从GAN到WGAN
文章目录
- 一、说明
- 二、Kullback-Leibler 和 Jensen-Shannon 背离
- 三、生成对抗网络 (GAN)
- 四、D 的最优值是多少?
- 五、什么是全局最优?
- 六、损失函数代表什么?
- 七、GAN中的问题
一、说明
生成对抗网络 (GAN) 在许多生成任务中显示出巨大的效果,以复制现实世界的丰富内容,如图像、人类语言和音乐。它的灵感来自博弈论:两个模型,一个生成器和一个批评家,在相互竞争的同时使彼此更强大。然而,训练GAN模型是相当具有挑战性的,因为人们面临着训练不稳定或收敛失败等问题。
在这里,我想解释一下生成对抗网络框架背后的数学原理,为什么很难训练,最后介绍一个旨在解决训练难点的GAN修改版本。
二、Kullback-Leibler 和 Jensen-Shannon 背离
在我们开始仔细研究 GAN 之前,让我们首先回顾一下用于量化两个概率分布之间相似性的两个指标。
- KL(Kullback-Leibler)散度衡量一个概率分布如何偏离第二个预期概率分布
.
D K L ( p ∥ q ) = ∫ x p ( x ) log p ( x ) q ( x ) d x D_{KL}(p \| q) = \int_x p(x) \log \frac{p(x)}{q(x)} dx DKL(p∥q)=∫xp(x)logq(x)p(x)dx
在以下情况下达到最小零点: p ( x ) = = q ( x ) p(x)==q(x) p(x)==q(x) 处处成立。
该公式表明 KL 散度是不对称的。当 p ( x ) p(x) p(x)接近零而 q ( x ) q(x) q(x)仍然显着大于零时, q q q的影响被忽略。当尝试测量两个同等重要的分布之间的相似性时,这可能会导致有问题的结果。
- Jensen-Shannon 散度是两个概率分布之间相似性的另一种度量,以.JS发散是对称的(耶!),而且更平滑。如果您有兴趣阅读有关 KL 背离和 JS 背离之间比较的更多信息,请查看这篇 Quora 帖子。
D J S ( p ∥ q ) = 1 2 D K L ( p ∥ p + q 2 ) + 1 2 D K L ( q ∥ p + q 2 ) D_{JS}(p \| q) = \frac{1}{2} D_{KL}(p \| \frac{p + q}{2}) + \frac{1}{2} D_{KL}(q \| \frac{p + q}{2}) DJS(p∥q)=21DKL(p∥2p+q)+21DKL(q∥2p+q)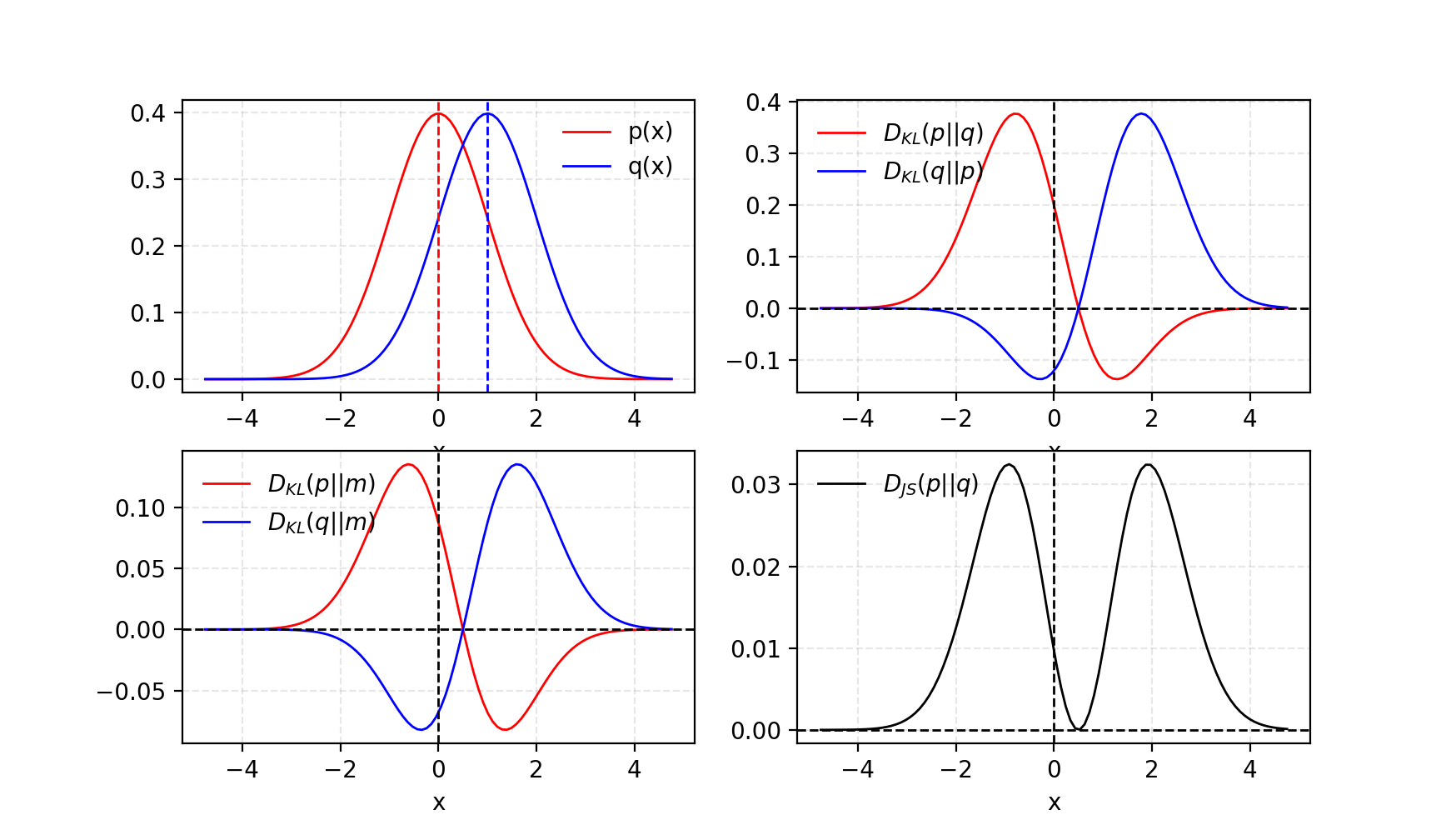
