依赖:
- MySQL Driver:用于连接MySQL数据库的JDBC驱动程序。
- MyBatis Framework:MyBatis持久层框架。
创建spring boot新项目或者新模块需要用到mybatis的时候,需要在选择依赖关系的时候勾选MySQL Driver和Mybatis Framework两个依赖,创建项目即可
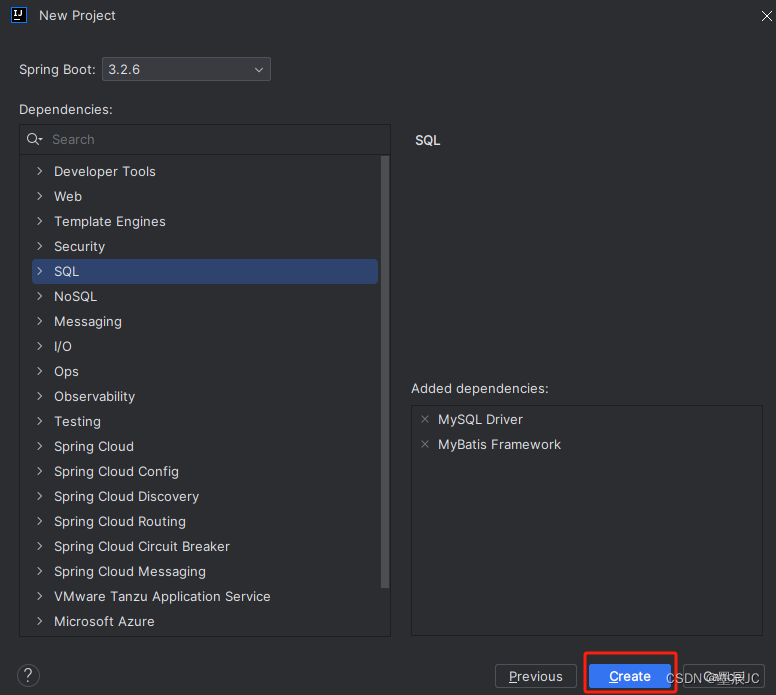
注意:如果在选择依赖时出现MyBatis Framework选项不可用,请切换Spring Boot版本到
>=3.2.0 and <3.3.0-M1之间。
-
MySQL Driver是一个用于连接Java应用程序和MySQL数据库的JDBC(Java Database Connectivity)驱动程序。该驱动程序负责在Java应用程序和MySQL数据库之间进行通信,允许应用程序执行SQL查询、更新、插入等数据库操作。
-
MyBatis是一个基于Java的持久层框架,它的主要作用是简化数据库操作,提供了一种更加直观和灵活的方式来执行SQL查询、插入、更新和删除等数据库操作。
配置数据库连接信息
在项目的application配置文件中加上数据库的配置信息(确保MySQL服务正常开启)
spring:datasource:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql:///ssm1username: 用户名password: 密码
最后无需像之前的spring项目加很多配置注解,只需要在访问数据库的数据层接口上方加上@Mapper注解,会自动配置映射文件
编写MyBatis Mapper接口
在MyBatis中,@Mapper注解主要用于标识接口,指示MyBatis框架将这个接口视为一个映射器(Mapper)。映射器是定义数据库操作的接口,而MyBatis会根据这些接口生成对应的实现。
@Mapper注解用于标识一个接口,告诉MyBatis框架这个接口是一个映射器接口,其中定义了与数据库相关的SQL操作。
在数据访问层定义Mapper接口,并使用@Mapper注解标识:
@Mapper
public interface BookDao {@Select("select * from tb1_book where id = #{id}")public Book getByID(Integer id);
}
使用XML文件编写SQL映射
除了在注解中写SQL,也可以使用XML文件来编写SQL映射:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.mybatis.example.BlogMapper"><select id="selectBlog" resultType="Blog">select * from Blog where id = #{id}</select>
</mapper>
<mapper>:这是MyBatis映射文件的根元素。
namespace属性:指定这个Mapper文件的命名空间,通常对应于一个Java接口的全限定名。在这个例子中,它是org.mybatis.example.BlogMapper。命名空间用于区分不同Mapper中的SQL语句,防止命名冲突。
<select>:定义一个SELECT查询。MyBatis中可以使用不同的标签来定义不同类型的SQL操作,例如<insert>、<update>、<delete>等。
id属性:指定这个SQL查询的唯一标识符。在这个例子中,id=“selectBlog”。在Java代码中,通过这个ID来引用这个SQL语句。
resultType属性:指定这个查询的返回结果类型。在这个例子中,返回的结果类型是Blog,即对应的Java类名。
配置数据源切换
如果需要切换到其他数据源(如阿里巴巴的Druid数据源),需要引入对应的Maven依赖,并在配置文件中进行设置。
- 数据源负责管理数据库连接的创建、分配、释放和维护。在应用程序需要与数据库进行交互时,数据源会提供一个可用的数据库连接,而不是每次都创建一个新的连接。这有助于减少连接的创建和销毁开销,提高性能。
引入Druid依赖
在pom.xml文件中添加Druid依赖:
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.16</version>
</dependency>
Druid是一个开源的高性能、可扩展的数据库连接池。它支持监控、防火墙、统计和其他丰富的功能。在Java项目中,Druid常用于管理数据库连接,提高性能,并提供了一些有用的监控和统计功能。
当在项目中引入了这个Maven依赖后,可以在项目中使用Druid作为数据源,提供数据库连接的管理功能。通常,你还需要在配置文件中进行相应的数据源配置,包括连接URL、用户名、密码等。
配置Druid数据源
在Spring Boot项目中,你可以在application.properties或application.yml文件中添加如下配置:
- YAML活YML文件写法
