文章目录
- 前言
- 八、Jmeter常用逻辑控制器
- 8.1 如果(if)控制器
- 8.2 循环控制器
- 8.3 ForEach控制器
- 九、Jmeter关联
- 9.1 正则表达式提取器
- 9.2 xpath提取器
- 9.3 JSON提取器
- 十、跨越线程组传值
- 10.1 高并发
- 10.2 高频率
- 10.3 分布式
- 总结
前言
八、Jmeter常用逻辑控制器
通过参数化可以实现单个接口的功能测试,而接口测试过程中,除了单个接口的功能测试之外,还会测试 接口业务实现,所谓业务,就是一套完整的业务逻辑或流程,这就必须要使用到逻辑控制和关联。
8.1 如果(if)控制器
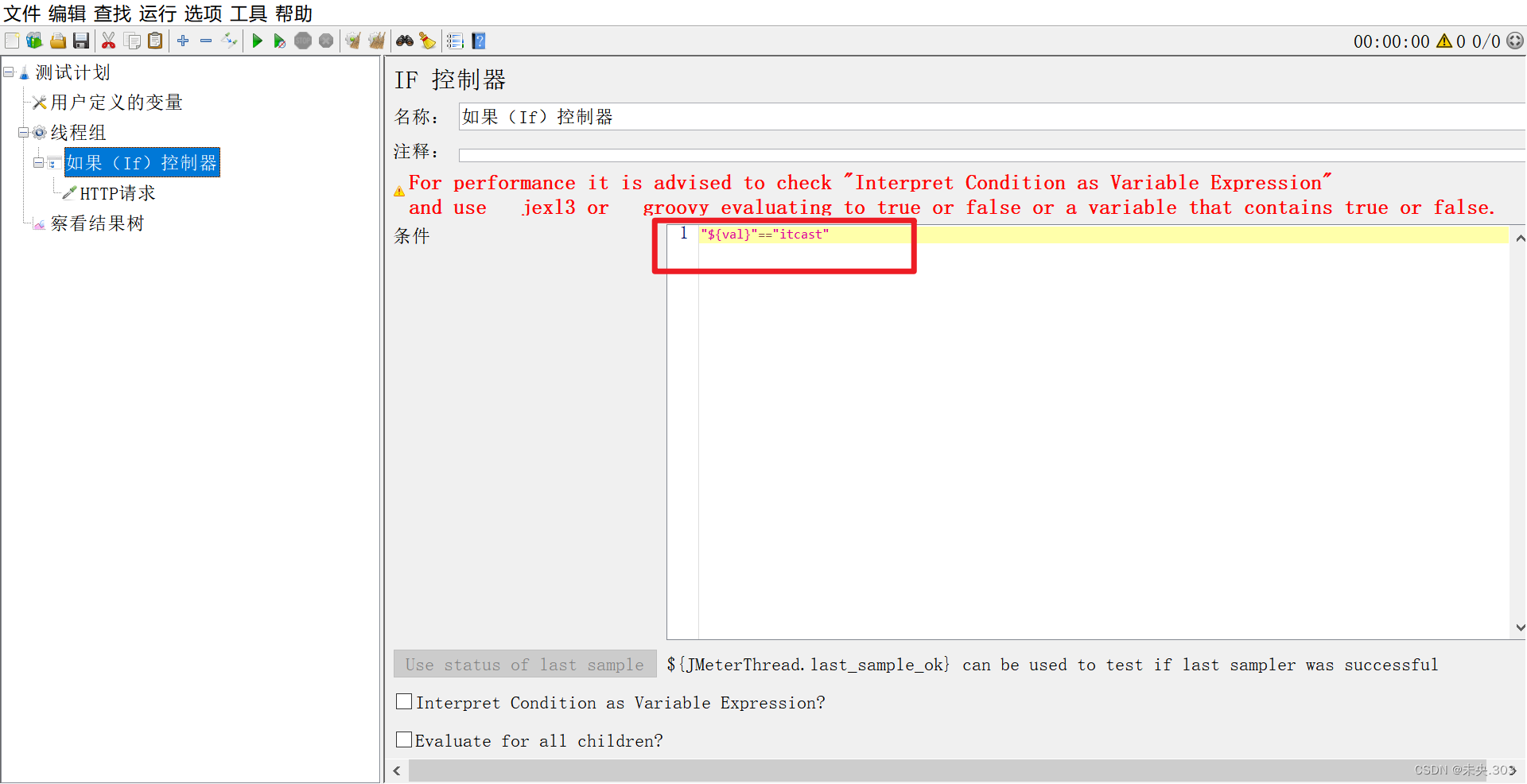
(1)作用:
if控制器用来控制它下面的测试元素是否运行。
(2)位置:
测试计划->线程组->逻辑控制器->IF控制器。
图示说明:
举实例说明:
需求:测试计划中定义一个 http 请求访问百度官网,但是该请求不是无条件执行的,声明一个用户定义的变量,如果变量是 itcast 才执行,否则就不执行。实现步骤:1、搭框架,测试计划,线程组,结果树,声明一个用户定义的变量2、核心:添加 if 控制器,子级添加取样器 (和之前实现不同,控制器和取样器存在父子级关系)步骤一:声明一个用户定义的变量
步骤二:添加 if 控制器,子级添加取样器


8.2 循环控制器
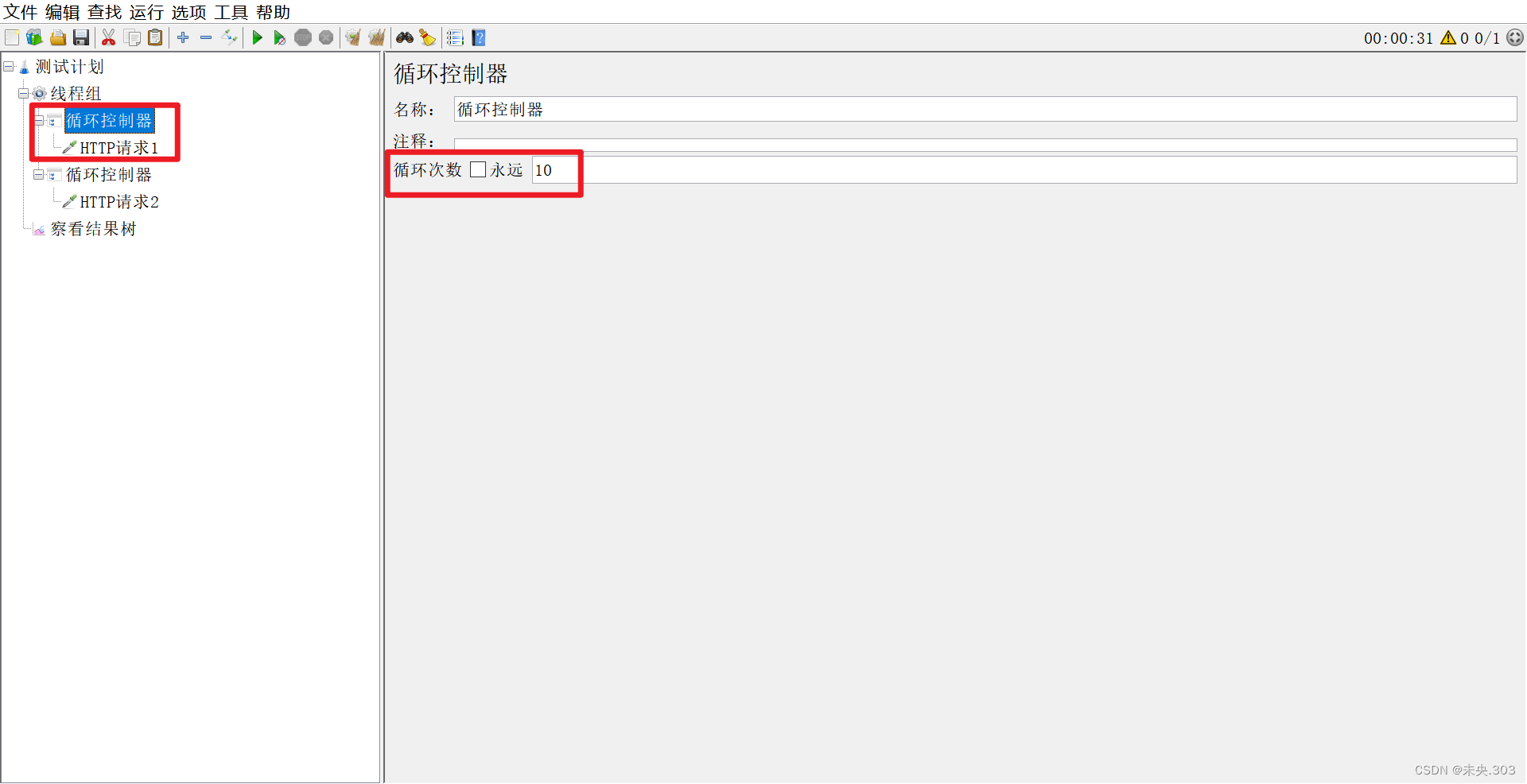
(1)作用:
控制下面的测试元素循环执行一次或多次
(2)位置:
测试计划->线程组->逻辑控制器->循环控制器
图示说明:
举实例说明:
需求:循环访问学生管理系统10次实现步骤:1、搭框架,测试计划,线程组,结果树2、添加循环控制器,子级添加取样器 (和之前实现不同,控制器和取样器存在父子级关系)
步骤一:添加循环控制器


8.3 ForEach控制器
(1)作用:
一般和用户自定义变量或者正则表达式提取器一起使用,读取返回结果中一系列相关的变量值。该控制器下的所有取样器都会被执行一次或多次,每次读取不同的变量值