图 1.给定两个高斯分布,平均值=0 且 std=1 且平均值=1,标准度=1。两个分布的平均值标记为.吉隆坡背离是不对称的,但 JS 发散是对称的。
一些人认为(Huszar,2015)GANs取得巨大成功背后的一个原因是将损失函数从传统最大似然方法中的非对称KL散度转换为对称JS散度。我们将在下一节中详细讨论这一点。
三、生成对抗网络 (GAN)
GAN由两个模型组成:
- 鉴别器:估计给定样本来自真实数据集的概率。它作为评论家工作,并经过优化以区分假样品和真样品。
- 生成器: 输出给定噪声变量输入的合成样本 (带来潜在的产出多样性)。它被训练为捕获真实的数据分布,以便其生成样本尽可能真实,或者换句话说,可以欺骗鉴别器提供高概率。
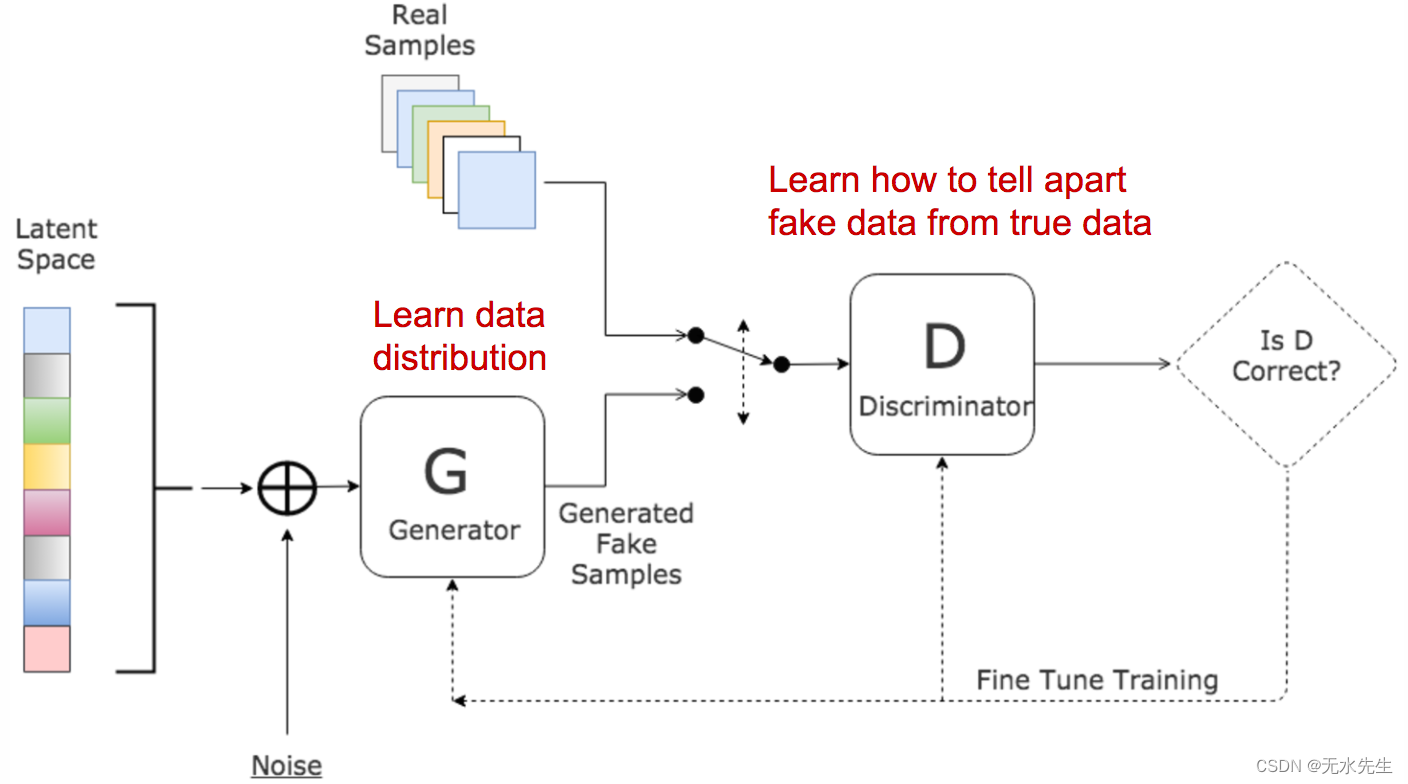
图 2.生成对抗网络的架构。(图片来源:www.kdnuggets.com/2017/01/generative-…-learning.html)
这两个模型在训练过程中相互竞争:生成器在努力欺骗鉴别者,而批评者模型
正在努力不被骗。两种模型之间这种有趣的零和博弈激励了两者改进其功能。
鉴于
| Symbol | Meaning | Notes |
|---|---|---|
| p z p_z pz | Data distribution over noise input z | Usually, just uniform. |
| p g p_g pg | The generator’s distribution over data x | |
| p r p_r pr | Data distribution over real sample x |
一方面,我们的目标是通过最大化 E x ∼ p r ( x ) [ log D ( x ) ] \mathbb{E}_{x \sim p_{r}(x)} [\log D(x)] Ex∼pr(x)[logD(x)] 来确保判别器 D D D 对真实数据做出准确的决策。