# 数据库连接配置
spring:datasource:url: jdbc:mysql://localhost:3306/your_databaseusername: your_usernamepassword: your_passworddriver-class-name: com.mysql.cj.jdbc.Driver# 配置使用Druid数据源datasource:type: com.alibaba.druid.pool.DruidDataSource# Druid连接池的一些配置initial-size: 5 # 初始连接池大小min-idle: 5 # 最小空闲连接数max-active: 20 # 最大活动连接数max-wait: 60000 # 获取连接的最大等待时间(毫秒)time-between-eviction-runs-millis: 60000 # 两次扫描连接池的时间间隔(毫秒)min-evictable-idle-time-millis: 300000 # 连接在池中最小生存的时间(毫秒)validation-query: SELECT 1 FROM DUAL # 用于校验连接的SQL查询语句test-while-idle: true # 空闲时是否进行连接的校验test-on-borrow: false # 取得连接时是否进行连接的校验test-on-return: false # 归还连接时是否进行连接的校验pool-prepared-statements: true # 是否缓存PreparedStatementmax-pool-prepared-statement-per-connection-size: 20 # 每个连接上缓存的PreparedStatement数量filters: stat,wall,log4j # 配置监控统计、防火墙、日志等功能的过滤器列表connection-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000 # 连接池的扩展属性
- properties文件写法
# 数据库连接配置
spring.datasource.url=jdbc:mysql://localhost:3306/your_database
spring.datasource.username=your_username
spring.datasource.password=your_password
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver# 配置使用Druid数据源
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource# Druid连接池的一些配置
spring.datasource.initial-size=5 # 初始连接池大小
spring.datasource.min-idle=5 # 最小空闲连接数
spring.datasource.max-active=20 # 最大活动连接数
spring.datasource.max-wait=60000 # 获取连接的最大等待时间(毫秒)
spring.datasource.time-between-eviction-runs-millis=60000 # 两次扫描连接池的时间间隔(毫秒)
spring.datasource.min-evictable-idle-time-millis=300000 # 连接在池中最小生存的时间(毫秒)
spring.datasource.validation-query=SELECT 1 FROM DUAL # 用于校验连接的SQL查询语句
spring.datasource.test-while-idle=true # 空闲时是否进行连接的校验
spring.datasource.test-on-borrow=false # 取得连接时是否进行连接的校验
spring.datasource.test-on-return=false # 归还连接时是否进行连接的校验
spring.datasource.pool-prepared-statements=true # 是否缓存PreparedStatement
spring.datasource.max-pool-prepared-statement-per-connection-size=20 # 每个连接上缓存的PreparedStatement数量
spring.datasource.filters=stat,wall,log4j # 配置监控统计、防火墙、日志等功能的过滤器列表
spring.datasource.connection-properties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000 # 连接池的扩展属性
最后创建对应的实体类和Mapper接口进行测试即可!
配置MyBatis支持事务管理
在SpringBoot的入口类中,使用@EnableTransactionManagement注解来启用事务管理器。
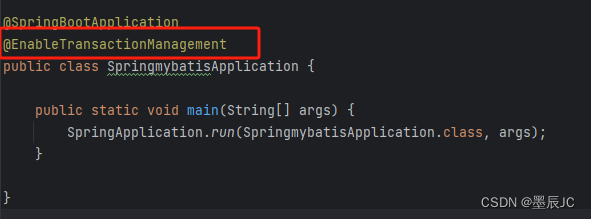
在需要回滚的业务逻辑层的Service类中,使用@Transactional注解来开启事务管理。这样,当方法执行时,如果发生异常,事务会自动回滚。


)








)
安装驱动(二百四十五))



)


,数据分析学习笔记)