(2)位置:
测试计划->线程组->逻辑控制器->ForEach控制器
(3)图示说明:
(4)参数说明:
举实例说明:
需求:有一组关键字 [hello,python,测试] (使用用户定义的变量存储)要依次取出,并在百度搜索实现步骤:1、搭框架,测试计划,线程组,结果树,声明一个用户定义的变量,存储一组数据2、添加 forEach 控制器,子级添加取样器 (和之前实现不同,控制器和取样器存在父子级关系)3、百度搜索关键字步骤一:声明一个用户定义的变量,存储一组数据
步骤二:添加 forEach 控制器
步骤三:在请求中使用,在百度搜索关键字
第一个变量Java:






九、Jmeter关联
(1)定义:
当请求之间有依赖关系,比如一个请求的入参是另一个请求返回的数据,这时候就需要用到关联处理
(2)常用的关联方法:
- 正则表达式提取器
- XPath提取器
- JSON提取器
- JMeter属性
9.1 正则表达式提取器
(1)使用场景:
任意格式的响应数据,都可以使用正则表达式提取器进行提取
(2)使用步骤:
- 添加线程组
- 添加HTTP请求1
- 在后置处理器添加正则表达式提取器设置参数
- 添加HTTP请求2,引用正则表达式中的引用名称。如:用${title}引用它
- 添加查看结果树
知识点解惑:
正则表达式:就是一个公式,或者一套规则,使用这套规则可以从任意字符串中提取出想要的数据内容。
公式格式:左边界(匹配符号)右边界:可以提取出想要获取的数据内容
.:是通配符,可以代表任意字符(除换行回车)
*: 代表前面的字符出现0次或者多次
.*匹配规则:找到左边界值后,往右查找有边界,找到最后面的右边界,中间的所有数据都被记录下来
?: 代表非贪婪匹配,找到左边界后,往右查找匹配右边界,只要有匹配的右边界就停止继续查找;再次查找左边界和右边界
公式格式:左边界(.*?)右边界
(1)图示说明:
(2)参数说明:


举实例说明:
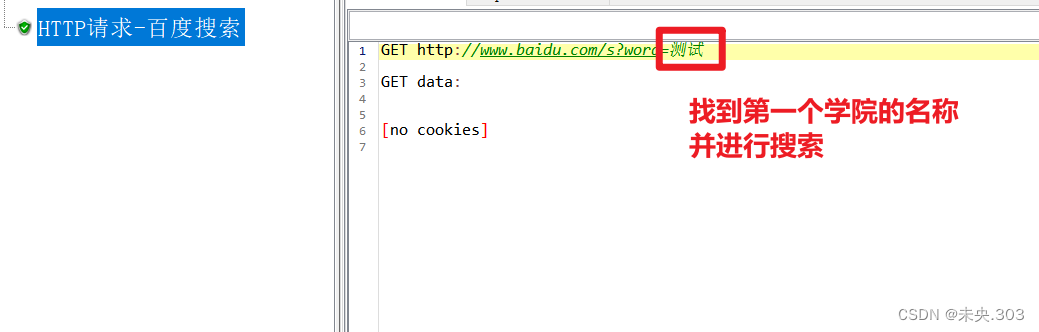