另一方面,对于假样本 G ( z ) , z ∼ p z ( z ) G(z), z \sim p_z(z) G(z),z∼pz(z),判别器应该输出一个接近于零的概率 D ( G ( z ) ) D(G(z)) D(G(z)),这是通过最大化 E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \mathbb{E}_{z \sim p_{z}(z)} [\log (1 - D(G(z)))] Ez∼pz(z)[log(1−D(G(z)))]。
另一方面,生成器经过训练以增强 D D D 为虚假示例分配高概率的可能性,从而最小化 E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \mathbb{E}_{z \sim p_{z}(z)} [\log (1 - D(G(z)))] Ez∼pz(z)[log(1−D(G(z)))]。
当整合这两个方面时,D 和 G 进行极小极大博弈,其目标是优化后续损失函数:
min G max D L ( D , G ) = E x ∼ p r ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] = E x ∼ p r ( x ) [ log D ( x ) ] + E x ∼ p g ( x ) [ log ( 1 − D ( x ) ] \begin{aligned} \min_G \max_D L(D, G) & = \mathbb{E}_{x \sim p_{r}(x)} [\log D(x)] + \mathbb{E}_{z \sim p_z(z)} [\log(1 - D(G(z)))] \\ & = \mathbb{E}_{x \sim p_{r}(x)} [\log D(x)] + \mathbb{E}_{x \sim p_g(x)} [\log(1 - D(x)] \end{aligned} GminDmaxL(D,G)=Ex∼pr(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]=Ex∼pr(x)[logD(x)]+Ex∼pg(x)[log(1−D(x)]
E x ∼ p r ( x ) [ log D ( x ) ] \mathbb{E}_{x \sim p_{r}(x)} [\log D(x)] Ex∼pr(x)[logD(x)]在梯度下降更新期间对 G 没有影响。
四、D 的最优值是多少?
现在我们有一个明确定义的损失函数。让我们首先检查一下什么是D最佳值
.
L ( G , D ) = ∫ x ( p r ( x ) log ( D ( x ) ) + p g ( x ) log ( 1 − D ( x ) ) ) d x L(G, D) = \int_x \bigg( p_{r}(x) \log(D(x)) + p_g (x) \log(1 - D(x)) \bigg) dx L(G,D)=∫x(pr(x)log(D(x))+pg(x)log(1−D(x)))dx
由于我们感兴趣的是确定 D(x) 的最佳值以最大化 L(G,D),因此我们将贴上标签
x ~ = D ( x ) , A = p r ( x ) , B = p g ( x ) \tilde{x} = D(x), A=p_{r}(x), B=p_g(x) x~=D(x),A=pr(x),B=pg(x)
然后是积分内部的东西(我们可以安全地忽略积分,因为对所有可能的值进行采样)为:
f ( x ~ ) = A l o g x ~ + B l o g ( 1 − x ~ ) d f ( x ~ ) d x ~ = A 1 l n 10 1 x ~ − B 1 l n 10 1 1 − x ~ = 1 l n 10 ( A x ~ − B 1 − x ~ ) = 1 l n 10 A − ( A + B ) x ~ x ~ ( 1 − x ~ ) \begin{aligned} f(\tilde{x}) & = A log\tilde{x} + B log(1-\tilde{x}) \\ \frac{d f(\tilde{x})}{d \tilde{x}} & = A \frac{1}{ln10} \frac{1}{\tilde{x}} - B \frac{1}{ln10} \frac{1}{1 - \tilde{x}} \\ & = \frac{1}{ln10} (\frac{A}{\tilde{x}} - \frac{B}{1-\tilde{x}}) \\ & = \frac{1}{ln10} \frac{A - (A + B)\tilde{x}}{\tilde{x} (1 - \tilde{x})} \\ \end{aligned} f(x~)dx~df(x~)=Alogx~+Blog(1−x~)=Aln101x~1−Bln1011−x~1=ln101(x~A−1−x~B)=ln101x~(1−x~)A−(A+B)x~
因此,设置 d f ( x ~ ) d x ~ = 0 \frac{d f(\tilde{x})}{d \tilde{x}} = 0 dx~df(x~)=0,我们得到鉴别器的最佳值:
D ∗ ( x ) = x ~ ∗ = A A + B = p r ( x ) p r ( x ) + p g ( x ) ∈ [ 0 , 1 ] D^*(x) = \tilde{x}^* = \frac{A}{A + B} = \frac{p_{r}(x)}{p_{r}(x) + p_g(x)} \in [0, 1] D∗(x)=x~∗=A+BA=pr(x)+pg(x)pr(x)∈[0,1]
.
Once the generator is trained to its optimal,
p g p_g pg gets very close to p r p_r pr. When p g = p r p_g = p_{r} pg=pr, D ∗ ( x ) D^*(x) D∗(x) becomes 1/2.
.
一旦生成器被训练到最佳状态, p g p_g pg 非常接近 p r p_r pr。当 p g = p r p_g = p_{r} pg=pr时, D ∗ ( x ) D^*(x) D∗(x)变为1/2。
五、什么是全局最优?