需求:两个请求,请时求A查询所有学院信息,请求B访问百度,从请求A中提取出第一个学院的学院名称, 把名称放在百度上搜索实现步骤:1、搭框架,编写两个请求,查询所有学院信息 + 百度搜索2、核心:从学院查询中提取学院名称3、传递给百度,调用格式: ${变量名}
步骤一:搭框架,编写两个请求,查询所有学院信息 + 百度搜索
步骤二:从学院查询中提取学院名称
步骤三:传递给百度,调用格式: ${变量名}
步骤四:查看结果树



9.2 xpath提取器
(1)使用场景:
针对HTML格式的响应结果数据进行提取。
(2)使用步骤:
- 添加线程组
- 添加HTTP请求1
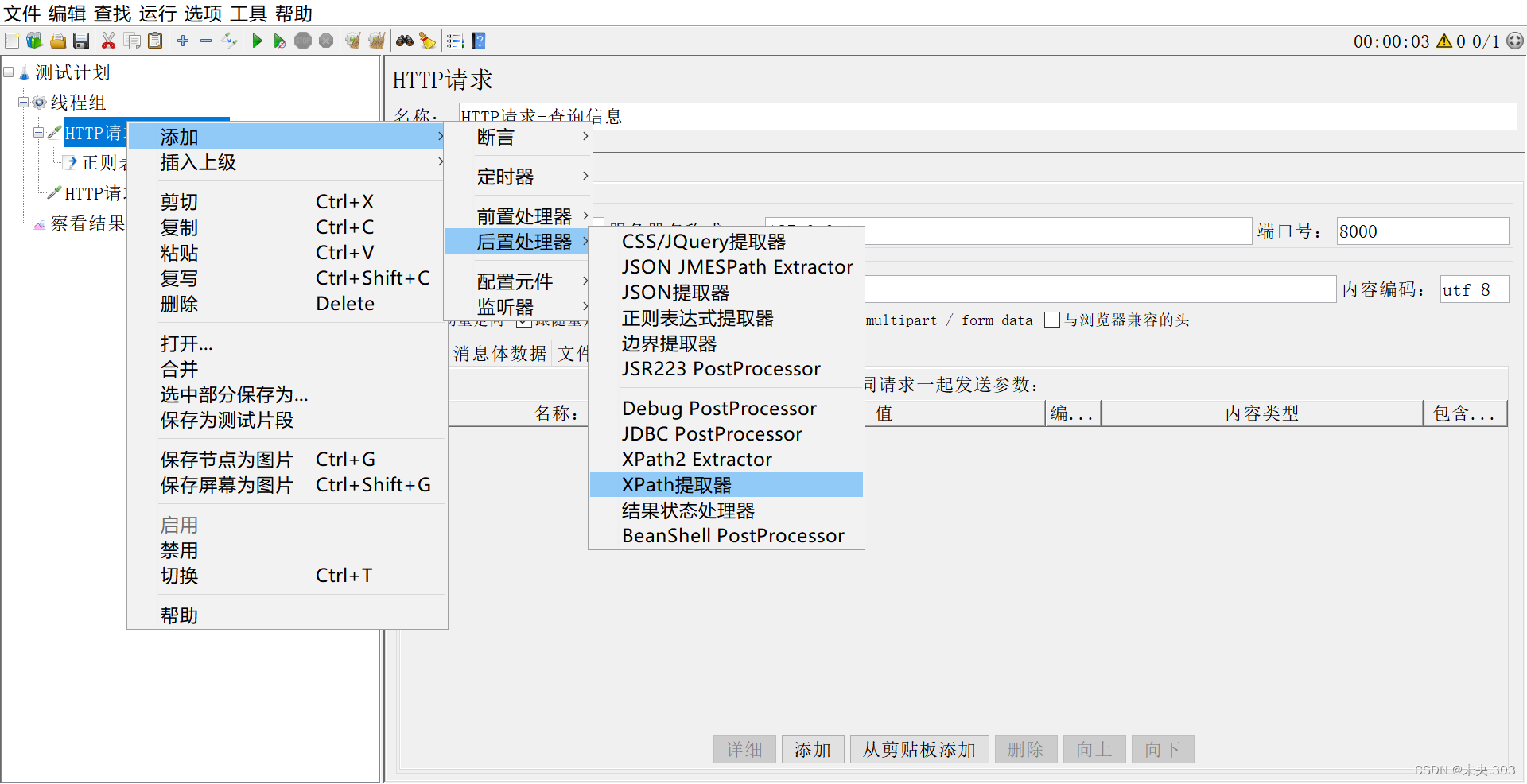
- 在后置处理器添加xpath提取器设置参数
- 添加HTTP请求2,引用正则表达式中的引用名称。如:用${title}引用它
- 添加查看结果树
(1)图示说明:
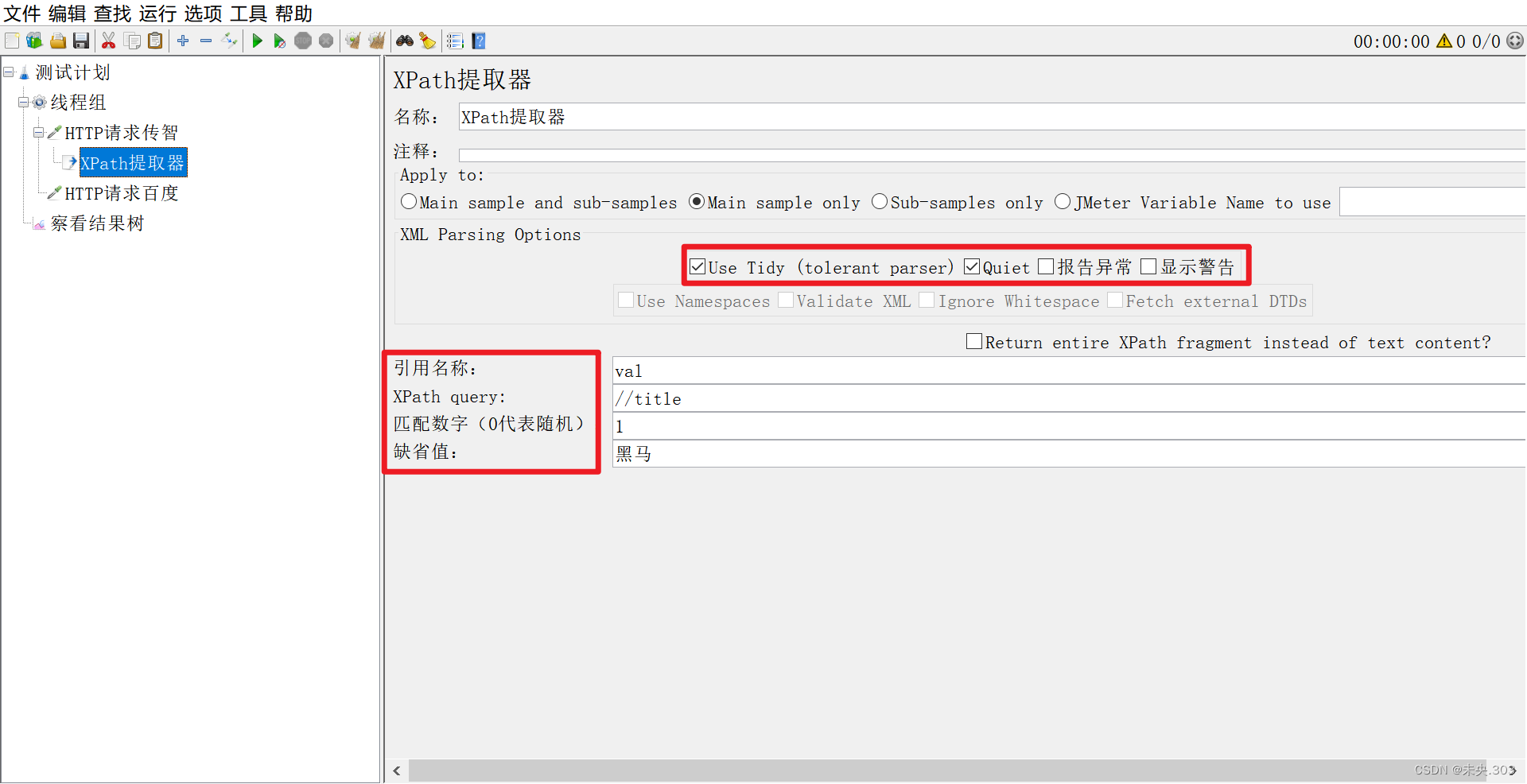