当两者都G和D处于最佳值,我们有 p g = p r p_g = p_{r} pg=pr和 D ∗ ( x ) = 1 / 2 D^*(x)=1/2 D∗(x)=1/2。损失函数变为:
L ( G , D ∗ ) = ∫ x ( p r ( x ) log ( D ∗ ( x ) ) + p g ( x ) log ( 1 − D ∗ ( x ) ) ) d x = log 1 2 ∫ x p r ( x ) d x + log 1 2 ∫ x p g ( x ) d x = − 2 log 2 \begin{aligned} L(G, D^*) &= \int_x \bigg( p_{r}(x) \log(D^*(x)) + p_g (x) \log(1 - D^*(x)) \bigg) dx \\ &= \log \frac{1}{2} \int_x p_{r}(x) dx + \log \frac{1}{2} \int_x p_g(x) dx \\ &= -2\log2 \end{aligned} L(G,D∗)=∫x(pr(x)log(D∗(x))+pg(x)log(1−D∗(x)))dx=log21∫xpr(x)dx+log21∫xpg(x)dx=−2log2
六、损失函数代表什么?
根据上一节中列出的公式,JS 之间的背离 p g p_g pg 和 p r p_r pr,可以计算为:
D J S ( p r ∥ p g ) = 1 2 D K L ( p r ∣ ∣ p r + p g 2 ) + 1 2 D K L ( p g ∣ ∣ p r + p g 2 ) = 1 2 ( log 2 + ∫ x p r ( x ) log p r ( x ) p r + p g ( x ) d x ) + 1 2 ( log 2 + ∫ x p g ( x ) log p g ( x ) p r + p g ( x ) d x ) = 1 2 ( log 4 + L ( G , D ∗ ) ) \begin{aligned} D_{JS}(p_{r} \| p_g) =& \frac{1}{2} D_{KL}(p_{r} || \frac{p_{r} + p_g}{2}) + \frac{1}{2} D_{KL}(p_{g} || \frac{p_{r} + p_g}{2}) \\ =& \frac{1}{2} \bigg( \log2 + \int_x p_{r}(x) \log \frac{p_{r}(x)}{p_{r} + p_g(x)} dx \bigg) + \\& \frac{1}{2} \bigg( \log2 + \int_x p_g(x) \log \frac{p_g(x)}{p_{r} + p_g(x)} dx \bigg) \\ =& \frac{1}{2} \bigg( \log4 + L(G, D^*) \bigg) \end{aligned} DJS(pr∥pg)===21DKL(pr∣∣2pr+pg)+21DKL(pg∣∣2pr+pg)21(log2+∫xpr(x)logpr+pg(x)pr(x)dx)+21(log2+∫xpg(x)logpr+pg(x)pg(x)dx)21(log4+L(G,D∗))
因此 L ( G , D ∗ ) = 2 D J S ( p r ∥ p g ) − 2 log 2 L(G, D^*) = 2D_{JS}(p_{r} \| p_g) - 2\log2 L(G,D∗)=2DJS(pr∥pg)−2log2
当判别器最优时,生成对抗网络 (GAN) 的损失函数使用 Jensen-Shannon 散度来衡量生成的数据分布 p g p_g pg 与真实样本分布 p r p_r pr 之间的相似性。最优生成器 G ∗ G^* G∗ 复制真实数据分布,导致最小损失 L ( G ∗ , D ∗ ) = − 2 log 2 L(G^*, D^*) = -2\log2 L(G∗,D∗)=−2log2,与前面的方程一致。
GAN 的其他变体:存在许多 GAN 变体,专为各种环境或特定任务而定制。例如,在半监督学习中,一种方法涉及修改鉴别器以生成实际的类标签 1 、 … 、 K − 1 1、\ldots、K-1 1、…、K−1,以及单个假类标签 K K K。生成器的目标是欺骗鉴别器分配小于 K K K 的分类标签。
七、GAN中的问题
(见系列下文)…


,数据分析学习笔记)

)
---Java版)








priority_queue的详细用法及仿函数实现)
)
模块实现)
——联合查询)

)