(2)参数说明:
- Use Tidy (tolerant parser):当需要处理的页面是HTML格式时,必须选中该选项;当需要处理的页面是XML或XHTML格式时,取消选中该选项
- 引用名称:存放提取出的值的参数名称
- XPath Query:用于提取值的XPath表达式
- 匹配数字:如果XPath路径查询出许多结果,则可以选择提取哪个
- 0:表示随机,-1:表示提取所有结果,1表示第一个值
- 缺省值:参数的默认值
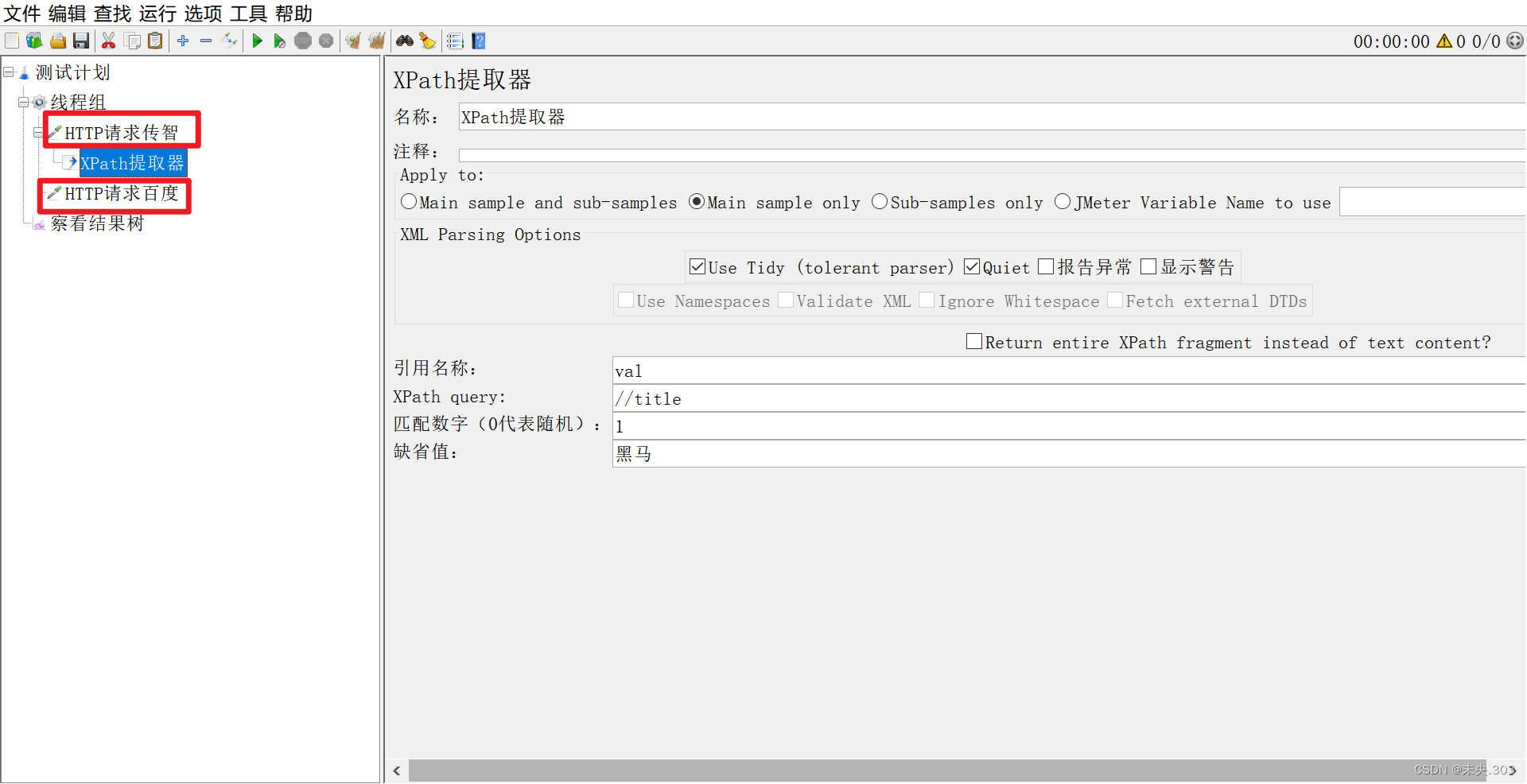
举实例说明:
需求:两个http请求,请求A访问传智播客官网,请求B访问百度 ,请求A将传智播客官网源码中的 title 标 签的值取出,传递给请求B,在请求B中作为关键字搜索这个 title 值实现步骤:1、搭框架,编写两个请求,传智播客 + 百度搜索2、核心: 取出传智播客页面源码的 title 值3、传递给百度:${变量名} 的方式传值
步骤一:搭框架,编写两个请求,传智播客 + 百度搜索
步骤二:核心: 取出传智播客页面源码的 title 值
步骤三:传递给百度,调用格式: ${变量名}


9.3 JSON提取器
(1)使用场景:
针对JSON格式的响应数据进行提取
(2)使用步骤:
- 添加线程组
- 添加HTTP请求1
- 在后置处理器中选择添加JSON提取器设置参数
- 添加HTTP请求2,引用正则表达式中的引用名称。如:用${title}引用它
- 添加查看结果树
(1)图示说明:
(2)参数说明:
- Names of created variables:存放提取出的值的参数名称。如:cit
- JSON Path expressions:用于提取值的JSON路径表达式
- Match No:0表示随机;-1表示提取的所有结果,1表示第一个值
- Default Values:参数的默认值



防重指令)


与模块(module)的概念 以及 import 问题)
)
)
)

 Canndy边缘检测)


)


)

)


